







原文:Deeper Text Understanding for IR with Contextual Neural Language Modeling
链接:
https://arxiv.org/pdf/1905.09217.pdfarxiv.org针对的问题
bert的强文本理解能力能否应用到ir领域,能否带来ir领域性能的提升
结论
- 使用ir领域数据对bert进行fine-tuning,性能超过几个强baseline
- 长的,句子级别的query,检索性能,比短的,词级别的query,检索性能更好
- stopwords和标点符号,在现有的ir算法中被忽略,然而在文中基于bert的方法中有重要作用
- 在有标注数据非常稀少的前提下,使用领域内的知识,search log, 进行pretrain能够提升整体性能
模型
模型本身并不复杂,就是将query+doc喂bert进行fine-tuning做文本分类,但是会有一些细节问题:
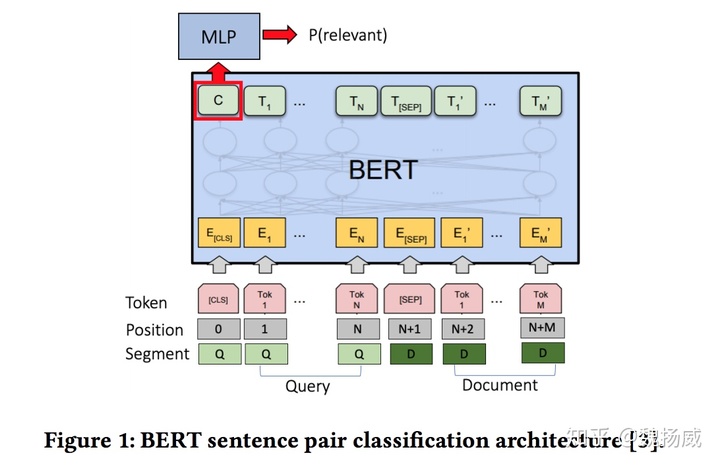
- 长文本:将长文本拆成overlap的passages分别处理,具体做法是150words长度的滑动窗口,每次滑动步长75words. 最终的doc得分,分别取first passage (BERT-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4148
4148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









