







AWS SAA-C02 Study Guide
This study guide will help you pass the newer AWS Certified Solutions Architect - Associate exam. Ideally, you should reference this guide while working through the following material:
- Stephane Maarek’s Ultimate AWS Certified Solutions Architect Associate 2020 course or A Cloud Guru’s AWS Certified Solutions Architect Associate 2020 course
- The FAQs for the most critical services, included in the recommended reading list below
- Tutorials Dojo’s AWS Certified Solutions Architect Associate Practice Exams
- Andrew Brown’s AWS Certified Solutions Architect - Associate 2020 (PASS THE EXAM!) | Ad-Free Course
Notes:
If at any point you find yourself feeling uncertain of your progress and in need of more time, you can postpone your AWS exam date. Be sure to also keep up with the ongoing discussions in r/AWSCertifications as you will find relevant exam tips, studying material, and advice from other exam takers. Before experimenting with AWS, it’s very important to be sure that you know what is free and what isn’t. Relevant Free Tier FAQs can be found here. Finally, Udemy often has their courses go on sale from time to time. It might be worth waiting to purchase either the Tutorial Dojo practice exam or Stephane Maarek’s course depending on how urgently you need the content.
Table of Contents
Introduction
The official AWS Solutions Architect - Associate (SAA-C02) exam guide
Exam Content Breakdown:

Domain 1: Design Resilient Architectures
1.1 - Design a multi-tier architecture solution
1.2 - Design highly available and/or fault-tolerant architectures
1.3 - Design decoupling mechanisms using AWS services
1.4 - Choose appropriate resilient storage
Domain 2: Design High-Performing Architectures
2.1 - Identify elastic and scalable compute solutions for a workload
2.2 - Select high-performing and scalable storage solutions for a workload
2.3 - Select high-performing networking solutions for a workload
2.4 - Choose high-performing database solutions for a workload
Domain 3: Design Secure Applications and Architectures
3.1 - Design secure access to AWS resources
3.2 - Design secure application tiers
3.3 - Select appropriate data security options
Domain 4: Design Cost-Optimized Architectures
4.1 - Identify cost-effective storage solutions
4.2 - Identify cost-effective compute and database services
4.3 - Design cost-optimized network architectures
Recommended Reading:
You can cover a lot of ground by skimming over what you already know or what you can infer to be true. In particular, read the first sentence of each paragraph and if you have no uncertainty about what is being said in that sentence, move on to the first sentence of the next paragraph. Take notes whenever necessary.
Identity Access Management (IAM)
IAM Simplified:
IAM offers a centralized hub of control within AWS and integrates with all other AWS Services. IAM comes with the ability to share access at various levels of permission and it supports the ability to use identity federation (the process of delegating authentication to a trusted external party like Facebook or Google) for temporary or limited access. IAM comes with MFA support and allows you to set up custom password rotation policy across your entire organization.
It is also PCI DSS compliant i.e. payment card industry data security standard. (passes government mandated credit card security regulations).
IAM Entities:
Users - any individual end user such as an employee, system architect, CTO, etc.
Groups - any collection of similar people with shared permissions such as system administrators, HR employees, finance teams, etc. Each user within their specified group will inherit the permissions set for the group.
Roles - any software service that needs to be granted permissions to do its job, e.g- AWS Lambda needing write permissions to S3 or a fleet of EC2 instances needing read permissions from a RDS MySQL database.
Policies - the documented rule sets that are applied to grant or limit access. In order for users, groups, or roles to properly set permissions, they use policies. Policies are written in JSON and you can either use custom policies for your specific needs or use the default policies set by AWS.

IAM Policies are separated from the other entities above because they are not an IAM Identity. Instead, they are attached to IAM Identities so that the IAM Identity in question can perform its necessary function.
IAM Key Details:
-
IAM is a global AWS services that is not limited by regions. Any user, group, role or policy is accessible globally.
-
The root account with complete admin access is the account used to sign up for AWS. Therefore, the email address used to create the AWS account for use should probably be the official company email address.
-
New users have no permissions when their accounts are first created. This is a secure way of delegating access as permissions must be intentionally granted.
-
When joining the AWS ecosystem for the first time, new users are supplied an access key ID and a secret access key ID when you grant them programmatic access. These are created just once specifically for the new user to join, so if they are lost simply generate a new access key ID and a new secret access key ID. Access keys are only used for the AWS CLI and SDK so you cannot use them to access the console.
-
When creating your AWS account, you may have an existing identity provider internal to your company that offers Single Sign On (SSO). If this is the case, it is useful, efficient, and entirely possible to reuse your existing identities on AWS. To do this, you let an IAM role be assumed by one of the Active Directories. This is because the IAM ID Federation feature allows an external service to have the ability to assume an IAM role.
-
IAM Roles can be assigned to a service, such as an EC2 instance, prior to its first use/creation or after its been in used/created. You can change permissions as many times as you need. This can all be done by using both the AWS console and the AWS command line tools.
-
You cannot nest IAM Groups. Individual IAM users can belong to multiple groups, but creating subgroups so that one IAM Group is embedded inside of another IAM Group is not possible.
-
With IAM Policies, you can easily add tags that help define which resources are accessible by whom. These tags are then used to control access via a particular IAM policy. For example, production and development EC2 instances might be tagged as such. This would ensure that people who should only be able to access development instances cannot access production instances.
Priority Levels in IAM:
-
Explicit Deny: Denies access to a particular resource and this ruling cannot be overruled.
-
Explicit Allow: Allows access to a particular resource so long as there is not an associated Explicit Deny.
-
Default Deny (or Implicit Deny): IAM identities start off with no resource access. Access instead must be granted.
Simple Storage Service (S3)
S3 Simplified:
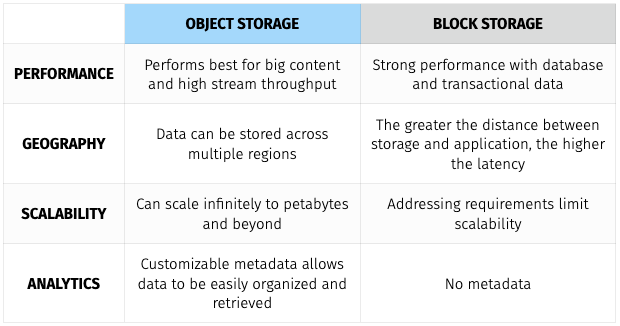
S3 provides developers and IT teams with secure, durable, and highly-scalable object storage. Object storage, as opposed to block storage, is a general term that refers to data composed of three things:
1.) the data that you want to store
2.) an expandable amount of metadata
3.) a unique identifier so that the data can be retrieved
This makes it a perfect candidate to host files or directories and a poor candidate to host databases or operating systems. The following table highlights key differences between object and block storage:
Data uploaded into S3 is spread across multiple files and facilities. The files uploaded into S3 have an upper-bound of 5TB per file and the number of files that can be uploaded is virtually limitless. S3 buckets, which contain all files, are named in a universal namespace so uniqueness is required. All successful uploads will return an HTTP 200 response.
S3 Key Details:
-
Objects (regular files or directories) are stored in S3 with a key, value, version ID, and metadata. They can also contain torrents and sub resources for access control lists which are basically permissions for the object itself.
-
The data consistency model for S3 ensures immediate read access for new objects after the initial PUT requests. These new objects are introduced into AWS for the first time and thus do not need to be updated anywhere so they are available immediately.
-
The data consistency model for S3 ensures eventual read consistency for PUTS and DELETES of already existing objects. This is because the change takes a little time to propagate across the entire Amazon network.
-
Because of the eventual consistency model when updating existing objects in S3, those updates might not be immediately reflected. As object updates are made to the same key, an older version of the object might be provided back to the user when the next read request is made.
-
Amazon guarantees 99.999999999% (or 11 9s) durability for all S3 storage classes except its Reduced Redundancy Storage class.
-
S3 comes with the following main features:
1.) tiered storage and pricing variability
2.) lifecycle management to expire older content
3.) versioning for version control
4.) encryption for privacy
5.) MFA deletes to prevent accidental or malicious removal of content
6.) access control lists & bucket policies to secure the data
-
S3 charges by:
1.) storage size
2.) number of requests
3.) storage management pricing (known as tiers)
4.) data transfer pricing (objects leaving/entering AWS via the internet)
5.) transfer acceleration (an optional speed increase for moving objects via Cloudfront)
6.) cross region replication (more HA than offered by default
-
Bucket policies secure data at the bucket level while access control lists secure data at the more granular object level.
-
By default, all newly created buckets are private.
-
S3 can be configured to create access logs which can be shipped into another bucket in the current account or even a separate account all together. This makes it easy to monitor who accesses what inside S3.
-
There are 3 different ways to share S3 buckets across AWS accounts:
1.) For programmatic access only, use IAM & Bucket Policies to share entire buckets
2.) For programmatic access only, use ACLs & Bucket Policies to share objects
3.) For access via the console & the terminal, use cross-account IAM roles
-
S3 is a great candidate for static website hosting. When you enable static website hosting for S3 you need both an index.html file and an error.html file. Static website hosting creates a website endpoint that can be accessed via the internet.
-
When you upload new files and have versioning enabled, they will not inherit the properties of the previous version.
S3 Storage Classes:
S3 Standard - 99.99% availability and 11 9s durability. Data in this class is stored redundantly across multiple devices in multiple facilities and is designed to withstand the failure of 2 concurrent data centers.
S3 Infrequently Accessed (IA) - For data that is needed less often, but when it is needed the data should be available quickly. The storage fee is cheaper, but you are charged for retrieval.
S3 One Zone Infrequently Accessed (an improvement of the legacy RRS / Reduced Redundancy Storage) - For when you want the lower costs of IA, but do not require high availability. This is even cheaper because of the lack of HA.
S3 Intelligent Tiering - Uses built-in ML/AI to determine the most cost-effective storage class and then automatically moves your data to the appropriate tier. It does this without operational overhead or performance impact.
S3 Glacier - low-cost storage class for data archiving. This class is for pure storage purposes where retrieval isn’t needed often at all. Retrieval times range from minutes to hours. There are differing retrieval methods depending on how acceptable the default retrieval times are for you:
Expedited: 1 - 5 minutes, but this option is the most expensive.
Standard: 3 - 5 hours to restore.
Bulk: 5 - 12 hours. This option has the lowest cost and is good for a large set of data.
The Expedited duration listed above could possibly be longer during rare situations of unusually high demand across all of AWS. If it is absolutely critical to have quick access to your Glacier data under all circumstances, you must purchase Provisioned Capacity. Provisioned Capacity guarentees that Expedited retrievals always work within the time constraints of 1 to 5 minutes.
S3 Deep Glacier - The lowest cost S3 storage where retrieval can take 12 hours.

S3 Encryption:
S3 data can be encrypted both in transit and at rest.
Encryption In Transit: When the traffic passing between one endpoint to another is indecipherable. Anyone eavesdropping between server A and server B won’t be able to make sense of the information passing by. Encryption in transit for S3 is always achieved by SSL/TLS.
Encryption At Rest: When the immobile data sitting inside S3 is encrypted. If someone breaks into a server, they still won’t be able to access encrypted info within that server. Encryption at rest can be done either on the server-side or the client-side. The server-side is when S3 encrypts your data as it is being written to disk and decrypts it when you access it. The client-side is when you personally encrypt the object on your own and then upload it into S3 afterwards.
You can encrypted on the AWS supported server-side in the following ways:
- S3 Managed Keys / SSE - S3 (server side encryption S3 ) - when Amazon manages the encryption and decryption keys for you automatically. In this scenario, you concede a little control to Amazon in exchange for ease of use.
- AWS Key Management Service / SSE - KMS - when Amazon and you both manage the encryption and decryption keys together.
- Server Side Encryption w/ customer provided keys / SSE - C - when I give Amazon my own keys that I manage. In this scenario, you concede ease of use in exchange for more control.
S3 Versioning:
- When versioning is enabled, S3 stores all versions of an object including all writes and even deletes.
- It is a great feature for implicitly backing up content and for easy rollbacks in case of human error.
- It can be thought of as analogous to Git.
- Once versioning is enabled on a bucket, it cannot be disabled - only suspended.
- Versioning integrates w/ lifecycle rules so you can set rules to expire or migrate data based on their version.
- Versioning also has MFA delete capability to provide an additional layer of security.
S3 Lifecycle Management:
- Automates the moving of objects between the different storage tiers.
- Can be used in conjunction with versioning.
- Lifecycle rules can be applied to both current and previous versions of an object.
S3 Cross Region Replication:
- Cross region replication only work if versioning is enabled.
- When cross region replication is enabled, no pre-existing data is transferred. Only new uploads into the original bucket are replicated. All subsequent updates are replicated.
- When you replicate the contents of one bucket to another, you can actually change the ownership of the content if you want. You can also change the storage tier of the new bucket with the replicated content.
- When files are deleted in the original bucket (via a delete marker as versioning prevents true deletions), those deletes are not replicated.
- Cross Region Replication Overview
- What is and isn’t replicated such as encrypted objects, deletes, items in glacier, etc.
S3 Transfer Acceleration:
- Transfer acceleration makes use of the CloudFront network by sending or receiving data at CDN points of presence (called edge locations) rather than slower uploads or downloads at the origin.
- This is accomplished by uploading to a distinct URL for the edge location instead of the bucket itself. This is then transferred over the AWS network backbone at a much faster speed.
- You can test transfer acceleration speed directly in comparison to regular uploads.
S3 Event Notications:
The Amazon S3 notification feature enables you to receive and send notifications when certain events happen in your bucket. To enable notifications, you must first configure the events you want Amazon S3 to publish (new object added, old object deleted, etc.) and the destinations where you want Amazon S3 to send the event notifications. Amazon S3 supports the following destinations where it can publish events:
- Amazon Simple Notification Service (Amazon SNS) - A web service that coordinates and manages the delivery or sending of messages to subscribing endpoints or clients.
- Amazon Simple Queue Service (Amazon SQS) - SQS offers reliable and scalable hosted queues for storing messages as they travel between computers.
- AWS Lambda - AWS Lambda is a compute service where you can upload your code and the service can run the code on your behalf using the AWS infrastructure. You package up and upload your custom code to AWS Lambda when you create a Lambda function. The S3 event triggering the Lambda function also can serve as the code’s input.
S3 and ElasticSearch:
- If you are using S3 to store log files, ElasticSearch provides full search capabilities for logs and can be used to search through data stored in an S3 bucket.
- You can integrate your ElasticSearch domain with S3 and Lambda. In this setup, any new logs received by S3 will trigger an event notification to Lambda, which in turn will then run your application code on the new log data. After your code finishes processing, the data will be streamed into your ElasticSearch domain and be available for observation.
Maximizing S3 Read/Write Performance:
- If the request rate for reading and writing objects to S3 is extremely high, you can use sequential date-based naming for your prefixes to improve performance. Earlier versions of the AWS Docs also suggested to use hash keys or random strings to prefix the object’s name. In such cases, the partitions used to store the objects will be better distributed and therefore will allow better read/write performance on your objects.
- If your S3 data is receiving a high number of GET requests from users, you should consider using Amazon CloudFront for performance optimization. By integrating CloudFront with S3, you can distribute content via CloudFront’s cache to your users for lower latency and a higher data transfer rate. This also has the added bonus of sending fewer direct requests to S3 which will reduce costs. For example, suppose that you have a few objects that are very popular. CloudFront fetches those objects from S3 and caches them. CloudFront can then serve future requests for the objects from its cache, reducing the total number of GET requests it sends to Amazon S3.
- More information on how to ensure high performance in S3
S3 Server Access Logging:
- Server access logging provides detailed records for the requests that are made to a bucket. Server access logs are useful for many applications. For example, access log information can be useful in security and access audits. It can also help you learn about your customer base and better understand your Amazon S3 bill.
- By default, logging is disabled. When logging is enabled, logs are saved to a bucket in the same AWS Region as the source bucket.
- Each access log record provides details about a single access request, such as the requester, bucket name, request time, request action, response status, and an error code, if relevant.
- It works in the following way:
- S3 periodically collecting access log records of the bucket you want to monitor
- S3 then consolidates those records into log files
- S3 finally uploads the log files to your secondary monitoring bucket as log objects
S3 Multipart Upload:
- Multipart upload allows you to upload a single object as a set of parts. Each part is a contiguous portion of the object’s data. You can upload these object parts independently and in any order.
- Multipart uploads are recommended for files over 100 MB and is the only way to upload files over 5 GB. It achieves functionality by uploading your data in parallel to boost efficiency.
- If transmission of any part fails, you can retransmit that part without affecting other parts. After all parts of your object are uploaded, Amazon S3 assembles these parts and creates the object.
- Possible reasons for why you would want to use Multipart upload:
- Multipart upload delivers the ability to begin an upload before you know the final object size.
- Multipart upload delivers improved throughput.
- Multipart upload delivers the ability to pause and resume object uploads.
- Multipart upload delivers quick recovery from network issues.
- You can use an AWS SDK to upload an object in parts. Alternatively, you can perform the same action via the AWS CLI.
- You can also parallelize downloads from S3 using byte-range fetches. If there’s a failure during the download, the failure is localized just to the specific byte range and not the whole object.
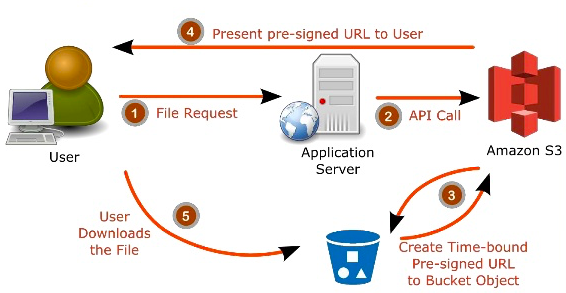
S3 Pre-signed URLs:
-
All S3 objects are private by default, however the object owner of a private bucket with private objects can optionally share those objects with without having to change the permissions of the bucket to be public.
-
This is done by creating a pre-signed URL. Using your own security credentials, you can grant time-limited permission to download or view your private S3 objects.
-
When you create a pre-signed URL for your S3 object, you must do the following:
- Provide your security credentials.
- Specify a bucket.
- Specify an object key.
- Specify the HTTP method (GET to download the object).
- Specify the expiration date and time.
-
The pre-signed URLs are valid only for the specified duration and anyone who receives the pre-signed URL within that duration can then access the object.
-
The following diagram highlights how Pre-signed URLs work:
S3 Select:
- S3 Select is an Amazon S3 feature that is designed to pull out only the data you need from an object, which can dramatically improve the performance and reduce the cost of applications that need to access data in S3.
- Most applications have to retrieve the entire object and then filter out only the required data for further analysis. S3 Select enables applications to offload the heavy lifting of filtering and accessing data inside objects to the Amazon S3 service.
- As an example, let’s imagine you’re a developer at a large retailer and you need to analyze the weekly sales data from a single store, but the data for all 200 stores is saved in a new GZIP-ed CSV every day.
- Without S3 Select, you would need to download, decompress and process the entire CSV to get the data you needed.
- With S3 Select, you can use a simple SQL expression to return only the data from the store you’re interested in, instead of retrieving the entire object.
- By reducing the volume of data that has to be loaded and processed by your applications, S3 Select can improve the performance of most applications that frequently access data from S3 by up to 400% because you’re dealing with significantly less data.
- You can also use S3 Select for Glacier.
CloudFront
CloudFront Simplified:
The AWS CDN service is called CloudFront. It serves up cached content and assets for the increased global performance of your application. The main components of CloudFront are the edge locations (cache endpoints), the origin (original source of truth to be cached such as an EC2 instance, an S3 bucket, an Elastic Load Balancer or a Route 53 config), and the distribution (the arrangement of edge locations from the origin or basically the network itself). More info on CloudFront’s features
CloudFront Key Details:
- When content is cached, it is done for a certain time limit called the Time To Live, or TTL, which is always in seconds
- If needed, CloudFront can serve up entire websites including dynamic, static, streaming and interactive content.
- Requests are always routed and cached in the nearest edge location for the user, thus propagating the CDN nodes and guaranteeing best performance for future requests.
- There are two different types of distributions:
- Web Distribution: web sites, normal cached items, etc
- RTMP: streaming content, adobe, etc
- Edge locations are not just read only. They can be written to which will then return the write value back to the origin.
- Cached content can be manually invalidated or cleared beyond the TTL, but this does incur a cost.
- You can invalidate the distribution of certain objects or entire directories so that content is loaded directly from the origin every time. Invalidating content is also helpful when debugging if content pulled from the origin seems correct, but pulling that same content from an edge location seems incorrect.
- You can set up a failover for the origin by creating an origin group with two origins inside. One origin will act as the primary and the other as the secondary. CloudFront will automatically switch between the two when the primary origin fails.
- Amazon CloudFront delivers your content from each edge location and offers a Dedicated IP Custom SSL feature. SNI Custom SSL works with most modern browsers.
- If you run PCI or HIPAA-compliant workloads and need to log usage data, you can do the following:
- Enable CloudFront access logs.
- Capture requests that are sent to the CloudFront API.
- An Origin Access Identity (OAI) is used for sharing private content via CloudFront. The OAI is a virtual user that will be used to give your CloudFront distribution permission to fetch a private object from your origin (e.g. S3 bucket).
CloudFront Signed URLs and Signed Cookies:
- CloudFront signed URLs and signed cookies provide the same basic functionality: they allow you to control who can access your content. These features exist because many companies that distribute content via the internet want to restrict access to documents, business data, media streams, or content that is intended for selected users. As an example, users who have paid a fee should be able to access private content that users on the free tier shouldn’t.
- If you want to serve private content through CloudFront and you’re trying to decide whether to use signed URLs or signed cookies, consider the following:
- Use signed URLs for the following cases:
- You want to use an RTMP distribution. Signed cookies aren’t supported for RTMP distributions.
- You want to restrict access to individual files, for example, an installation download for your application.
- Your users are using a client (for example, a custom HTTP client) that doesn’t support cookies.
- Use signed cookies for the following cases:
- You want to provide access to multiple restricted files. For example, all of the files for a video in HLS format or all of the files in the paid users’ area of a website.
- You don’t want to change your current URLs.
- Use signed URLs for the following cases:
Snowball
Snowball Simplified:
Snowball is a giant physical disk that is used for migrating high quantities of data into AWS. It is a peta-byte scale data transport solution. Using a large disk like Snowball helps to circumvent common large scale data transfer problems such as high network costs, long transfer times, and security concerns. Snowballs are extremely secure by design and once the data transfer is complete, the snowballs are wiped clean of your data.
Snowball Key Details:
- Snowball is a strong choice for a data transfer job if you need a secure and quick data transfer ranging in the terabytes to many petabytes into AWS.
- Snowball can also be the right choice if you don’t want to make expensive upgrades to your existing network infrastructure, if you frequently experience large backlogs of data, if you’re located in a physically isolated environment, or if you’re in an area where high-speed internet connections are not available or cost-prohibitive.
- As a rule of thumb, if it takes more than one week to upload your data to AWS using the spare capacity of your existing internet connection, then you should consider using Snowball.
- For example, if you have a 100 Mb connection that you can solely dedicate to transferring your data and you need to transfer 100 TB of data in total, it will take more than 100 days for the transfer to complete over that connection. You can make the same transfer in about a week by using multiple Snowballs.
- Here is a reference for when Snowball should be considered based on the number of days it would take to make the same transfer over an internet connection:

Snowball Edge and Snowmobile:
- Snowball Edge is a specific type of Snowball that comes with both compute and storage capabilities via AWS Lambda and specific EC2 instance types. This means you can run code within your snowball while your data is en route to an Amazon data center. This enables support of local workloads in remote or offline locations and as a result, Snowball Edge does not need to be limited to a data transfer service. An interesting use case is with airliners. Planes sometimes fly with snowball edges onboard so they can store large amounts of flight data and compute necessary functions for the plane’s own systems. Snowball Edges can also be clustered locally for even better performance.
- Snowmobile is an exabyte-scale data transfer solution. It is a data transport solution for 100 petabytes of data and is contained within a 45-foot shipping container hauled by a semi-truck. This massive transfer makes sense if you want to move your entire data center with years of data into the cloud.
Storage Gateway
Storage Gateway Simplified:
Storage Gateway is a service that connects on-premise environments with cloud-based storage in order to seamlessly and securely integrate an on-prem application with a cloud storage backend. and Volume Gateway as a way of storing virtual hard disk drives in the cloud.
Storage Gateway Key Details:
- The Storage Gateway service can either be a physical device or a VM image downloaded onto a host in an on-prem data center. It acts as a bridge to send or receive data from AWS.
- Storage Gateway can sit on top of VMWare’s ESXi hypervisor for Linux machines and Microsoft’s Hyper-V hypervisor for Windows machines.
- The three types of Storage Gateways are below:
- File Gateway - Operates via NFS or SMB and is used to store files in S3 over a network filesystem mount point in the supplied virtual machine. Simply put, you can think of a File Gateway as a file system mount on S3.
- Volume Gateway - Operates via iSCSI and is used to store copies of hard disk drives or virtual hard disk drives in S3. These can be achieved via Stored Volumes or Cached Volumes. Simply put, you can think of Volume Gateway as a way of storing virtual hard disk drives in the cloud.
- Tape Gateway - Operates as a Virtual Tape Library
- Relevant file information passing through Storage Gateway like file ownership, permissions, timestamps, etc. are stored as metadata for the objects that they belong to. Once these file details are stored in S3, they can be managed natively. This mean all S3 features like versioning, lifecycle management, bucket policies, cross region replication, etc. can be applied as a part of Storage Gateway.
- Applications interfacing with AWS over the Volume Gateway is done over the iSCSI block protocol. Data written to these volumes can be asynchronously backed up into AWS Elastic Block Store (EBS) as point-in-time snapshots of the volumes’ content. These kind of snapshots act as incremental backups that capture only changed state similar to a pull request in Git. Further, all snapshots are compressed to reduce storage costs.
- Tape Gateway offers a durable, cost-effective way of archiving and replicating data into S3 while getting rid of tapes (old-school data storage). The Virtual Tape Library, or VTL, leverages existing tape-based backup infrastructure to store data on virtual tape cartridges that you create on the Tape Gateway. It’s a great way to modernize and move backups into the cloud.
Stored Volumes vs. Cached Volumes:
-
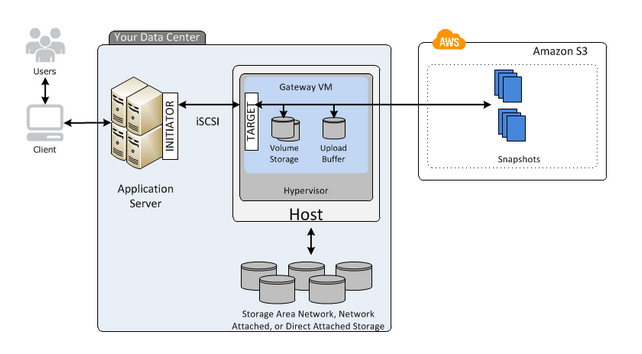
Volume Gateway’s Stored Volumes let you store data locally on-prem and backs the data up to AWS as a secondary data source. Stored Volumes allow low-latency access to entire datasets, while providing high availability over a hybrid cloud solution. Further, you can mount Stored Volumes on application infrastructure as iSCSI drives so when data is written to these volumes, the data is both written onto the on-prem hardware and asynchronously backed up as snapshots in AWS EBS or S3.
- In the following diagram of a Stored Volume architecture, data is served to the user from the Storage Area Network, Network Attached, or Direct Attached Storage within your data center. S3 exists just as a secure and reliable backup.
-
Volume Gateway’s Cached Volumes differ as they do not store the entire dataset locally like Stored Volumes. Instead, AWS is used as the primary data source and the local hardware is used as a caching layer. Only the most frequently used components are retained onto the on-prem infrastructure while the remaining data is served from AWS. This minimize
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









