







Adaptive Auxiliary Task Weighting for Reinforcement Learning. NeurIPS 2019
Adaptive Auxiliary Task Weighting for Reinforcement Learningpapers.nips.cc在强化学习中,使用辅助任务来帮助主任务的学习是重要的一类方法。主任务在学习中,由于奖励的稀疏性和任务的困难,可以使用辅助任务帮助学习特征表示。常见的辅助任务如下表所示。在学习RL主任务的同时,可以利用收集到的样本,用监督学习的方法来学习环境模型(forward dynamics),逆环境模型(inverse dynamics),利用图像状态的特殊性来学习Egomotion, Autoencoder的特征,利用光流来学习特征。由于学习这些辅助任务的时并不需要依赖环境提供的奖励信号,而只需要利用智能体在经验池中收集到的样本,因此这些任务被称为 self-supervised 学习方法。辅助任务将和主任务共享某些特征表示,在训练辅助任务的同时可以训练良好的特征表示,该特征表示将有利于加快主任务的学习。

以往的辅助任务学习方法,直接将主任务和多个辅助任务联合进行训练,辅助任务的权重需要进行调参。本文在此基础上提出了一种辅助任务的自适应加权方法。如下图,多个辅助任务将和主任务共享卷积特征表示,随后主任务和辅助任务被映射成低维特征表示进行连接,最后输出每个辅助任务的损失。如果使用固定的权重来加权各个辅助任务的损失,会存在以下问题:
- 有些辅助任务在训练的前期比较重要,在后期慢慢变得不重要,权重应该是变化的
- 有些辅助任务甚至会拖慢训练的进程,对主任务的学习没有帮助,应该给予较小的权重
本文的创新点在于各个损失到最终损失的过程进行了自适应的加权。每个辅助任务的权重
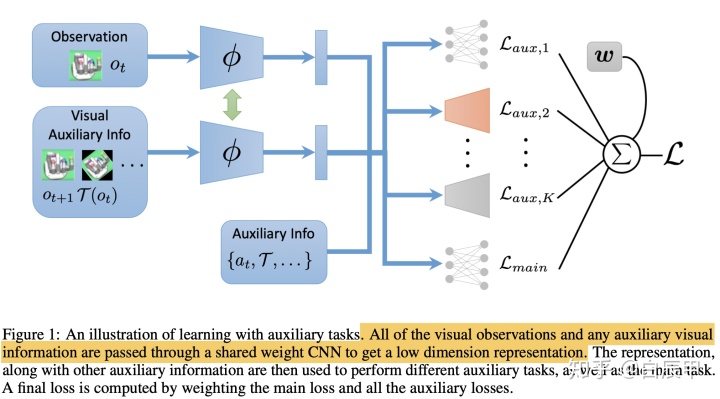
自适应的辅助任务加权(1-step update)
本文对辅助任务学习目标的假设是辅助任务能够使得主任务的损失更快的下降。如果一个辅助任务和主任务的损失的梯度方向是一致或接近的(比如夹角小于90度),那么该任务被认为是重要的,有利于主任务学习的。如果二者梯度方向相反,则认为该辅助任务不利于主任务的学习,应该给予较小的权重。本文对加权过程提供了比较理论化的方法。
考虑有
其中
我们希望在辅助任务的作用下,主任务迭代的更快。我们希望最大化 main 网络的损失变化:
由于
进而,根据一阶泰勒公式
带入
消元得
由于辅助任务的权重
其中,偏导数项中,根据
由此我们得到了辅助任务权重
“
我们知道,
- 如果辅助任务对主任务的学习是有利的,二者梯度的夹角应该很小,此时cos值接近于1
- 如果辅助任务与主任务不相关,二者的夹角接近于正交,此时cos值接近于0
- 如果辅助任务对主任务的学习是不利的,二者的梯度方向相反,此时 cos值小于0
因此,当辅助任务和主任务对
自适应的辅助任务加权(N-step update)
以上
目标函数可以写成:
将
利用泰勒公式展开第一项
类似的,展开上式中的第一项
再次展开上式中的第一项
进而
使用 N-step 的目标来更新相比于 1-step 有如下优势:
- 使用多步的目标使得算法能够考虑到较长时间段内的总体损失,相比于单步损失更合理
- 使用多步的目标可以平滑梯度,相比于单步损失产生的梯度更加稳定。此外,一般我们可以认为,辅助任务的权重应该在训练过程中有一个稳定的变化而不是跳变。
总结 N-step 的方法来更新的算法如下:

实验
1. 简单的监督学习实验
主任务:
辅助任务1:
辅助任务2:
这三个任务中,明显的, 辅助任务2的损失和主任务是完全相反的。总体损失定义为:
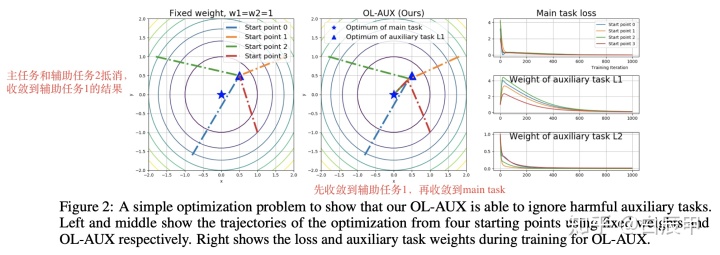
如果将辅助任务权重设置为固定的值,如
下图中显示了自适应的权重调节结果。从不同方位初始化的点会先收敛到
2. 其他实验
本文使用 Atari 中 Breakout, Pong, Seaquest 和 Gym Robotics中 FetchReach, HandReach等使用HER算法在多目标环境下进行实验。在这些环境的主任务中,添加本文刚开始所示的Table 1所示的辅助任务,包括前向环境模型,逆环境模型,egomotion, auto-encoder, 光流等。
文章包括以下Baseline,其中与本文直接相关的是 Cosine Similarity. 但该baseline是一种硬约束,当二者梯度夹角小于 90 度的时候可以使用辅助任务,否则将其权重置0.

以下是在多个环境中的比较结果:
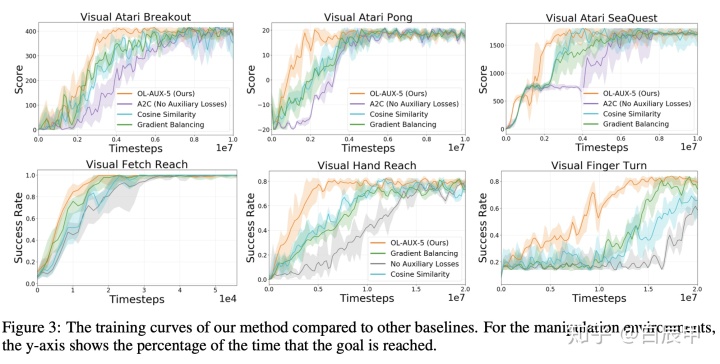
另外,N-step的方法要优于1-step的方法:
















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









