






✍🏻 本文作者:一两、聆涛、渡叹、烈文
丨目录:
· 背景
· 方法
· 实验验证
· 总结
· 关于我们
· 参考文献
本文介绍阿里妈妈外投广告UD算法团队在CVR预估模型去偏上的实践与探索,该项工作论文已发表在 WWW 2022。
论文: UKD: Debiasing Conversion Rate Estimation via Uncertainty-regularized Knowledge Distillation
下载: https://arxiv.org/abs/2201.08024
1. 背景
转化率 (Post-click Conversion Rate, CVR) 预估是广告/推荐系统中的一项重要任务。转化率被定义为一个曝光广告在被用户点击的情况下会发生转化的条件概率,即:
402 Payment Required
其中,表示样本的特征。和均为二值变量,分别表示曝光后的点击事件和转化事件是否发生,即 CTR 任务和 CTCVR 任务的 label;表示点击后是否转化,即 CVR 任务的 label。
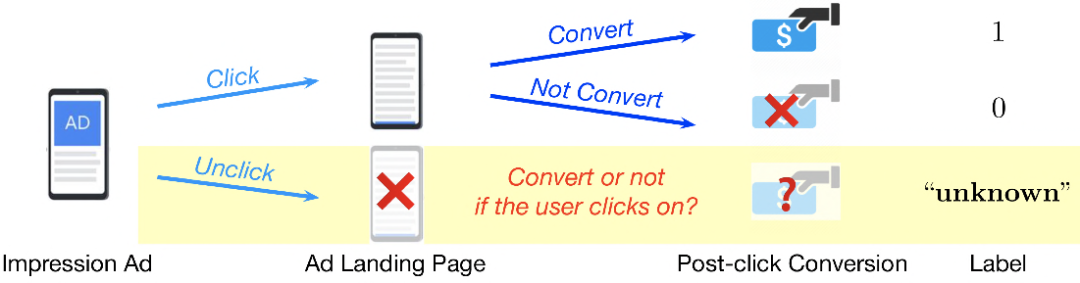
在线广告系统中,用户反馈日志会记录每一条展现广告的点击 label和转化 label ,如图1所示。在广告曝光之后,如果用户点击了该条广告并到达一个落地页,之后可能会做出加购、支付等深度行为。显然,只有在曝光广告被点击的情况下,日志才会记录到真实的转化 label;而对于未点击的广告,它们的实际上为 “unknown”,因为我们无法观测到假设用户点击的情况下其是否会继续发生转化。由于未点击广告缺乏真实的转化 label,传统 CVR 模型通常使用点击样本进行训练;然而其在线服务时需要在参竞空间中进行预估,训练/推理空间之间的差异制约了模型的泛化性能,我们常称之为样本选择偏差问题(Sample Selection Bias,SSB)。
研究CVR模型中的SSB问题的主流方法大致可以分为两类:1)基于辅助任务的方法 [1, 2] ;2)基于反事实学习的方法 [3, 4] 。
1)基于辅助任务 (auxiliary task learning) 的方法:如ESMM、AutoHERI等。ESMM 引入两项辅助任务 CTR预估和CTCVR预估,由于CTR和CTCVR预估任务均在全空间(曝光空间)中训练,因此可导出全空间的CVR模型。然而,对于未点击样本,ESMM类方法会将该类样本的往 0 优化,然而其转化 label 实际上是“unknown”而不是 0。简短证明如下:
402 Payment Required
可以看到,在未点击样本上,CTCVR 任务的目标函数对的梯度恒正,因此总是会将该值向 0 优化。另一方面,对于点击未转化样本,该类样本同时是 CTR 任务的正样本、CTCVR 任务的负样本,优化时可能会存在梯度问题。
2) 基于反事实学习 (counterfactual learning) 的方法:如Multi-IPS、Multi-DR等。IPS类方法利用全空间样本集来计算点击样本的倾向分数,通过用倾向分数对点击样本加权的方式来模拟全空间数据分布,理论上无偏但实践发现方差较大,并且CVR模型的训练过程仅使用了点击样本(未点击样本在产出倾向分数时间接使用)。DR类方法在IPS的基础上引入 Imputation model来估计未点击样本的CVR loss,理论上无偏(前提是IPS和Imputation model两者至少有一个是无偏的即可)。然而在大规模在线广告系统中,存在较多的筛选策略,理论上无偏所需要的前提很难满足;此外,DR类方法在CVR模型训练过程中仍然未直接使用未点击样本。在离线迭代以及与兄弟团队交流过程中均发现反事实学习类方法在十亿至百亿级数据集上训练时依然存在方差大、不同数据集下的有效性有差异等问题,因此我们考虑未来沿这个方向继续演进。
综上,现有的缓解 CVR 模型 SSB 问题的方法,基于辅助任务的方法对于未点击样本的学习存在梯度问题,基于反事实学习的方法在训练过程中未有效利用未点击样本、大规模数据上效果不稳定等问题。
我们认为,SSB 问题在本质上讲是未点击样本的转化 label 是 unknown 带来的。受到 [5, 6] 的启发,我们的解决思路是考虑对未点击样本提供一个“伪转化 label”:将点击样本(有真实的转化 label)、未点击样本(转化=unknown)分别看作源域、目标域,通过领域自适应(domain adaptation)的思想来给未点击样本打标。当未点击样本得到伪转化 label 后,CVR 任务便可以在全空间上进行训练。基于此,我们从未点击样本中提取知识,提出基于不确定性约束的知识蒸馏框架 UKD (Uncertainty-Regularized Knowledge Distillation) 实现全空间 CVR 预估,其包含一个点击自适应的教师模型和一个不确定性约束的学生模型。教师模型借鉴领域自适应的方式,学习曝光样本的点击自适应表示并生成未点击样本的伪转化标签。生成伪标签后,学生模型利用点击样本和未点击样本进行全空间训练。同时,学生模型引入不确定性建模伪标签中的固有噪声,在蒸馏过程中自适应地削弱噪声的影响以取得更优的预估效果。在多个效果外投场景上的在线实验验证了 UKD 在 CVR、CPA 等指标上获得了显著提升。
2. 方法
我们提出了一种基于不确定性约束的知识蒸馏方法(Uncertainty-regularized Knowledge Distillation, UKD),通过从未点击的样本中提取知识来对CVR模型进行去偏。该方法的基础思想是给未点击样本提供可靠的伪标签作为监督信号,从而获得全空间的CVR预估模型。
图2给出了UKD的模型框架,其包含一个点击自适应的教师模型和一个不确定性约束的学生模型。教师模型借鉴领域自适应的方式,学习曝光样本的点击自适应表示并生成未点击样本的伪转化标签。生成伪标签后,学生模型利用点击样本和未点击样本进行全空间训练。接下来,我们对各个部分进行详细介绍。
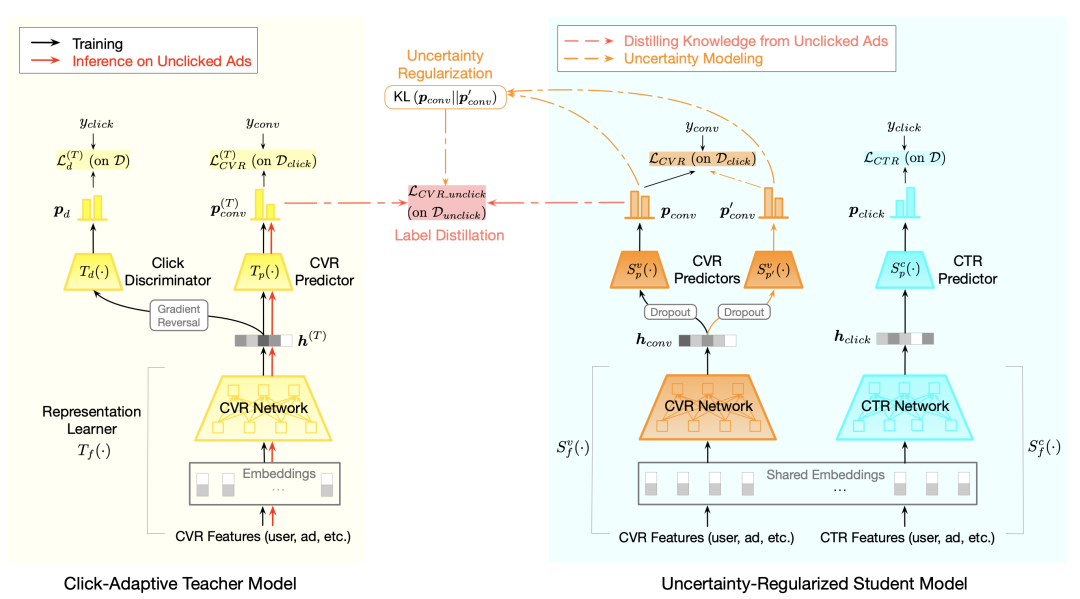
2.1 点击自适应的教师模型 Click-adaptive Teacher
在仅能获得点击广告真实转化标签的情况下,教师模型负责给未点击广告生成伪转化标签,从而使CVR模型能够在全空间中训练。一个简单的想法是直接使用在点击空间上训练的CVR模型对未点击样本预估CVR作为伪转化标签,但考虑到点击样本和未点击样本的特征分布间存在差异,若要获得准确的伪转化标签,教师模型不应学习与点击相关的特征表示,而需要利用未点击样本来学习样本的点击自适应表示。具体地,将伪标签生成问题建模为无监督域适应问题,源空间和目标空间分别对应于点击/未点击空间,我们即是要在给定源空间有标签样本的情况下,生成目标空间无标签样本的伪转化标签。
2.1.1 点击自适应的表示学习
教师模型采用对抗学习的方法,通过引入一个点击/未点击分类器来减弱点击/未点击样本特征分布间的差异。如图2左侧所示,点击自适应的教师模型包含一个特征提取模块、一个CVR预估模块,和一个判别器模块,均为多层 DNN 结构。接受样本特征作为输入并学习它的特征表示,进一步基于特征表示 来输出CVR预估分数 。判别器 则基于特征 执行域分类任务,对点击/未点击样本进行区分。整个教师模型的前向过程如下:
采用对抗训练方法来学习到点击无关的隐层特征表示。对于特征,当分类器最小化域分类 loss 时,特征则需要混淆判别器,使域分类的损失最大化;另一方面,特征需要让能够输出准确的CVR预估:
第一式是CVR预估的损失函数,第二式是域分类器的损失函数,它的目的是区分点击/未点击样本,而特征提取模块尝试令点击/未点击的样本无法被很好地区分,将两个空间的表示分布对齐。
2.1.2 未点击样本的伪标签生成
教师模型训练完毕后,我们在未点击样本集上进行 inference(前向过程仅包含特征提取模块和CVR预估模块),产出每个未点击样本的伪转化标签。我们将包含伪转化标签的未点击样本集合记为。
2.2 不确定性约束的学生模型 Uncertainty-regularized Student
基于教师模型产出的伪转化标签,我们进一步地利用知识蒸馏建立一个学生模型,该模型同时利用点击样本(真实标签)和未点击样本(伪标签)进行训练,以达到全空间的CVR模型。因此,相比较仅使用点击样本进行训练的模型,我们的模型通过显式地引入未点击样本来缓解SSB问题。由于未点击样本的伪标签中的固有噪声,伪标签的可靠性天然地不如真实标签。为此我们提出基于不确定性约束的学生模型来缓解噪声带来的负面影响。下面我们首先介绍基础的学生模型,再详细说明不确定性约束方法。
2.2.1 基础学生模型 Base Student
基础学生模型的网络结构采取 CTR、CVR 多任务结构,包括两个特征提取模块(服务CVR任务,服务CTR任务,并且二者共享 embedding 层),一个CVR预估模块,一个CTR预估模块。每个提取模块均是 DNN 结构来提取隐层特征表示,模型的前向过程如下:
402 Payment Required
402 Payment Required
在CVR任务中,对于点击和未点击样本,我们分别使用真实转化标签和伪转化标签进行监督。基础学生模型的优化目标是CTR任务和CVR任务两个损失之和:
402 Payment Required
402 Payment Required
2.2.2 不确定性约束策略 Uncertainty Regularization
未点击样本的监督信号来自于教师模型产出的伪转化标签,其可靠性天然低于点击样本上的真实标签。伪标签中的固有噪声会在模型训练过程中产生误导。为了更有效地利用未点击样本,关键在于两点:1)识别出未点击样本中的噪声/不可靠标签;2)在知识蒸馏过程中降低噪声的负面影响。我们通过估计伪标签的不确定性来辨别不可靠样本,高的不确定性即代表该样本更不可靠。对于高不确定性样本,我们可以在训练中减小其损失函数的权重从而降低其可能带来的负面影响。基于以上考虑,我们提出不确定性约束的学生模型,它通过估计每个未点击样本伪标签的不确定性,并且动态调整其损失函数的权重来减弱噪声。
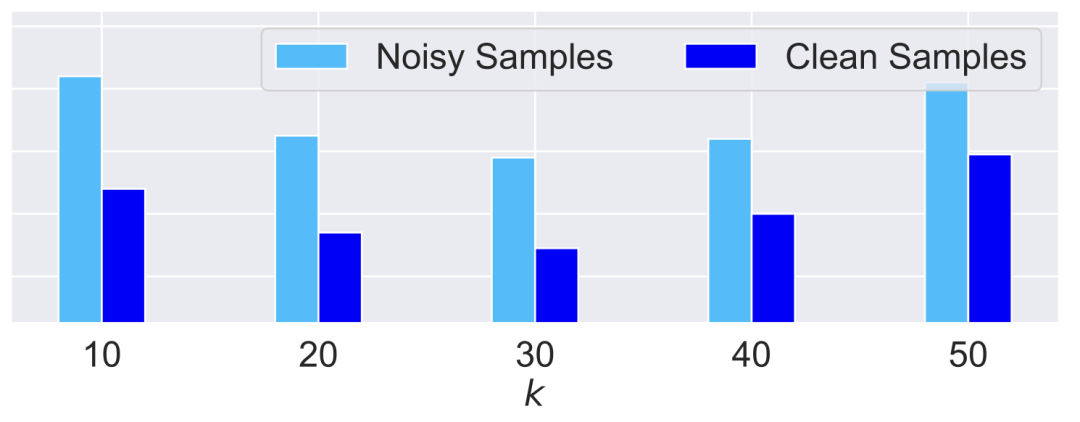
第一步:识别出未点击样本中的噪声/不可靠标签。 首先通过一个简单的实验来探究当模型在噪声数据或纯净数据上训练时,其表现有何差异。由于点击样本有真实转化 label,因此我们在点击样本集上进行该实验。具体来讲,我们随机选择的正样本并将它们反转为负样本;为了保证正样本率不变,我们对相同数量的负样本也反转为正样本。经过上述操作,我们得到一个有噪声样本集,包含纯净样本和噪声样本两部分。受噪声数据学习的相关研究常常基于集成学习思想 [7, 8] 的启发,我们在噪声样本集上训练一个有两路输出的 CVR 模型,该模型包括一个特征提取模块和两个独立的 CVR 预估模块,训练的目标为两个预估模块上计算出的 CVR loss 的均值最小化。在训练后,我们分别在纯净样本子集、噪声样本子集上计算出两个 CVR 预估模块的平均 KL 散度,反映两个预估模块的打分差异。图3给出了随值变化时的结果,我们发现两个预估模块在噪声样本子集上的打分差异明显大于在纯净样本子集上的打分差异,一定程度上说明两个预估模块在噪声样本上的学习程度的不一致性要大于在纯净样本上。
通过上述实验,我们认为如果同时用两个CVR预估模块,它们在噪声样本上的预估结果很难保持一致,输出值差异更大,即代表更高的不确定性。基于以上结论,学生模型采用两个CVR预估模块和(在隐层特征上添加dropout操作以引入更多的差异),使用两个预估值之间的KL散度来衡量未点击样本的不确定性,具体如下:
402 Payment Required
402 Payment Required
第二步:基于不确定性约束的知识蒸馏。 在建立不确定性估计的方法后,学生模型利用不确定性约束来优化训练。在训练过程中,学生模型计算得到每个未点击样本的不确定性,并基于不确定性动态调整样本损失函数的权重,以减弱不可靠伪标签对模型学习过程带来的负面影响。具体地,在模型学习时,对于未点击样本使用作为其CVR loss的权重系数,该系数与不确定性呈负相关,意味着不确定性越高时权重越低。因此,未点击样本上的 CVR loss 可以重写为:
此外,我们额外引入一个正则项作为不确定性估计的约束,如果没有此项,上述CVR loss会倾向于获得更高的不确定性以降低loss,导致模型优化方向错误。基于此,CVR 任务的 loss 共有三项:点击样本上的 CVR loss、未点击样本上的 CVR loss、不确定性估计的正则项。
在实践中,认为两路CVR预估模块的地位等价,因此最终的 loss 形式会添加对称项
402 Payment Required
和402 Payment Required
。在 inference 的时候,取两路模块输出的均值作为最终的预估结果。3. 实验验证
3.1 离线实验
3.1.1 实验设置
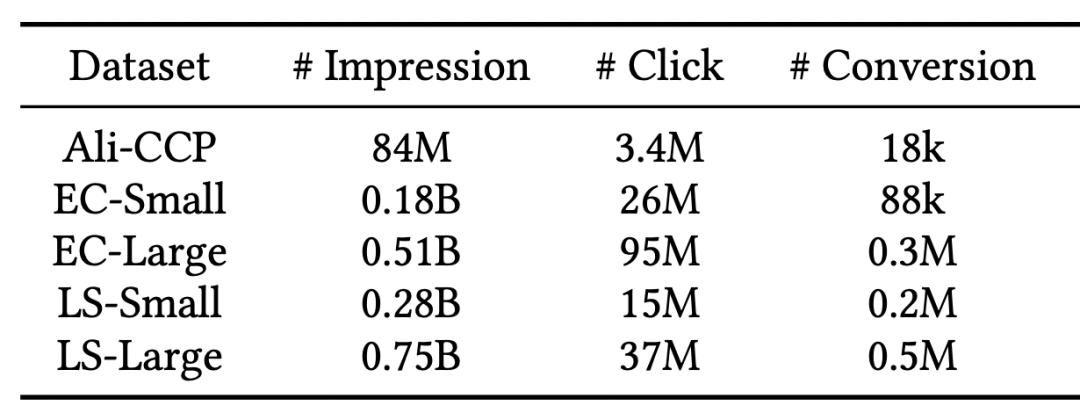
数据集: 我们从阿里妈妈外投广告业务中的电商外投和本地生活外投两个场景,构造了四个量级在两亿至八亿的数据集进行实验;此外我们也在公开数据集Ali-CCP上也进行了实验验证,量级八千万。数据集统计如表1所示。
基线方法:
SingleCVR:单独的CVR预估模型,模型在点击样本集上训练;
Joint:CTR和CVR联合训练模型。CTR分支使用曝光样本集上训练,CVR分支在点击样本集上训练;
ESMM:基于辅助任务学习的去偏模型,有CTR和CVR两个网络分支,使用CTR和CTCVR的损失函数对网络进行优化;
Division:ESMM的变种,两个分支分别预测CTR和CTCVR,然后导出CVR(
402 Payment Required
)。CFL:基于反事实学习的去偏模型,这里我们采用MultiDR模型。
所有模型的结构均为相同size的四层 DNN(模型需要多个分支的情况下则每个分支都是四层DNN,例如ESMM有CTR&CVR两个分支、CFL 有CTR&CVR&Imputation三个分支、UKD的学生模型有CTR&CVR两个分支)。UKD的不确定性约束是基于第三层输出的隐层特征表示进行的。
评估指标:为比较各个去偏方法,我们在点击样本上评价 CVR 预估性能、在全空间样本上评价 CTCVR 预估性能(使用统一的 CTR 模型使各方法得以公平比较),使用的指标包括反映排序能力的AUC和反映准度的NLL(LogLoss)。此外为了进一步评估模型对SSB问题的缓解程度,我们设计了Debiased-AUC和Debiased-NLL指标来在点击样本上评价CVR预估性能,定义如下:
402 Payment Required
402 Payment Required
402 Payment Required
402 Payment Required
3.1.2 SOTA对比
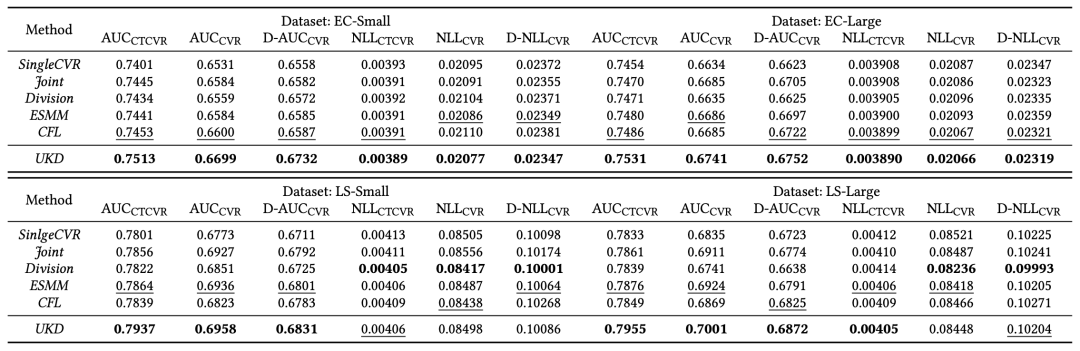
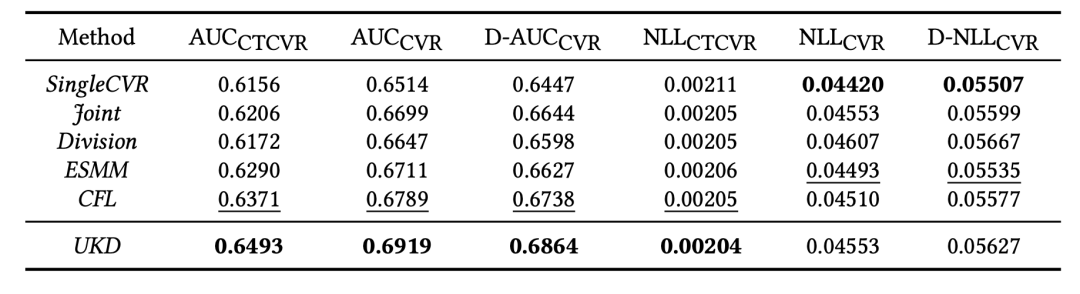
表2和表3列出了在各数据集上的测试结果,可以看出相比较其他SOTA模型,UKD的提升比较明显。特别地,对于生产数据集,在和指标上相比次优模型提升幅度很大(约有0.5%)。这验证了我们的方法通过点击自适应的教师模型产出伪转化标签,以及基于不确定性约束的蒸馏策略,能够有效地对CVR模型进行去偏。
3.1.3 进一步的分析和讨论
为了验证 UKD 不同模块的效果,我们从如下几个方面进行更细致的实验:1)教师模型的效用;2)学生模型中不确定性约束蒸馏的效用;3)未点击样本的作用;4)关键超参的影响。
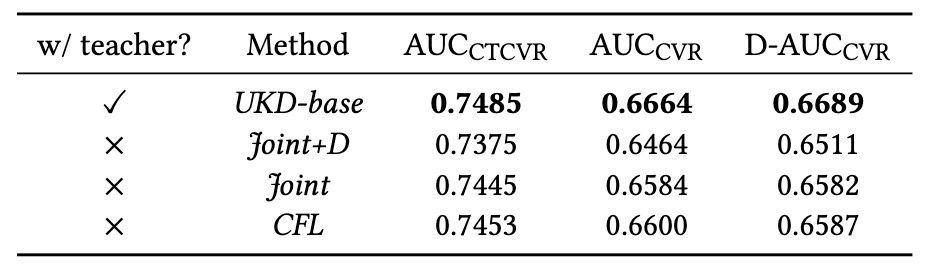
1)教师模型的必要性和有效性:教师模型负责产出未点击样本的伪标签。我们实验验证教师模型存在的必要性,以及点击自适应教师模型带来的好处。表4对比了UKD-base(移除了不确定性约束策略的基础学生模型)和若干个不存在教师模型的方法(Joint、CFL)的效果,可以发现引入教师模型对于效果提升确有帮助。
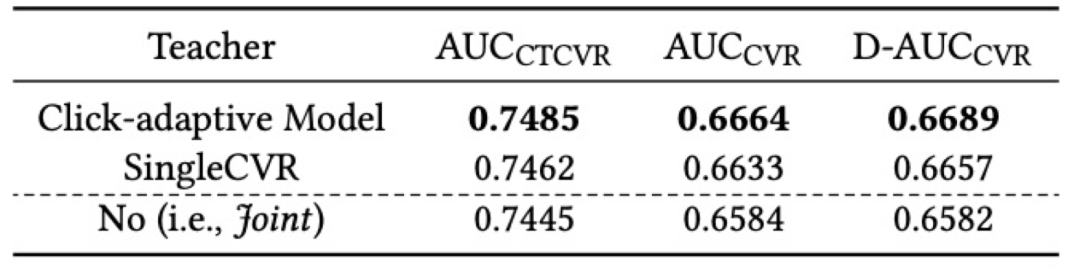
表5进一步比较了使用不同模型作为教师模型时,学生模型最终的效果。可以得出,相比于 SingleCVR 作为教师,基于点击自适应的教师模型可以令学生模型获得更好的性能表现。
2)学生模型中不确定性约束策略的作用:不确定性约束的学生模型通过两个CVR预测模块的差异来估计不确定性。为了验证该策略的作用,我们将其与经典的不确定性估计方法MC Dropout[9]进行对比,其中MC Dropout的使用方式如下:在教师模型的结构上施加 0.2 的dropout rate,对未点击样本执行10次inference(由于dropout的随机性所以10次预估结果会产生差异),取10次预估结果的均值作为伪标签、方差作为不确定性;并且将不确定性最高的20%未点击样本视作噪声并移除,剩下的80%未点击样本用于训练学生模型。实验结果在表6中列出,可以看出带有不确定性约束的两个模型相比于 UKD-base 有性能优势,因此缓解噪声进而提高学生模型的表现是有意义的,并且我们的估计方法要优于MC Dropout。另外需要注意的是,MC Dropout 估计不确定性时由于需要基于教师模型来做多次inference,而UKD的不确定性估计方法是在学生模型训练过程中end-to-end进行的,所以UKD还有着效率上的优势。
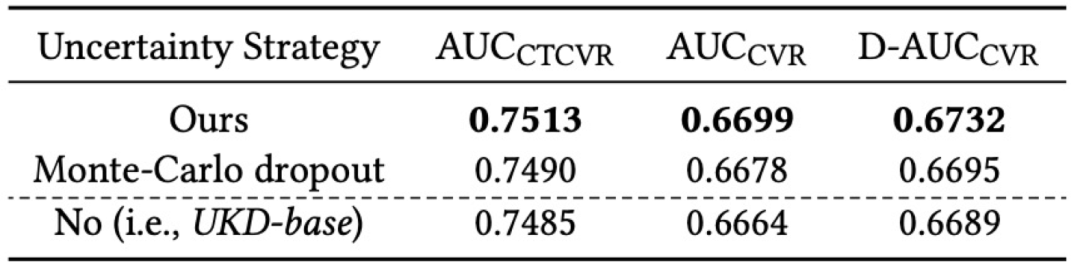
3)未点击样本数量的影响:我们实验对比了教师模型使用不同数量的未点击样本时,对最终的学生模型性能的影响。从图4中可以看出,对于教师模型,当点击:未点击=1:1时性能最优,将源域:目标域数据量组织成1:1是对抗训练形式下的一种经验性的选择;而进一步地对于学生模型,总体上说模型性能随着未点击样本量的增加而稳定提升。
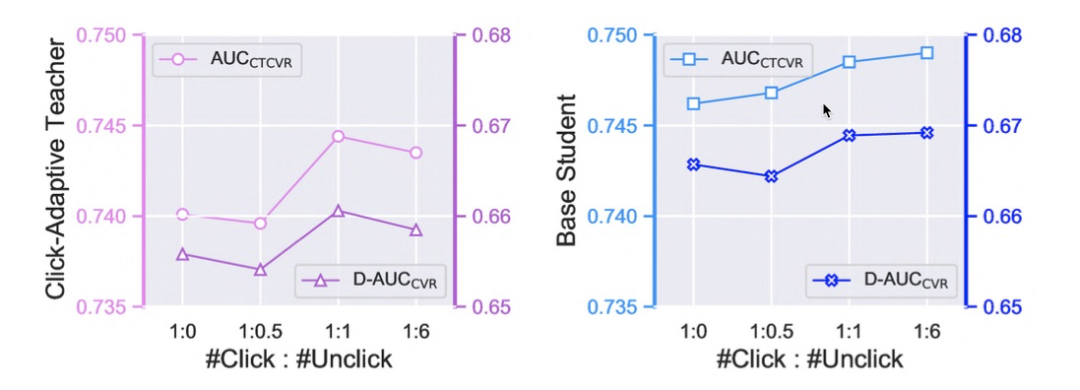
4)关键超参的影响:UKD 的核心是显式引入未点击样本,两个关键超参是不确定性估计时的 dropout rate、以及优化目标中的未点击样本CVR loss的系数。图5给出了模型性能对上述两个超参的敏感度,可以发现性能最佳的模型在 dropout rate 0.2 时达到,并且当 loss 系数增加时也有助于提升效果。
3.2 在线实验
UKD已经在外投多个业务场景上线并取得了正向在线效果(尽管图4表明模型性能随着未点击样本的增加而提升,但考虑到未点击样本量级过大带来额外训练成本的问题,我们的上线版本仍然选择将教师模型的未点击样本采样为与点击样本形成 1:1 的比例)。以本地生活效果外投场景为例,相比于持续通过特征、多模块联动等方式优化迭代的基线模型取得了 CVR +3.4%, CTCVR +5.0%, CPA -4.3% 的明显效果。
4. 总结
为了缓解CVR模型的SSB问题,我们提出了一个不确定性约束的知识蒸馏模型UKD,通过从未点击的广告中提取知识来对CVR模型去偏。该框架使用点击自适应的教师模型为未点击的广告生成伪转化标签,同时引入点击样本和未点击样本在整个曝光空间中训练学生模型,得到全空间的CVR预估模型。此外,我们的学生模型进行不确定性估计,以减轻伪标签中的固有噪声,从而改善蒸馏性能。在大规模生产数据集上的实验结果有力地证明了UKD在CVR估计中的优越性。在线实验进一步验证了该算法在CVR、CTCVR和CPA等核心在线指标上取得了显著的改进。
关于我们
阿里妈妈外投广告UD效果&用增算法团队 是阿里集团媒体推广核心团队,依托于集团庞大而真实的营销场景,以AI技术驱动实现客户商品营销,并承担集团App用户增长等业务需求。我们持续探索人工智能,联邦学习,深度学习,多任务学习、强化学习,知识图谱,图学习等前沿技术在外投广告和用增方面的落地应用。在创造业务价值的同时,团队近1年也在WWW、SIGIR、CIKM、NAACL等信息检索领域顶级会议上发表多篇论文,热忱欢迎对广告算法,推荐系统,图像理解、NLP等方向感兴趣的同学加入我们!
参考文献
[1] XiaoMa, LiqinZhao, GuanHuang, ZhiWang, ZelinHu, XiaoqiangZhu, and Kun Gai. 2018. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate. In The 41st International ACM SIGIR Conference on Research and Development in Information Retrieval.
[2] Penghui Wei, Weimin Zhang, Zixuan Xu, Shaoguo Liu, Kuang-chih Lee, and Bo Zheng. 2021. AutoHERI: Automated Hierarchical Representation Integration for Post-Click Conversion Rate Estimation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 3528–3532.
[3] SiyuanGuo, LixinZou, YidingLiu, WenwenYe, SuqiCheng, ShuaiqiangWang, Hechang Chen, Dawei Yin, and Yi Chang. 2021. Enhanced Doubly Robust Learn- ing for Debiasing Post-click Conversion Rate Estimation. In The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval.
[4] Wenhao Zhang, Wentian Bao, Xiao-Yang Liu, Keping Yang, Quan Lin, Hong Wen, and Ramin Ramezani. 2020. Large-scale Causal Approaches to Debiasing Post-click Conversion Rate Estimation with Multi-task Learning. In Proceedings of The Web Conference 2020. 2775–2781.
[5] BowenYuan, Jui-YangHsia, Meng-YuanYang, HongZhu, Chih-YaoChang, Zhenhua Dong, and Chih-Jen Lin. 2019. Improving ad click prediction by considering non-displayed events. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 329–338. [6] Zhihong Chen, Rong Xiao, Chenliang Li, Gangfeng Ye, Haochuan Sun, and Hongbo Deng. 2020. ESAM: Discriminative domain adaptation with non-displayed items to improve long-tail performance. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 579–588.
[7] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2016. Simple and scalable predictive uncertainty estimation using deep ensembles. In Proceedings of the 31st Conference on Neural Information Processing Systems.
[8] Zhedong Zheng and Yi Yang. 2021. Rectifying pseudo label learning via uncertainty estimation for domain adaptive semantic segmentation. International Journal of Computer Vision 129, 4 (2021), 1106–1120.
[9] Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning. 1050–1059.
END

也许你还想看
丨 CIKM 2021 | AutoHERI: 基于层次表示自动聚合的 CVR 预估模型
丨 WWW 2022 | MBCT:基于树模型的特征可感知的个性化校准方法
丨 WWW 2022 | 搜索广告CVR延迟反馈建模DEFUSE
丨 阿里妈妈技术团队 5 篇论文入选 TheWebConf 2022
疯狂暗示↓↓↓↓↓↓↓
















 16
16











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









