








1. 概述
这次我们一起讨论SuperPoint系列文章的第二篇Toward Geometric Deep SLAM,这篇文章延续了作者清晰的写作思路,读起来很顺畅。
本文是针对SLAM设计的基于深度学习的特征提取方法,主要包括两部分,一是特征点提取网络MagicPoint,二是基于提取的特征点进行位姿估计的网络MagicWarp。特别指出的是,改方法不需要学习描述子,而只提取特征点位置。由于训练网络需要图片之间真实的位姿,作者设计了一个虚拟三维物体的库,通过模拟不同视角并截取相应的图片,得到了所需要的数据集。最终的结果显示MagicPoint在提取特征方面相比于传统方法更具鲁棒性,MagicWarp在位姿估计方面具有更高精度。
2. 算法流程
算法的整体流程如下图所示
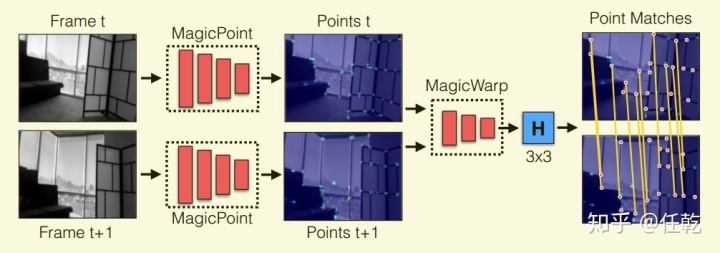
从图中可以看出,该方法首先对两张图片分别使用MagicPoint提取特征点,然后使用MagicWarp把提取的特征点作为输入,对两张图片进行位姿的估计,直接输出一个3X3的转换矩阵。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









