






0 摘要
本文提出了一种自监督框架,用于训练适用于计算机视觉中大量多视图几何问题的感兴趣点检测器和描述符。与基于patch的神经网络相反,我们的全卷积模型在全尺寸图像上运行,并在一次正向传递中联合计算像素级的兴趣点位置和相关描述符。我们引入了 Homographic Adaptation,这是一种多尺度、多同源性的方法,用于提高兴趣点检测的可重复性并执行跨域适应(例如,合成到真实)。当使用 Homographic Adaptation在MS-COCO通用图像数据集上进行训练时,我们的模型能够重复检测比初始预适应深度模型和任何其他传统角点检测器更丰富的兴趣点集。与LIFT,SIFT和ORB相比,最终系统在HPatches上产生了最先进的单应性估计结果。
批注:为了解决多视图几何问题,提出 Homographic Adaptation ,这个是理解这篇文章的关键
1 介绍
大致说,为了实现一个有意义的自监督框架,需要很多pseudo-ground truth兴趣点。用一个合成的数据集–Synthetic Shapes,训练出来的检测器叫MagicPoint,用该检测器生成pseudo-ground truth兴趣点。尽管MagicPoint很好,但是存在域适应困难。为了解决这个问题,提出一个多尺度、多变化技巧–Homographic Adaptation。Homographic Adaptation旨在实现兴趣点检测器的自监督训练。使用Homographic Adaptation联合MagicPoint增强检测器的性能,并创建了很多pseudo-ground truth兴趣点,我们将它叫做SuperPoint。
批注:pseudo-ground truth,是非真实的ground truth,不做翻译。pseudo是由训练好的模型标注的,不确定是否正确的 label。
2 相关工作
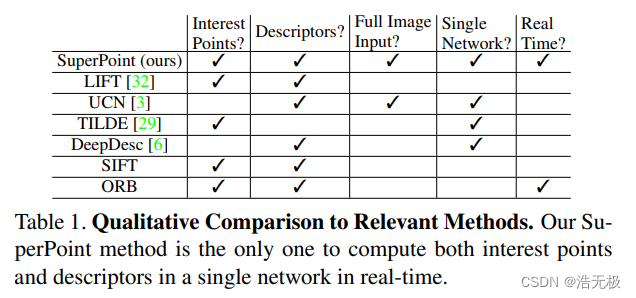
The FAST corner detector 是第一个快速检测特征点的算法,SIFT是传统里面最出名局部特征描述符。SuperPoint的灵感来源就是最近的深度学习结合特征提取。如表一所示,SuperPoint是最全面的。再简单介绍一下监督和无监督的方法。
表一
3 SuperPoint 框架
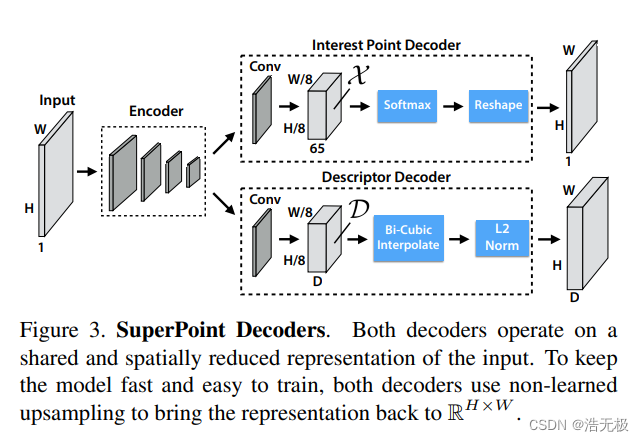
我们设计了一种名为SuperPoint的全卷积神经网络架构,该架构在全尺寸图像上运行,并在单次正向传递中生成兴趣点检测以及固定长度的描述符(见图3)。该模型具有单个共享编码器,用于处理和减少输入图像维度。在编码器之后,架构分成两个解码器,它们学习任务特定的权重,一个用于兴趣点检测,另一个用于兴趣点描述。网络的大部分参数在两个任务之间共享,这与传统系统背道而驰。传统系统首先检测兴趣点,然后计算描述符,并且缺乏在两个任务之间共享计算和表示的能力。
图3
3.1 共享编码器
常规的VGG网络对输入图片降维,编码器由空间下采样池化和非线性激活函数组成。
3.2 兴趣点检测器
兴趣点检测器输出图片每个像素的概率(感兴趣程度)。类似 SegNet [1] 这种标准的稠密预测网络,使用编码器–解码器结构,先通过池化和滑动卷积降维,最后通过上采样反卷积回全尺寸图片。但由于上采样要使用大量的计算,所以我们提出显式解码器以减少模型计算量(实质这里用了sub-pixel convolution操作,也叫 pixel shuffle)。
批注:兴趣点,即特征点
3.3 描述子检测器
为了得到稠密固定长度描述子,先学习得到一种半稠密的描述子类似UCN里面的。半稠密学习描述子是为了减少训练内存和减少计算量。解码器输出经过双三次插值算法,再经过L2正则化,就能得到稠密的,固定长度的描述子了。
3.4 损失函数
Lp表示兴趣点检测器的损失函数,Ld表示描述子检测器的损失函数。我们用一组合成旋转图片,包含了pseudo-ground truth兴趣点位置和真实的两张图片经过homography warping操作的对应关系(homography warping是一项技术,关键字:图像对齐,多视角图片)。
原话:We use pairs of synthetically warped images which have both (a) pseudo-ground truth interest point locations and (b) the ground truth correspondence from a randomly generated homography H which relates the two images.
批注:这段话翻译就是很拗口,我理解为有伪的兴趣点位置和真实的两张图片的对应关系。
这对于一对图片,我们可以同时优化两个损失函数。使用 λ 平衡最终的损失函数:
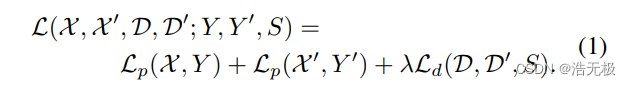
交叉熵损失函数,xhw ∈ X ,yhw∈Y,Y是标签:
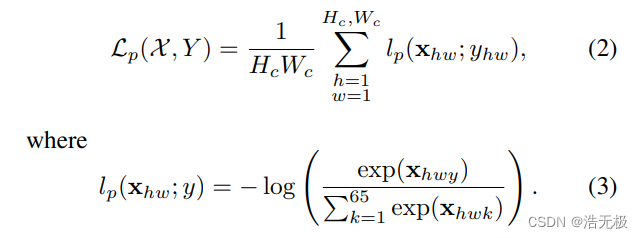
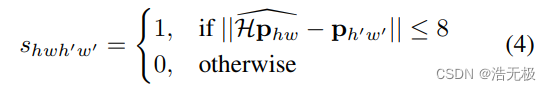
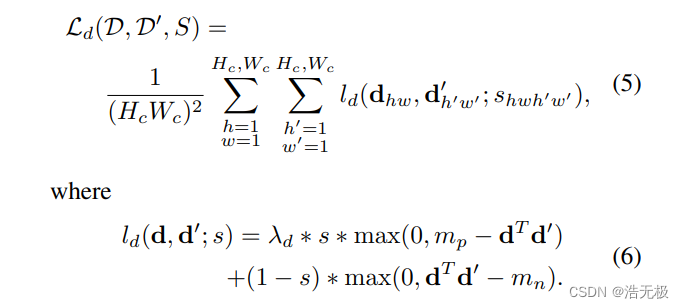
批注:这个损失函数暂时没看懂
4 合成预训练
base Detector 叫 MagicPoint,和 Homographic Adaptation 联合用无监督方式从无标签图片训练生成pseudo-ground truth兴趣点标签,如图2所示。
图2

总结:
1、建模( Y 结、L 结、T 结以及微小椭圆的中心和线段端点)+ Synthetic Shapes 》》MagicPoint
2、MagicPoint + 无标签图 》》 pseudo-ground truth 图
3、SuperPoint + pseudo-ground truth 图 》》 特征点图
建模可以理解为,用数学的方法找了一些特征点
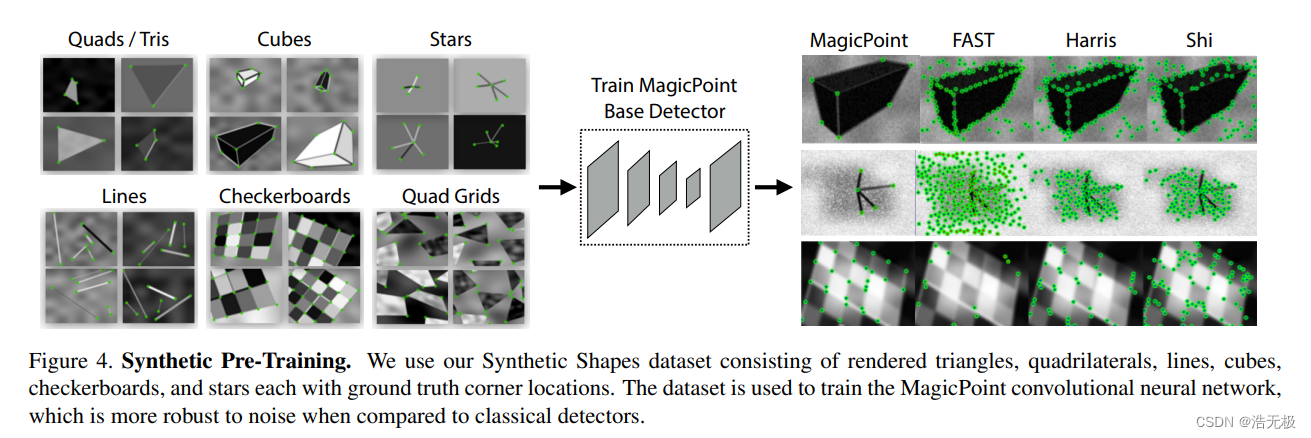
4.1 Synthetic Shapes
以前没有兴趣点的大型数据集。所以,先创建一个叫Synthetic Shapes的大型合成数据集,如图4所示。在此数据集中,通过使用简单的 Y 结、L 结、T 结以及微小椭圆的中心和线段端点对兴趣点进行建模来消除标签歧义。
渲染合成图像后,我们对每个图像应用 homographic warps 以增加训练示例的数量。数据是动态生成的,网络不会看到两次示例。虽然Synthetic Shapes中表示的兴趣点类型仅代表现实世界中发现的所有潜在兴趣点的子集,但我们发现当用于训练兴趣点检测器时,它在实践中运行得相当好。
批注:Synthetic Shapes代表数据集,后面均不做翻译
图4
4.2 MagicPoint
我们使用SuperPoint架构的编码器部分(忽略描述符部分)并在Synthetic Shapes上对其进行训练。我们将生成的模型称为MagicPoint。有意思的是,当我们用MagicPoint和其他传统的角点检测器在Synthetic Shapes数据集比较的时候,如FAST,Harris,Shi-Tomasi 角点检测器。我们的MagicPoint是最好的,如表二所示。
批注:父母生出的孩子对父母最熟悉不是很正常吗??难道小三,小四更了解父母的事情,小三小四是同辈的【dog】【dog】【dog】
表二

MagicPoint能否对真实图片也能产生良好的效果呢?我们的回答是yes,但没有想象中那么好,在7.2节将详细描述。MagicPoint在真实世界表现很好,特别是在有窗户,桌子,椅子一些的地方(MagicPoint果然是亲生的,像父母)。不幸的是,在所有自然图像的空间中,与相同的经典检测器相比,它在视点变化下的可重复性方面表现不佳。所以,我们提出 Homographic Adaptation 解决这个问题。
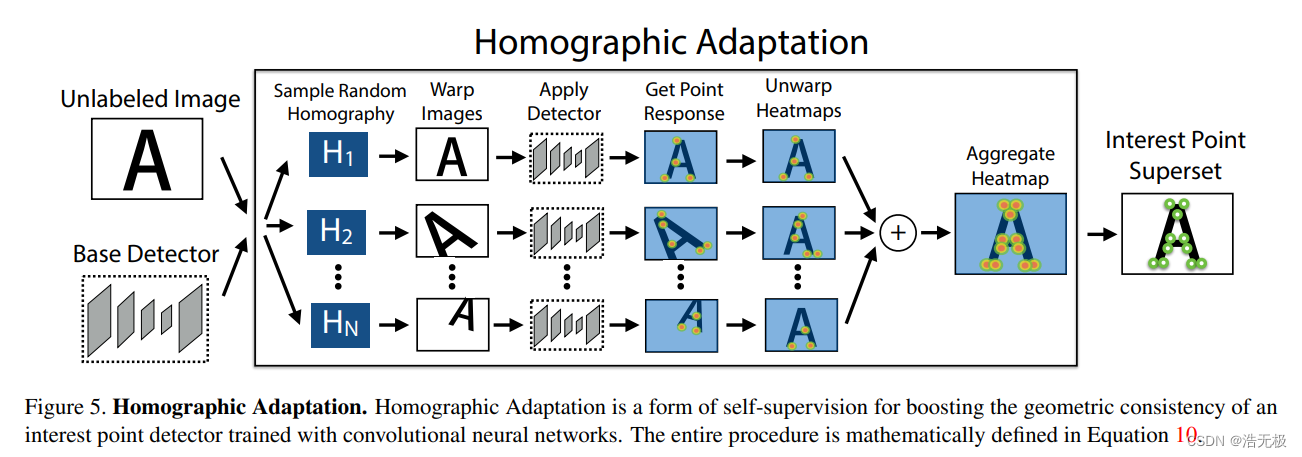
5 Homographic Adaptation
首先,在每个目标领域我们生成一个pseudo-ground truth兴趣点位置。然后,我们使用传统的监督学习机。核心在于,我们使用random homographies随机翻转图片,然后通过 MagicPoint 检测出角点,将每幅图的角点累加到结果图上,就得到了Interest Point Superset(兴趣点超集)。如图5所示,结合图应该很好理解。
原句:At the core of our method is a process that applies random homographies to warped copies of the input image and combines the results – a process we call Homographic Adaptation (see Figure 5).
批注:以后关键的句子,我同时保留原句在附近,因为有些翻译真的不能很好表达原意。
图5
5.1 计算
批注:这部分看原文比较好,比较简单。
Let fθ(·) represent the initial interest point function we wish to adapt, I the input image, x the resulting interest points and H a random homography, so that:
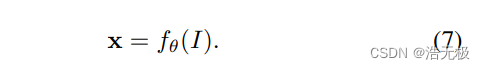
由于 covariant 这个性质,可有:
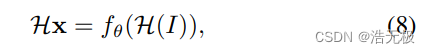
变形得:

(9)式是理想的公式,实际上是:
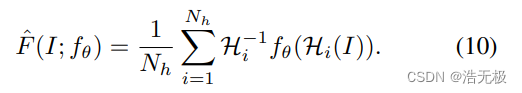
5.2 选择Homographies
对于Homographic Adaptation,3x3并不全是最好的选择,应该包括相机的所有可能的操作。将 Root Center Crop,叠加图6的所有操作,然后得到 Random Homographic Crop。
图6
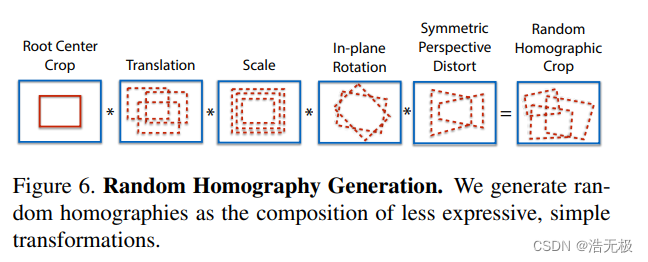
有一个Nh的超参,代表Homographies的个数,一般会做一个Nh = 1的对照实验,相当于没有做Homographic Adaptation。经过实验发现,Nh>100后,收益开始减少,因此,我们至少应该让这个参数选择100。
5.3 迭代Homographic Adaptation
图7 经过一些迭代的结果图,最上面一行是初始MagicPoint的结果,下面是经过越来越多迭代的图。

6 实验细节
这部分不要了!
7 实验结果
Repeatability is computed at 240 × 320 resolution with 300 points detected in each image.
表3
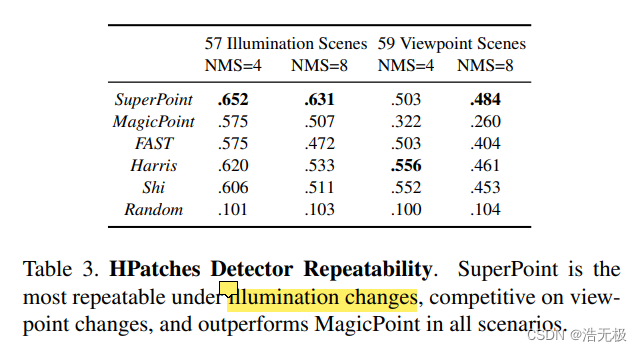
表4
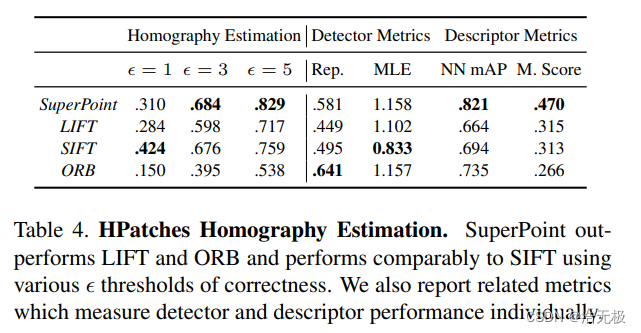
repeatability (Rep.)
mean localization error (MLE)
nearest neighbor mAP (NN mAP)
matching score (M. Score)
占个坑!等有空把这里的指标看懂。前面的内容已经可以理解这篇文章的核心思想,这次的论文阅读适当删减,不做全文翻译了!
快速看论文的tricks:
1、找到核心机制,查看原文解释,弄懂原理
2、图和文字说明结合
3、对应性能和一些吹嘘的话,适当跳过














 1257
1257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









