







目录
首先说明一下数据类的岗位在大厂是会再细分,具体有数据工程、数据分析、数据科学这三大类。本人是在数据工程方面多一些。大数据开发在我们这边叫数据工程,其工作内容本质上没有什么区别,只是叫法不一样而已。
数据工程的定义:基于对业务和数据的理解,通过各种技术和管理手段,不断提升数据接入、建模效率以及数据质量(一致性、准确性、合规性、重复性、及时性、完备性),满足各种数据消费和应用场景的数据分析和挖掘需求。
一、本人大数据工作内容?
早上,我一般会选择坐公司的班车(偶尔睡晚了也会坐地铁)。差不多8点40分左右到公司会先吃早餐。
休息片刻大概9点去健身房锻炼一下身体。主要是想通过适当的运动,让身体更加放松、健康,同时还可以甩甩脂肪控制体重,最近这段时间通过运动由67KG减至61KG了。这里也分享一下我个人的感受:运动期间听听歌、或者看看新闻,出出汗,整个身心更加舒服~ 运动完后我一般都会安静下来休息一下,再冲个澡儿。
9:50左右到办公位,开始一天的工作;10点左右会有一个小组晨会,汇报一下最近几天的工作情况、遇到的问题以及接下来要做的事情,这个晨会我个人是觉得挺好的,小组团队成员也能够彼此了解到大家的工作内容,同时也能方便Leader传答一下最近的项目规划。晨会后就是开启一天的工作啦,我本人有个习惯就是好好打杯温水慢慢喝,边想一天需要干的事情,怎样工作效率高一些~ 12点左右开始去吃午饭,12:00~14:00是休息时候(含吃饭);下午也是类似的工作节奏;到了下午6点开始晚饭;晚上8点左右下班,有时我也会6点下班;一天下来还是挺累的。好在是双休,加上自己的一些工作节奏调整,整体下来工作节奏还可以把控得住~
- 检查一下核心的报表、负责的核心链路是否正常;
- 打开需求文档,看看有没有还没有完成好的需求,跟需求方了解详细诉求;
- 期间会不定期地接收新的业务需求、业务反馈、Leader需求【这个频率不会很高】
本人大部分时间及精力是花在理解需求,拆解功能,考虑数据架构、模型,这个时间占整个项目周期的70%,剩下的时间是在开发、测试;我本人实时任务、离线数据仓库都做;离线的项目则可在公司的数据平台 (这个很依赖于公司的基建能力) 上直接写SQL脚本,写好后会提交到任务调度平台进行任务依赖配置即可;实时需求会复杂一些,涉及的技术栈比较多,我们一般会采用Flink + Kafka + Apache Druid + Bi可视化;
除了上述外,本人还参与数据治理、数据驱动、数据报表设计,为部门团队成员提供全面的数据服务。
- 离线开发:主要是存储Hadoop作为数据存储,hive管理库表/字段信息与Hadoop存储进行关联,使用MapReduce、Spark、Presto作为分析计算引擎
- 实时开发:前几年还有在用SparkStreaming,现在基本全部是flink了
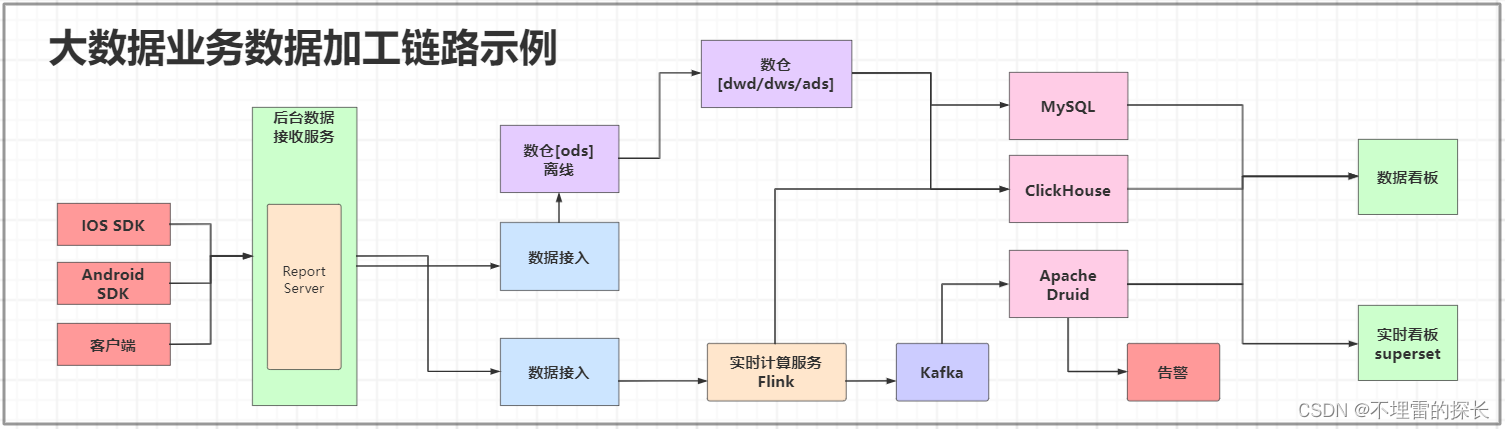
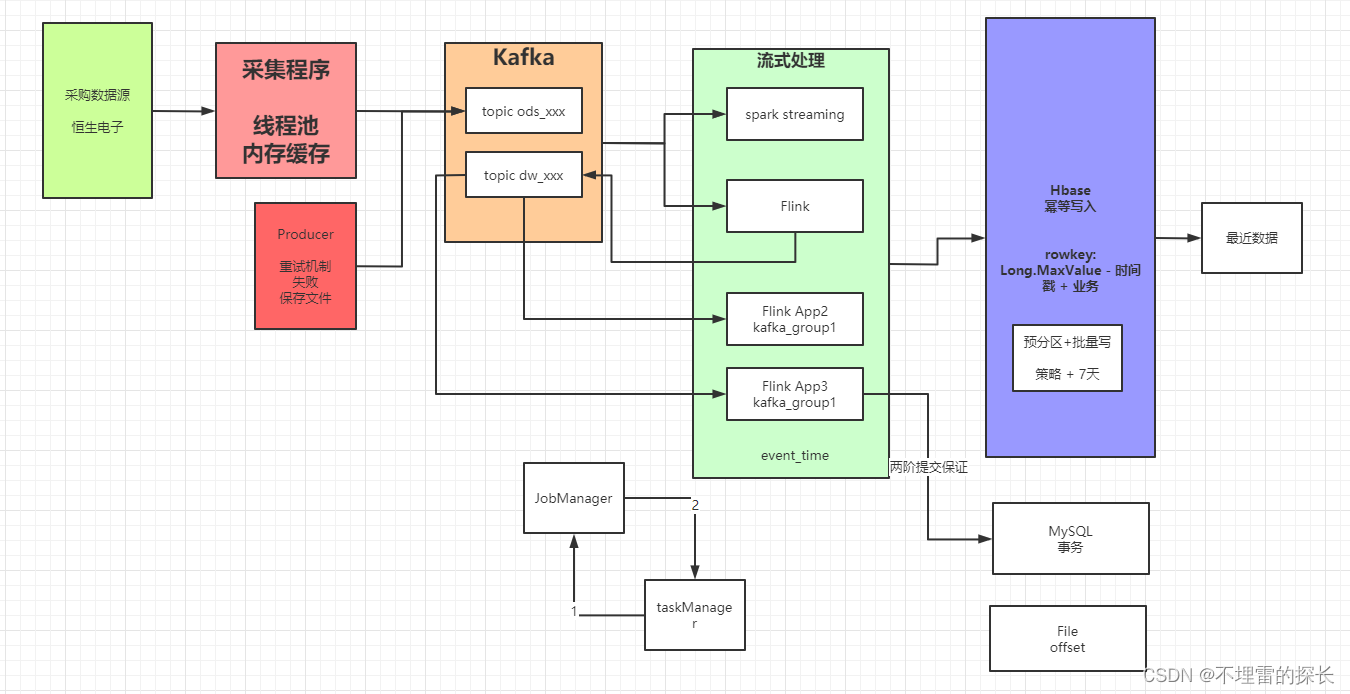
下面是我平时画的架构图,也供大家一起交流分享
二、高级/资深大数据架构涉及哪些内容?
在大厂中有很多实力强劲的大佬,他们对大数据有更全面、更体系、更深入的认识,往往在团队中起到顶梁柱的作用;这些大佬,不仅仅是业务上的负责人更多的是引领团队朝正规化的方向发展。现在来看看这种类型的大佬应该具备怎样的技能~
掌握并在企业实战实时计算平台、离线数仓平台、离线和实时数据质量QDC建设、统一埋点与统一指标建设、数据字典与数据血缘管理关系、调度平台、数据湖与数仓、数据应用服务及数据可视化 等,探索大数据云原生化部署建设
实时计算类:Flink, Spark Streaming, Apache Beam, Storm, Kafka Streaming, Streaming SQL等 平台建设, 深入掌握flink可完成定制改造源码做平台化建设、实时应用类深度开发,曾基于业务需要修 改flink cep模块让其支持动态CEP规则
OLAP分析引擎类:Apache Kylin、Apache Druid、Pinot、ClickHouse等,熟悉基于Apache Druid进行OLAP准实时分析技术,能完成Dimension和Metric的构建;使用clickhouse构建明细 +汇总的OLAP查询引擎,百亿数据秒级返回,支持自由定义维度和度量
实时数据湖:apache iceberg,apache hudi等,使用iceberg构建增量实时数据湖,解决企业PB 级海量数据存储和高速计算问题
实时数仓、离线数仓:深刻理解离线数仓ODW,DWD,DWS,DM,APP,DIM等分层建设思路,掌握基 于one data,one service,one model的数据中台建设方法论,并用于企业实战,曾经维护每日增量 100TB离线任务5000+的离线数仓;熟悉基于Kappa架构批流一体实时数仓设计,并能够集合数据 资产完成离线和实时元数据统一化管理,从底层计算引擎设计实时和离线的统一平台,曾经维护 1000+任务的实时计算平台
实时检索与存储系统:HBase、ElasticSearch、Redis、Phoenix等,掌握Hbase架构与使用,完成基于Hbase的二级索引建立,提高查询效率,能与ElasticSearch整合,完成分布式搜索引擎搭建
ELK日志套件:Flume、FileBeat、Logstash、ElasticSearch、Kibana
MQ消息队列:Apache Kafka、Apache Pulsar、RocketMQ、Tencent Tube
数据应用服务:数据自助报表建设(supserset、davinci),数据服务open api建设,数据脱敏及细 粒度权限控制
数据迁移工具,掌握Sqoop、阿里Datax、FlinkX,完成数据以分布式方式在不同存储介质间迁移, binlog+canal数据库数据变更流抓取和处理转换
机器学习类:可根据Spark和Alink提供的机器学习套件做模型训练、模型server服务
大数据运维类:可运维千台规模集群,集群容量规划、扩容及集群性能和资源利用率,可以做集群的 运维工作包括但不限于hdfs/Hbase/Hive/kudu/TIDB/Yarn/Spark/flink/hudi等,确保高可用性运行;熟悉容器和服务部署维护,自动化构建
数据驱动业务:掌握体系化“第一关键指标法”、海盗指标模型等数据分析方法,结合业务运用数据 SDAF闭环提升业务营收,曾经在广告业务领域通过数据驱动每年提升收入数亿人民币;数据结合策略指导智能营销,建设精细化DMP数据管理平台,构建商业标签体系。
三、大数据学习路线
- (必学)需要先掌握 Java SE 阶段,Linux 基础命令(建议安装 CentOS),MySQL数据库
- (必学)学习Hadoop生态(zk、hadoop、hive、hbase、kafka、spark、flink等)
- (选学)机器学习、人工智能
| 序号 | 英文名称 | 中文名称 | 功能描述 | 特点 | 现状 | 要求 | 书籍、或视频 |
| 1 | Hadoop | 分布式文件系统 | 文件数据存储 | 稳定、成熟 | 因很成熟,开箱即用 | 一般,能使用即可 | |
| 2 | Hive | 分布式SQL | 将SQL转成MapReduce分析 | SQL化,简单易用 | 因很成熟,开箱即用 | 一般,能使用即可 | |
| 3 | Hbase | 分布式BigTable | 时序列式数据库 | 支持数据量大的存储 | 因很成熟,开箱即用 | 如果招聘有要求,最好是源码级别 | 《HBase不睡觉》 |
| 4 | Kafka | 分布式消息中间件 | 实时数据中间缓冲 | 稳定、支持事务 | 因很成熟,开箱即用 | 重要,基本要求熟练掌握 | |
| 5 | ElasticSearch | 分布式搜索引擎 | 全文检索,类似于百度搜索 | 因很成熟,开箱即用 | 如果招聘有要求,最好是源码级别 | ||
| 6 | Spark | 分布式分析引擎 | 基于内存的分布计算框架,比MapReduce快很多;可离线、可近实时 | 稳定、市场占有率超高 | 因很成熟,开箱即用 | 重要,最好是源码级别 | |
| 7 | Flink | 分布式流式处理 | 真正意义上的分布式实时流处理 | 未来趋势 | 比较成熟,开箱即用 | 重要,最好是源码级别 | |
| 8 | Apache Druid | 分布式时序数据库 | 会进行预聚合的时间数据库 | 可预聚合,减少数据存储 | 比较成熟,开箱即用 | 一般,会使用即可 | |
| 9 | ClickHouse | 分布式数据库 | OLAP分布式分析 | 快、SQL化 | 一般,会使用即可 |
|
专业能力项
|
能力项描述
|
|
数据规划治理
|
规划并实施数据采集、处理、计算的全流程管理能力,以持续保障和提升数据成熟度水平,改进数据质量、安全合规性和资源利用率
|
|
数据仓库技术
|
建设面向业务主题和应用场景的数据仓库,用于数据分析和决策支持
|
|
大数据技术架构
|
通过大数据技术架构设计、组件选型与改进,构建最优的大数据处理系统,满足业务数据采集、传输、存储、计算、应用等对技术指标(性能、效率、质量等)诉求
|
|
数据应用工程
|
在业务/行业的分析、决策、实验和算法等场景,实现数据应用系统的工程化落地,以提升业务/行业数据应用效率或数据驱动决策水平
|
四、送给在学习路上的小伙伴一些建议
-
要多思考 ,这个技术点为什么这样实现,有什么好处,多思考会让大脑越来越灵活
-
要多交流 ,跟身边的同学或高手多交流学习,遇到一些没有理解的知识通过相互交流学习也是一种很好的方式
-
要多做笔记,我个人就是喜欢多做笔记;因为大数据知识体系复杂且繁多,通过在学习过程中将核心知识点记录起来
-
要多画图,多画架构图、原理图;比如:Spark架构图、Flink架构图等等;这样学习起来也会更容易理解一些
-
要多做项目,最终通过真实项目将知识体系串连起来形成一张完整的技术栈网
-
要多读书,建议可以读读一些大数据技术栈类的书籍,这个技术巩固会更扎实
这里也借此机会,特别感谢我在大厂里的伟少导师,他是一位非常非常优秀架构师!也是我生活中一位十分要好的朋友~
最后,祝大家技术日益增强,早日进大厂。

如果觉得文章还不错,欢迎关注、点赞、收藏哈~



















 2207
2207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











