






用户行为路径分析定义
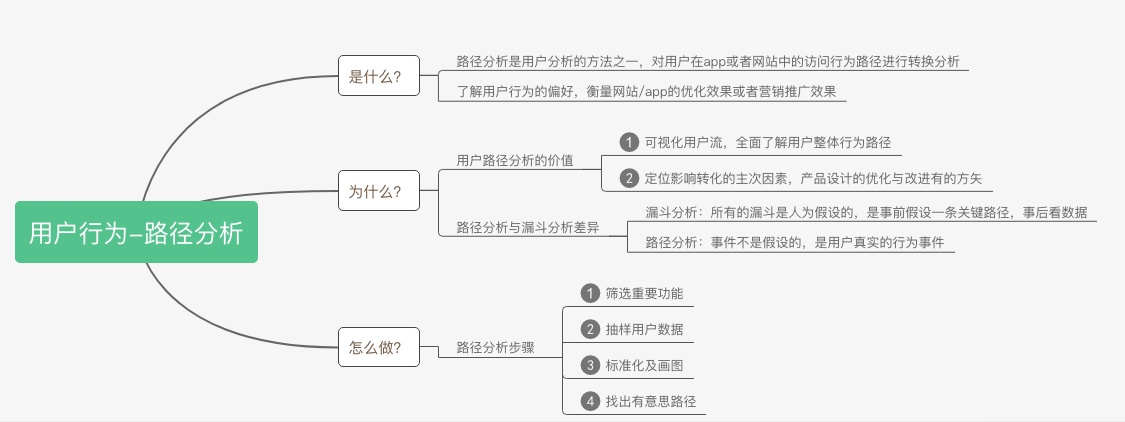
路径分析是用户行为分析的方法之一,对用户在App或者网站中的访问行为路径进行转换分析,了解用户的行为偏好,衡量网站/app的优化效果或者营销推广效果。
用户路径分析的价值
- 可视化用户流,全面了解用户整体行为路径
通过路径分析,可以将一个事件从上游到下游进行可视化展示。简单来说用户进入app/网站后,所有的操作路径都会按时间顺序记录下来。运营人员可以根据用户整体的行为路径来找到不同行为之间的关系,挖掘规律找到运营规律。
- 定位影响转化的主次因素,产品设计的优化与改进有的放矢
一个产品通常是由很多产品经理协同完成的,各子模块产品功能组合成一个上线的产品。但是产品设计的合理不合理,各功能模块放的位置合理不合理,这都是未知的。对用户进入产品后的路径进行统计分析,根据各个环节的转化率,发现用户的行为规律和偏好,可以对产品进行有的放矢的迭代和优化。
路径分析与漏斗分析的区别
我们在流量分析里面提到漏斗分析,漏斗模型是一种经典的分析方法。_但是所有的漏斗都是人为假设的,也就是事前假设一条关键路径,事后看数据_。漏斗分析中的假设就非常关键了,漏了关键环节或者增加不必要的环节都会对漏洞分析的结果产生不好的影响。
路径分析是根据用户前后行为,发现产品设计初可能不知道的事情,这就是路径分析。_路径分析中的事件不是假设的_,我们可以理解为用户进入我们的产品后,用户真实的操作行为路径会被记录下来。产品运营/数据分析来统计分析这些路径,根据用户前后行为的变化,发现产品设计/运营方式上可能不知道的事情。
简单概括为:
- 漏斗分析:人为设定一条或者若干条漏斗,先有假设再数据验证。
- 路径分析:基于用户所有行为,挖掘出若干条重要的用户路径,通过优化界面交互让产品用起来更加流畅和符合用户习惯,产出更多价值,先有数据再验证假设。
路径分析步骤
- 筛选重要功能(是什么)-查看所有功能用户量级,筛选出重要功能,作为路径点。
- 抽样用户数据(怎么做)-用户日志数据很多,那么我们怎么选取数据进行分析就很重要了。先时间序列排序用户行为,再关联功能间数据,得到我们需要的数据。
- 标准化及画图(探索)-标准化是指对数据进行标准化,以便对于各功能模块的使用情况。根据用户访问的路径,将路径画出来。
- 找出有意思路径(发现)-根据第三步画出来的路径图,我们可以找到各路径点使用情况,找到有意思的路径。将结果与产品运营反馈,构成一个分析闭环。
まとめ
假设你开了一家玩具店,很多小朋友进店这个玩具玩一下,哪个玩具摸一下,最好离开了。你可以根据小朋友的前后动作分析哪些玩具被玩的多,哪些玩具被玩的少,根据这些统计可以改变玩具摆放布局或者玩具设计等。路径分析就是分析各产品功能模块的渗透率(使用情况),安排的合理不合理。一个复杂的产品需要很多产品经路,产品经理只关注自己的一点,数据分析师可以站在更高的高度,全盘思考,分析各功能模型使用情况,为产品/运营提供建议。
附件我做了一个简单的思维导图,将全文总结了一下,后续有心得体会会在此基础上进一步完善和更新。
Reference:[用户行为-路径分析 | ProcessOn免费在线作图,在线流程图,在线思维导图]















 4269
4269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









