






本文提出了Imagen Editor,一个通过在文本引导图像修复上微调 Imagen 构建的级联扩散模型。同时,为了改进定性和定量评估标注,还引入了一个文本引导图像修复的系统基准EditBench。Imagen Editor在训练过程中的对象遮蔽可以全面改进文本-图像对齐,效果优于 DALL-E 2 和 StableDiffusion。 Google提出
论文地址:https://arxiv.org/abs/2212.06909
项目地址:https://imagen.research.google/editor/
回忆一下小时候看的魔术:魔术师用一块布遮住空空如也的桌子,大喊一声:变出一个鱼缸。等把布掀开,鱼缸已经出现在桌面上。而这样的魔术最近在图像生成领域已经实现,Google Research就是那个“魔法师”。具体来说,基于文本的图像编辑对于支持创意应用具有转变性的影响。然而,生成与输入图像一致且与输入文本相符是个困难的问题。
为此,作者提出了 Imagen Editor,这是一个cascaded diffusion模型,能够让用户如同变魔术般操作图片。它通过在训练过程中使用目标检测器提出“修复蒙版”来生成符合于给定文本提示的编辑。此外,它通过在cascaded pipeline中使用原始高分辨率图像进行条件化来捕捉输入图像的细节。同时,为了改进定性和定量评估标注,作者引入了一个系统化基准 EditBench,用于对自然和生成图像上的修复编辑进行评估,探索对象、属性和场景等因素。
通过在EditBench上进行广泛的人类评估,作者发现,在训练过程中使用object-masking技术可以显著提高文本和图像之间的对齐性。因此,相对于 DALL-E 2 和Stable Diffusion,Imagen Editor效果更好。我们的评估还表明,这些模型更擅长对象呈现而不是文本呈现,并且更擅长处理材料/颜色/大小属性而不是数量/形状属性。下图初步展示了Imagen Editor的能力。

Introduction
作者首先调研了图像生成领域。近些年,文本-图像的生成任务引起了广泛的关注(如DALL-E 2 和Stable Diffusion)。虽然这些生成模型非常有效,但是作者认为,具有特定艺术和设计需求的用户通常无法在与模型的单次交互中获得期望的结果。基于文本的图像编辑可以通过支持交互式的细化过程来增强图像生成体验。而作者关注的任务是文本引导的图像修复,其中用户提供一张图像、一个掩膜区域和一个文本描述,紧接着想要的物体就会出现在掩膜区域,使其与文本提示和图像环境一致。这个工作补充了无掩蔽区域的编辑,具有局部编辑的精度。作者的贡献是 Imagen Editor,它是一个基于文本的图像编辑器,结合了大规模语言表示和精细控制,产生高保真度的输出。Imagen Editor 是一个级联扩散模型,通过对 Imagen 进行微调来实现。
在文本引导的图像修复中,一个关键挑战是确保生成的输出和文本提示相符合。与文本到图像生成类似,可能出现的错误模式包括将属性(例如颜色)绑定到错误的对象,省略、虚构或复制细节,错误计数等,而这些错误的可能性随着提示复杂度的增加而增加。标准的训练过程使用随机掩蔽的输入图像区域。作者认为这会导致图像和文本之间的弱对齐,因为随机选择的区域通常可以仅使用图像上下文合理修复,而不需要太多关注提示。作者提出了一种新颖的“object masking”技术,它在训练过程中鼓励模型更多地依赖于文本提示(如下图所示)。这有助于使 Imagen Editor 更易于控制,并显著改善文本和图像之间的对齐性。

同时,作者观察到没有专门设计的标准数据集来评估文本引导的图像修复,因此作者提出了EditBench,这是一个手工筛选的评估数据集,涵盖了各种语言、图像类型和难度级别。每个 EditBench 样本由以下三部分组成:
(i) 带掩膜的输入图像,
(ii) 输入的文本提示,
(iii) 高质量的输出图像
作者在EditBench上探索了 Imagen Editor、Stable Diffusion 和 DALL-E 2的效果。人类评估者被要求评价以下几点:
(1) Text-Image Alignment -- 文本提示被实现的程度(整体上和评估每个对象/属性的存在情况)
(2) Image Quality -- 与文本提示无关的视觉质量。
就文本-图像对齐而言,使用目标掩膜进行训练的 Imagen Editor 在与使用随机掩蔽进行训练的对应配置进行比较时更受人类评估者的青睐,在所有对象和属性类别中都有显著的改进。模型在对象呈现方面比文本呈现方面表现更好,并且处理材料/颜色/大小属性要比数量/形状属性好。
Method
Imagen Editor是一个文本引导的图像修复模型,旨在改进语言输入的表达和反映、细粒度控制和高保真度输出。Imagen Editor从用户处获取三个输入:(1)待编辑的图像 (2)用于指定编辑区域的二进制掩模 (3)文本提示 所有这些输入都用于引导输出样本。具体描述如下图所示。
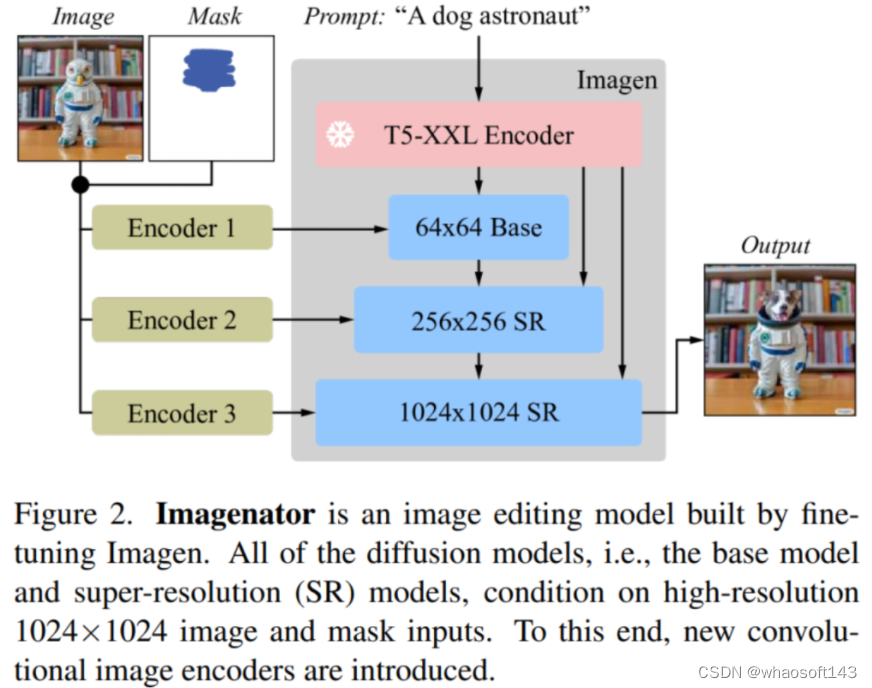
Imagen Editor
作者的思考始于这个问题:应该使用什么样的遮罩来训练文本引导的图像修复模型?遮罩区域应该与编辑文本提示对齐。理想情况下,我们会有一个大型专家数据集,其中包含对齐的遮罩-提示编辑,用于训练;然而,这样的数据集并不存在,而且策划一个大型数据集将会很困难。一个自然、简单的策略是使用随机遮罩分布,例如随机框或随机笔画遮罩;这已经成功地应用于先前的修复模型。然而,在训练期间使用随机遮罩时,它们可能覆盖与文本提示无关的区域(图3左)。在这样的例子上进行训练可能会鼓励模型忽略文本提示。作者发现,当遮罩区域很小或只部分覆盖对象时,这个问题尤其普遍,这也类似于CogView2的观察结果。
与简单的文本无关修复不同,作者需要生成的区域(从遮罩中)不仅要真实,还要与输入的文本提示相互关联。因此作者提出了一个简单而有效的解决方案。假设完全遮盖已识别的对象将在很大程度上与文本提示重叠,因此鼓励模型在修复时更多地关注文本提示。作者使用一个现成的对象检测器来检测和定位对象,并使用这些边界框来生成在训练期间使用的遮罩。文中使用的模型是轻量级的SSD Mobilenet v2 ,可以轻松地实时运行,因此提供与随机遮罩策略相同的灵活性。我们的实验结果表明,这种遮罩策略的简单修改效果出奇地好,减轻了大多数随机遮罩策略训练的模型所面临的问题。。
High-Resolution Editing
在Imagen Editor中,作者修改了Imagen,使其通过在通道维度上将图像和掩膜与diffusion latents连接起来,类似于SR3、Palette和GLIDE,以同时作用于图像和掩膜。Imagen Editor 的输入图像和对应掩膜始终以 1024×1024 分辨率输入。基础扩散 64×64 模型和 64×64→256×256 超分辨率模型以较低分辨率操作,因此需要一些形式的下采样以匹配diffusion latent分辨率(例如 64×64 或 256×256)。一种方法是使用无参数下采样操作(例如双三次插值);而作者改用带参数的下采样卷积(例如带步幅的卷积)。在最初的实验中,作者发现这种带参数的下采样操作对于高保真度至关重要。简单的双三次插值下采样会在最终输出图像的掩膜边界处产生明显的伪影,而使用带参数的下采样卷积会产生更高的保真度。作者还将相应的新输入通道权重初始化为零;这意味着在初始化时,模型与Imagen相同,因为它忽略了条件图像和掩膜。
Classifier-Free Guidance
Classifier-Free Guidance是一种将样本偏向于特定条件(例如文本提示)的技术,代价是模式覆盖不足。CFG已被发现对于提高文本-图像对齐和文本→图像模型中的图像保真度非常有效。我们发现CFG对于确保文本引导的图像修复模型中生成的图像与输入文本提示之间的强对齐仍然至关重要。我们遵循Imagen video的做法,使用高引导权重和引导振荡。在基础模型中,确保与文本的强对齐最为关键,我们使用一个引导权重计划,其在1和30之间振荡。我们观察到,高引导权重与振荡引导相结合可以在样本保真度和文本-图像对齐之间取得最佳的平衡。
EditBench
EditBench是一种作者制作的基于240张图像的文本引导图像修复基准。每张图像都配对一个遮罩,指定需要通过修复修改的图像区域。对于每个图像-遮罩对,作者提供了三个不同的文本提示,代表了指定编辑的不同方法(见下图)。与用于文本到图像生成的DrawBench和PartiPrompts基准类似,EditBench是手动编辑的,以捕捉各种类别和难度方面的广泛内容。可以用于后续生成模型的评价。

讨论
总结一下,作者提出了Imagen Editor和EditBench,这两项工作在文本引导图像修复以及其评估方面都取得了显著进展。Imagen Editor是从Imagen微调而来的文本引导图像修复模型。Imagen Editor的关键在于添加新的卷积层以实现高分辨率编辑,并使用对象掩膜策略进行训练。EditBench是一个全面系统化的文本引导图像修复基准。EditBench系统地评估文本引导图像修复的多个方面:属性、对象和场景。作者发现,在人类评估和自动度量方面,Imagen Editor在EditBench上表现优于DALL-E 2和Stable Diffusion。















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









