







1: 本地存储方式
2: 内置查询语言分析
3: 性能分析
4: 图算法支持
本地存储方式
Neo4J
neo4j数据库支持最大多少个节点?最大支持多少条边?
目前累积统计它有34.4亿个节点,344亿的关系,和6870亿条属性。
在数据库中,读/写性能跟节点/边的数量有关吗?
这个问题意味着两个不同的问题。单次读/写操作不依赖数据库的大小。不管数据库是有10个节点还是有1千万个都一样。 — 然而,有一个事实是如果数据库太大,你的内存可能无法完全缓存住它,因此,你需要频繁的读写磁盘。虽然很多用户没有这样大尺寸的数据库,但有的人却有。如果不巧你的数据库达到了这个尺寸,你可以扩展到多台机器上以减轻缓存压力。
是否有备份恢复机制?
Neo4j 企业版提供了一个在线备份(完整备份和增量备份)功能。
写数据库是线程安全的吗?
不管在单服务模式还是HA模式,数据库在更新之前都通过锁定节点和关系来保证线程安全。
文件存储结构
node,relationship,property存储都是固定大小的。 如下图:
固定大小可以快速查找,基于此,可以直接计算一个节点的位置,时间复杂度$O(1)$,比查询的$O(log n)$快。
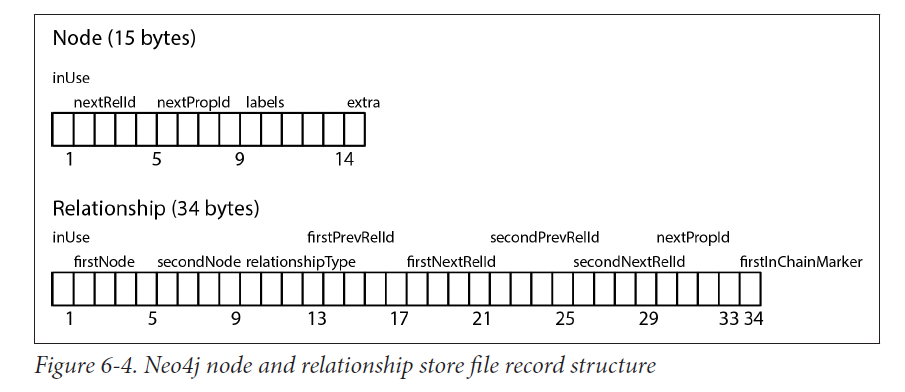
image.png
节点
存储文件neostore.nodestore.db,
第一个字节,是否被使用的Flag
下4个字节,代表第一个关系的ID,连接到这个节点上的 :ID
紧接着的4个字符,代表第一个属性ID,连接到这个节点上的
紧接着的5个字符是代表当前结点的Label,指向Label存储的。 :LABEL
最后一个字符是标志字符,用来标志紧密相邻的点,或者留备后用。 这就是Neo4J索引实现的方案。Index-Free Adjacency
这些指向的ID都是链式ID中的第一个,比如关系ID是关系链中的第一个。
关系
存储文件neostore.relationshipstore.db
1:同上
1-5:第一个节点
5-9:第二个节点
9-13:关系类型 :TYPE
13-21:前一个关系的前后节点 ID
21-29:后一个关系的前后节点 ID
29-33:属性ID
34:是都是关系链中的第一个的标志
关系是双向链表,属性是单向链表
属性文件
存储文件neostore.propertystore.db
每个属性文件包含4个属性块,一个指向下个属性的ID,在属性链中
属性包括属性类型,指向属性索引文件neostore.propertystore.db.index的指针
属性是键值对存储的,数据类型可以使用JVM的所有私有属性,加上字符串和数组类型;
属性值也可以使用动态存储,就是大文件,类型如下:字符串&数组
查找时文件调用模型
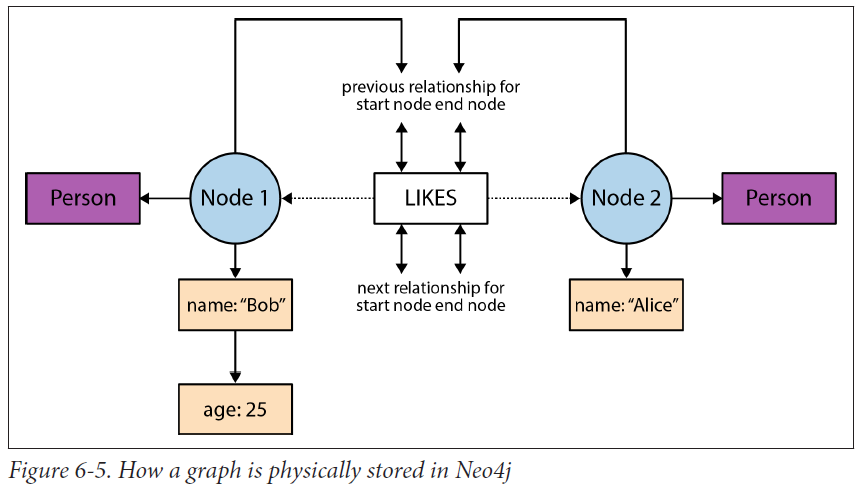
image.png
节点包含指向关系链和属性链的第一个指针。
指向Label的指针,可能多个。
属性读取从单向链表的第一个开始
关系读取直接在双向链表中查找,直到找到想要的关系。
Index-Free Adjacency
查询时,算法复杂度,$O(n)$,$n$是节点数,其他常规索引的复杂度都是$O(n log n)$
删除修改一个有很多很多边的节点时会有点麻烦,因为没有常规索引,只能从关系链中开始删除。
为了去除所有的事件边,你必须访问每个相邻的顶点,并且为每个相邻的顶点执行一个潜在的昂贵的移除操作。
ArangoDB
文档在ArangoDB中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









