







 (以下内容均来源于 CS 294 Lecture 8)首先我们假设环境是确定性的,即在某个状态执行某个动作之后,转移到的下一个状态是确定的,不存在任何随机性。而在这种情况下,我们想做的是在环境给了我们一个初始状态的条件下,根据我们需要完成的任务以及环境模型,直接得出从初始状态到任务完成状态中间最优的动作序列。因为环境是确定的,而我们又已知环境模型,因而以上想法是自然且可行的。下图展示了我们想做的事...
(以下内容均来源于 CS 294 Lecture 8)首先我们假设环境是确定性的,即在某个状态执行某个动作之后,转移到的下一个状态是确定的,不存在任何随机性。而在这种情况下,我们想做的是在环境给了我们一个初始状态的条件下,根据我们需要完成的任务以及环境模型,直接得出从初始状态到任务完成状态中间最优的动作序列。因为环境是确定的,而我们又已知环境模型,因而以上想法是自然且可行的。下图展示了我们想做的事...
(以下内容均来源于 CS 294 Lecture 8)
首先我们假设环境是确定性的,即在某个状态执行某个动作之后,转移到的下一个状态是确定的,不存在任何随机性。而在这种情况下,我们想做的是在环境给了我们一个初始状态的条件下,根据我们需要完成的任务以及环境模型,直接得出从初始状态到任务完成状态中间最优的动作序列。因为环境是确定的,而我们又已知环境模型,因而以上想法是自然且可行的。下图展示了我们想做的事情:
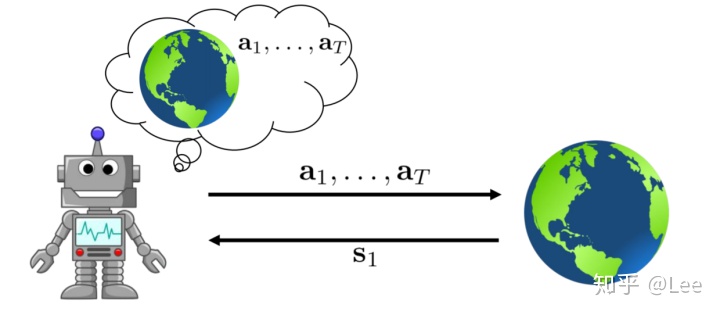
现在我们将以上问题抽象成一个正式的优化问题:
其中
但是在随机环境下,解决与确定环境的类似的如上优化问题并不能得到与确定环境一样的最优解。原因在于我们只接受环境反馈回来的初始状态,接着便凭借着我们掌握的环境模型在脑海中进行规划。这种方法在确定环境下没有任何问题,但在随机环境下,智能体实际会转移到的状态可能并不符合我们的预期,因为它是从一个条件状态分布中随机采样的。而一旦从某一个状态开始与我们的预期产生偏差,那么后续的所有状态都会产生偏差,而我们设想的最优动作序列便不是最优了。从优化函数的角度来看,我们优化的只是一个期望值,而不是某一次随机采样的值。
我们把上述解决问题的方法叫做开环方法,与之对应的叫做闭环方法。那么这个“环”具体是指什么呢?具体示意图如下:
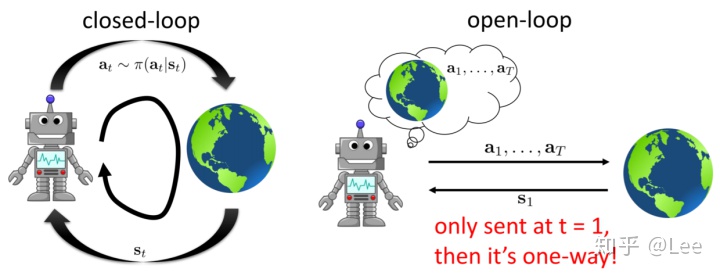
开环方法是只在最开始时接收环境反馈的初始状态,然后开始规划从开始到任务完成的过程中所经历的所有状态对应的最优动作,并不需要一个基于状态产生动作的策略;反之,闭环方法在每一个时间步都会接收环境反馈的状态,然后利用一个根据状态输出动作的策略来产生一个动作。我们可以看出,对于一个随机环境,闭环方法显然比开环方法更具优势,因为其可以根据所处的状态随时调整自己的动作。
但接下来我们还是首先假定一个确定性的环境,因而采用开环方法来解决上述问题。下面将介绍三种优化方法:随机优化方法、蒙特卡洛树搜索法以及轨迹优化方法。
随机优化方法
对于随机优化方法来讲,上述优化问题可以简化为如下等价优化问题:

随机优化方法完全不关系优化目标的特殊结构等信息,而是把任何优化问题都当作上图右半边这样的一般优化问题。
随即发射方法
最简单的随机优化方法就是随机瞎猜,即随机选择一个动作序列,然后评估其累积的代价。如上过程不断进行,最后选择一个累积代价最小的动作序列作为上述优化问题的最优解,因而这类方法也叫做“随机发射方法”:

CMA算法
但是这种方法在相对高维的情况下效率会很低,因为搜索空间太大但是目标区域比较小。回顾一下上述方法,我们可以在采样分布上做些文章。假设第一次从一个均匀分布采样一些动作序列之后,得到的累积代价分别为如下情况:
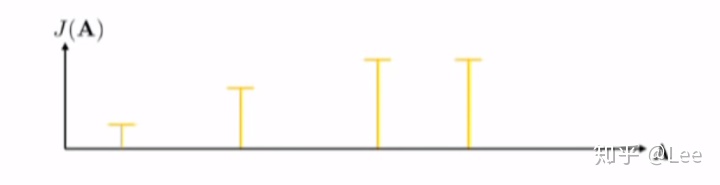
那么下一次我们可以不再继续从一个均匀分布中采样了,我们可以聚焦于累积代价较小(累积回报较大)的区域,然后估计那个区域的分布,在这里我们假设分布是一个高斯分布:
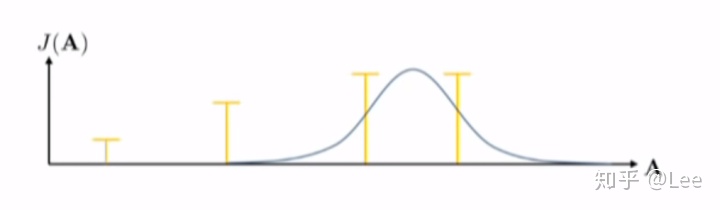
接下来的采样我们就从这个新的分布中进行采样:
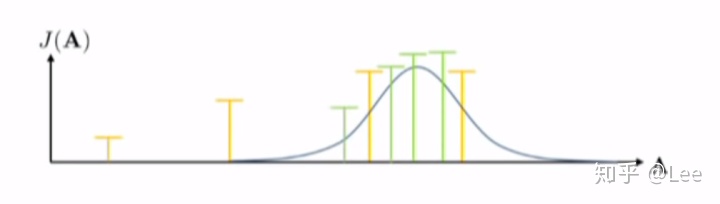
然后在下一次采样之前,我们再次聚焦于性能更好的区域然后估计其分布:

就这样不断迭代,直到满足停止条件。以上方法就是Cross-Entropy Method(CEM)算法,其伪代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









