







Decision Tree Classifier recursively generates rule to split data so as to minimize the impurity of each subset until every sample in subset belongs to the same class
from __future__ import division
import numpy as np
from sklearn.datasets import load_iris
from IPython.display import Image
from sklearn import tree
import pydotplus
data = load_iris()
X = data.data
y = data.target
class myDecisionTreeClassifier():
def gini(self, X, y, idx_data):
if idx_data.shape[0] == 0:
return 0
else:
p = 1
for v in np.unique(y):
y_sub = y[idx_data]
p -= (y_sub[y_sub==v].shape[0] / idx_data.shape[0])**2
return p
def split_data(self, X, y, idx_data, idx_feat, val_feat):
idx_left = idx_data[np.flatnonzero(X[idx_data][:, idx_feat] < val_feat)]
idx_right = idx_data[np.flatnonzero(X[idx_data][:, idx_feat] >= val_feat)]
return idx_left, idx_right
def best_split_data(self, X, y, idx_data):
igs = {}
for f in range(X.shape[1]):
for v in np.unique(X[:,f]):
idx_left, idx_right = self.split_data(X, y, idx_data, f, v)
gini_left = self.gini(X,y,idx_left)
gini_right = self.gini(X,y,idx_right)
igs[(f,v)] = (idx_left.shape[0]*gini_left + idx_right.shape[0]*gini_right) / idx_data.shape[0]
idx_feat, val_feat = min(igs, key=igs.get)
return idx_feat, val_feat
def build_tree(self, X, y, idx_data):
if idx_data.shape[0] == 0:
return None
node_tree = {
'idx_feat': None,
'val_feat': None,
'node_left': None,
'node_right': None,
'target': None
}
if np.unique(y[idx_data]).shape[0] == 1:
node_tree['target'] = np.unique(y[idx_data])[0]
return node_tree
idx_feat, val_feat = self.best_split_data(X, y, idx_data)
node_tree['idx_feat'] = idx_feat
node_tree['val_feat'] = val_feat
idx_left, idx_right = self.split_data(X, y, idx_data, idx_feat, val_feat)
node_tree['node_left'] = self.build_tree(X, y, idx_left)
node_tree['node_right'] = self.build_tree(X, y, idx_right)
return node_tree
def fit(self, X, y):
self.node_tree = self.build_tree(X, y, np.array(range(X.shape[0])))
def predict_single(self, node_tree, x):
target = node_tree['target']
if target != None:
return target
idx_feat = node_tree['idx_feat']
val_feat = node_tree['val_feat']
node_left = node_tree['node_left']
node_right = node_tree['node_right']
if x[idx_feat] < val_feat:
return self.predict_single(node_left, x)
else:
return self.predict_single(node_right, x)
def predict(self, X):
return np.array(map(lambda x: self.predict_single(self.node_tree, x), X))
def score(self, X, y):
return np.count_nonzero(self.predict(X) == y) / y.shape[0]
def plot_tree_level(self, node_tree, level):
idx_feat = node_tree['idx_feat']
val_feat = node_tree['val_feat']
node_left = node_tree['node_left']
node_right = node_tree['node_right']
target = node_tree['target']
if level == 0:
indent = '|--'
else:
indent = ' '*level+' |--'
if idx_feat != None:
print indent, data.feature_names[idx_feat], 'by', val_feat
else:
print indent, '[', data.target_names[target], ']'
return
self.plot_tree_level(node_left, level+1)
self.plot_tree_level(node_right, level+1)
def plot_tree(self):
self.plot_tree_level(self.node_tree, 0)
idx_data = np.array(range(X.shape[0]))
dt = myDecisionTreeClassifier()
dt.fit(X,y)
print 'score:', dt.score(X,y)
dt.plot_tree()
#score: 1.0
#|-- petal width (cm) by 1.0
# |-- [ setosa ]
# |-- petal width (cm) by 1.8
# |-- petal length (cm) by 5.0
# |-- petal width (cm) by 1.7
# |-- [ versicolor ]
# |-- [ virginica ]
# |-- petal width (cm) by 1.6
# |-- [ virginica ]
# |-- sepal length (cm) by 6.8
# |-- [ versicolor ]
# |-- [ virginica ]
# |-- petal length (cm) by 4.9
# |-- sepal width (cm) by 3.1
# |-- [ virginica ]
# |-- [ versicolor ]
# |-- [ virginica ]
clf = tree.DecisionTreeClassifier()
clf.fit(X,y)
print 'scikit score:', np.count_nonzero(clf.predict(X) == y) / y.shape[0]
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=data.feature_names,
class_names=data.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
#scikit score: 1.0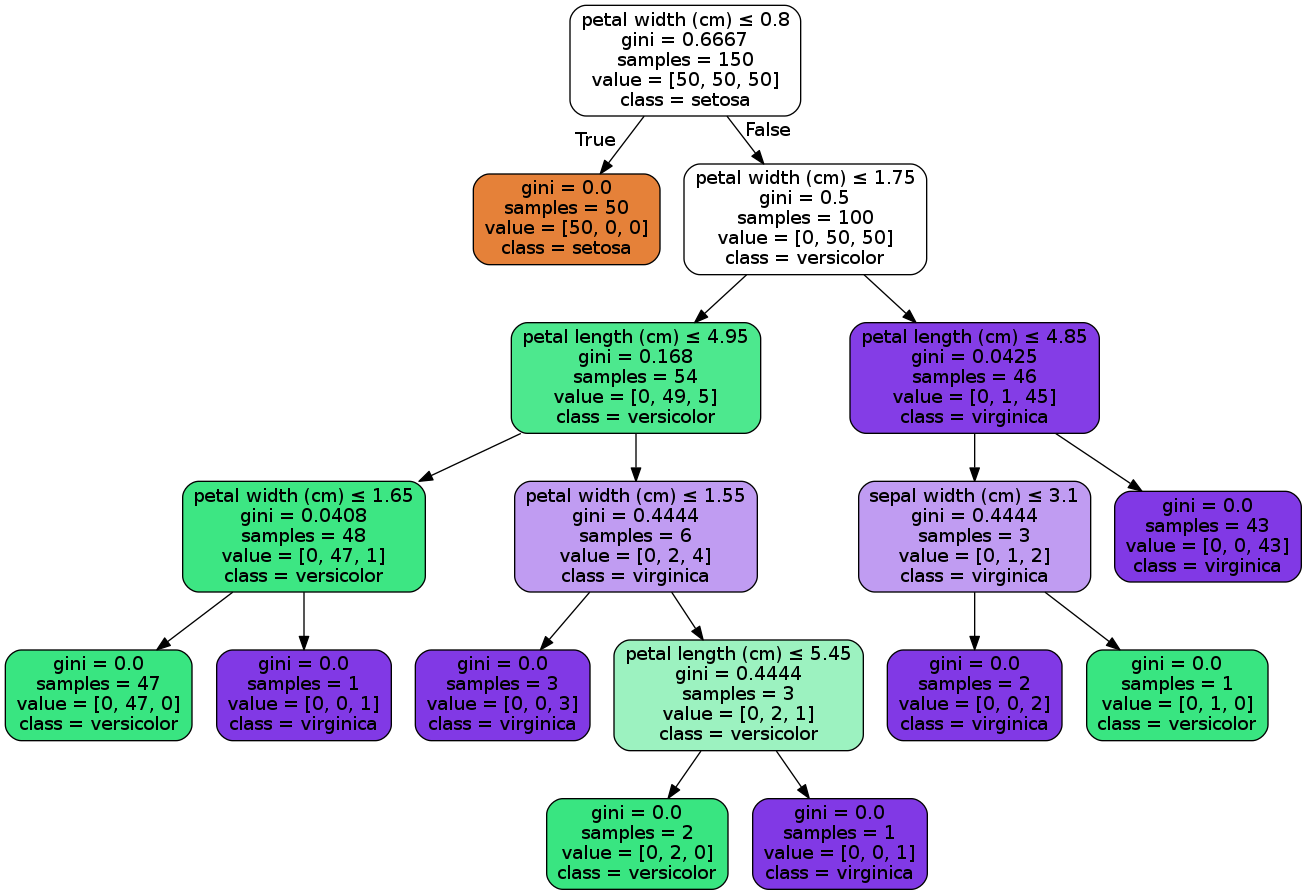















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









