







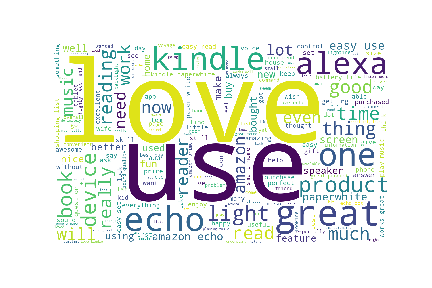
 本文通过Excel和Python分析亚马逊Kindle评论数据,探讨产品好评率、受欢迎点。发现Kindle评分普遍高,用户主要在1月、12月及8-9月购买,且喜爱其轻便、流畅、操作简单、人工智能功能。
本文通过Excel和Python分析亚马逊Kindle评论数据,探讨产品好评率、受欢迎点。发现Kindle评分普遍高,用户主要在1月、12月及8-9月购买,且喜爱其轻便、流畅、操作简单、人工智能功能。
在电子商务领域,用户除了关心产品的功能和价格外,最主要的就是产品口碑,很多人都在评论区查看产品的恰用户评价,因此,用户对产品的评价评论亦是产品的重要指标。
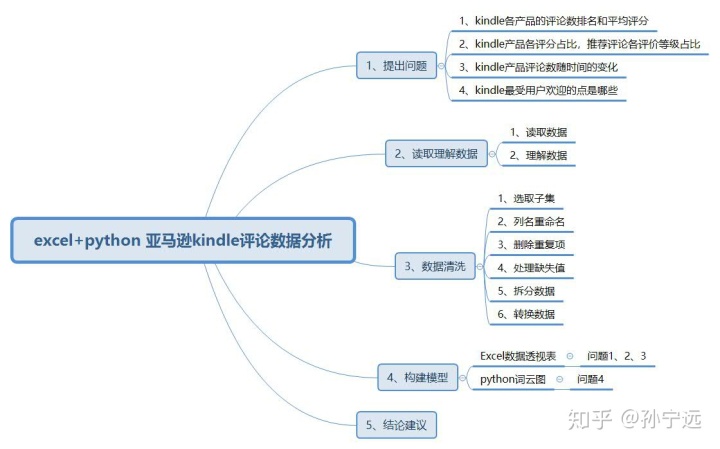
本文将通过excel和python两个工具,针对亚马逊平台上的kindle商品的评论数据进行分析,探索两个方面的问题:
- kindle产品的好评率如何?
- kindle最受用户欢迎的有点是哪些?
一、提出问题
- kindle各产品的评论数排名和平均评分。
- kindle各产品的好评率,推荐占比。
- kindle各产品评论数和评价随时间的变化。
- kindle最受用户欢迎的点是哪些。
二、读取、理解数据
数据来源:
https://www.kaggle.com/datafiniti/consumer-reviews-of-amazon-products/homewww.kaggle.com理解数据,数据字段含义如下:
- id:用户编号
- name:产品名称
- asin:产品编号
- brand:产品品牌
- categories:类别
- keys:类别关键词
- manufacturer:制造商
- reviews.date:评论时间
- reviews.dateAdded:追加评论时间
- reviews.dateSeen:评论可见时间
- reviews.didPurchase:评论已购买
- reviews.doRecommend:评论是否被推荐
- reviews.id:评论ID
- reviews.numHelpful:帮助性分子数
- reviews.rating:评分
- reviews.sourceURLs:评论链接
- reviews.text:评论内容
- reviews.title:评论标题
- reviews.userCity:用户所在城市
- reviews.userProvince:用户所在省
- reviews.username:用户名
三、数据清洗
1、选取子集
1.1 根据产品类别categary,筛选选择包含kindle的数据。

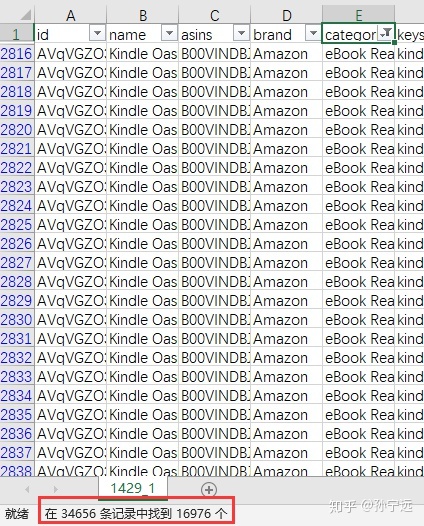
经过筛选,共筛选出16976条关于kindle的产品数据。
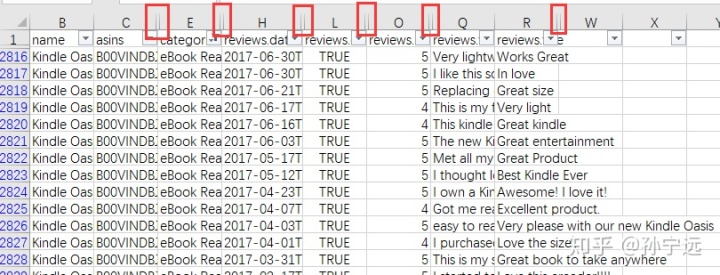
1.2 隐藏无关的字段
根据分析需要,我们只需保留以下字段:
- name:产品名称
- asin:产品编号
- categories:类别
- reviews.date:评论时间
- reviews.doRecommend:评论是否被推荐
- reviews.rating:评分
- reviews.text:评论内容
- reviews.title:评论标题
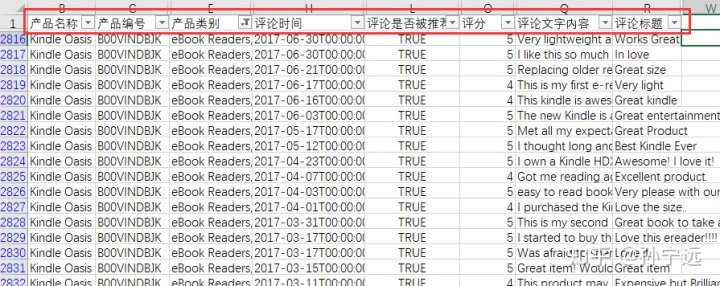
2、列名重命名
为便于分析,将列名命名为中文名。
3、删除重复项
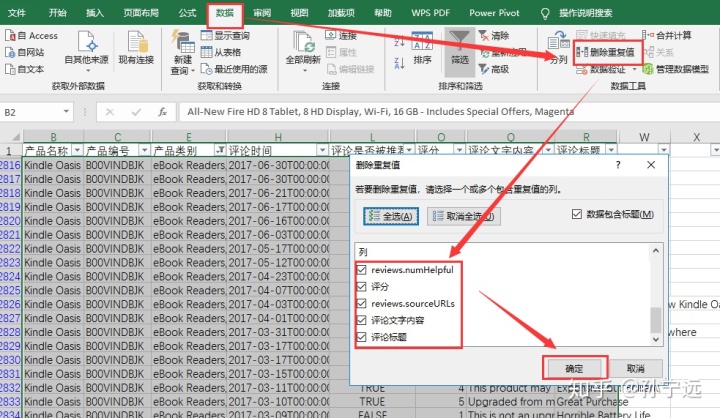
根据目标数据对数据进行去重,本次数据表中无重复值,因此去重结果如下:

4、处理缺失值
缺失值处理主要又四种方法:(1)对缺失内容进行手动补全;(2)删除缺失值;(3)用平均值代替;(4)用统计模型计算的值代替缺失值。
通过筛选条件,发现个字段均又重复值,对于缺失值,根据本次分析目的,对确实行进行如下两种处理方法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









