







前面我们已经将正文内容获取出来了,其实到这里已经可以完成这个实例的要求了,但是我在结果中发现一些乱入的字符
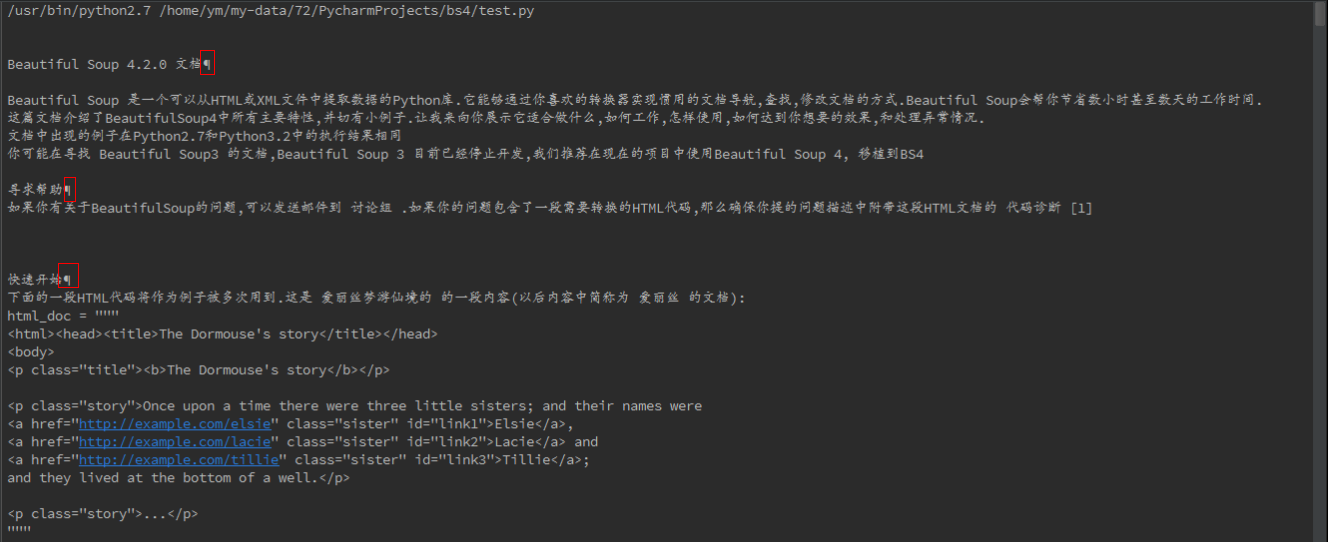
就是这些红色框框圈出来的符号,本来这是不影响使用的,但对于轻微强迫症的我来说,这实在是有点不爽,所以我要想办法将这些烦人的小符号去掉。
首先,通过对源码的分析,我发现这些符号代表的是一个链接
<h1>快速开始<a class="headerlink" href="#id4" title="永久链接至标题">¶</a></h1>
<h1>安装 Beautiful Soup<a class="headerlink" href="#id5" title="永久链接至标题">¶</a></h1>首先,这是一个<h1>标签,代表的是标题,我当然不能把这部分给删除了,<h1>标签里面包含<a>标签,而且它们的属性都是一样的,class="headerlink",所以我现在的做法应该是只删除<h1>标签里面带有 class="headerlink" 的<a>标签,BS4中有没有能实现这个功能的函数呢?
clear()
clear() 方法移除当前tag的内容:
extract()
extract() 方法将当前tag移除文档树,并作为方法结果返回:
decompose()
decompose() 方法将当前节点移除文档树并完全销毁:
这就是传说中BS4的删除三兄弟,理论上,这三个方法应该都是可以实现我们的功能的,既然要用到这几个功能,我们就来看看它们的用法和区别,为了方便统一说明,我这里直接在一段代码中实现使用和对比
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
__author__ = '217小月月坑'
'''
BS4删除三兄弟对比
'''
from bs4 import BeautifulSoup
# clear() 方法移除当前tag的内容:
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup)
a_clear = soup.a
i_clear = soup.i.clear()
# extract() 方法将当前tag移除文档树,并作为方法结果返回
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup)
a_extract = soup.a
i_extract = soup.i.extract()
# decompose() 方法将当前节点移除文档树并完全销毁
markup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup)
a_decompose = soup.a
i_decompose = soup.i.decompose()
# 输出
print a_clear # <a href="http://example.com/">I linked to <i></i></a>
print i_clear # None
print a_extract # <a href="http://example.com/">I linked to </a>
print i_extract # <i>example.com</i>
print a_decompose # <a href="http://example.com/">I linked to </a>
print i_decompose # None结果分析:
首先先说a_*,这个变量显示的是使用三种方法后原来的字符串变成什么样子,首先,clear 的结果中还保留有<i></i>,而它的函数功能的描述是移除tag的内容,结果也是和它的描述相符合的,只是移除了tag的内容,它的标签并没有被移除,而extract 和 decompose 方法是移除当前tag的文档树,所以它们两个的a_*输出中并没有<i></i>
i_* 是执行函数的返回值,也就是说,执行这些方法之后,会不会将删除的东西返回,更直白的理解是能不能看到删除了什么东西。其中只有extract方法的说明中提到有返回值,这里输出的结果中也可以体现
删除三兄弟的用法和区别就简单讲到这里,我们现在关注的主要问题应该是,怎么在我们抠出来的正文的代码块中将含有class="headerlink" 属性的标签删除
啊,这里真的是,接着讲的话又太长,转到下一小节的话又显得我有点短小,所以我决定在这里聊点别的
最近经同事介绍发现了一个很有价值的网站:stackoverflow ,中文名叫堆栈溢出,不过我更喜欢它的另一个名字,爆栈,这是国外的一个专门的程序员论坛,你可以到上面提问也可以回答问题,说实话,对于技术这方面的东西,我还是比较认可老外的,所以,经常去上面逛的话,应该会有很多的收获,但是有一些不好的方面就是这个网站加载得真的很慢,而且全部都是英文的,反正大不了也刚好练练自己的 poor english
好了,收拾收拾,准备进入下一小节去解决我们的问题















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









