






这里提出了多级Mask细化(MMR)模块,首先从CLIP的异常定位结果中提取多样化的点框提示,然后使用这些提示引导SAM生成精确的Mask。最后,作者将这些Mask与根据不同Mask置信度从CLIP获得的Mask结果进行融合。统一多尺度跨模态交互+多级Mask细化模块让语义分割性能达到最佳
最近,基础模型如CLIP和SAM在零样本异常分割(ZSAS)任务上表现出色。然而,基于CLIP或SAM的ZSAS方法仍存在一些不可忽视的缺陷:
- CLIP主要关注不同输入之间的全局特征对齐,导致对局部异常部分的分割不精确;
- SAM倾向于生成大量冗余Mask,而没有适当的提示约束,导致复杂的后处理要求。
在这项工作中,作者创新性地提出了一种CLIP和SAM协作框架ClipSAM,用于ZSAS。ClipSAM的洞察是利用CLIP的语义理解能力进行异常定位和粗略分割,这进一步用作SAM的提示约束以改进异常分割结果。具体而言,作者引入了一个关键的统一多尺度跨模态交互(UMCI)模块,用于在CLIP的多个尺度上与视觉特征交互推理异常位置。然后,作者设计了一个新的多级Mask细化(MMR)模块,它利用位置信息作为多级提示,用于获取层次化的Mask并合并它们。大量实验验证了ClipSAM的有效性,在MVTec-AD和VisA数据集上实现了最佳的分割性能。
代码:https://github.com/Lszcoding/ClipSAM
1 Introduction
零样本异常分割(ZSAS)是图像分析和工业质量检查等领域的关键任务。它的目标是准确地定位图像中的异常区域,而不依赖先前的特定类别训练样本。因此,工业产品的多样性以及异常类型的不确定性对ZSAS任务提出了显著的挑战。
请注意,此翻译保留了原始文本的格式和标题,并尽可能保留了原文的信息。然而,由于我是根据英文文本进行翻译的,某些词汇可能无法准确翻译,例如Transformer和CNN。在这种情况下,我保留了原文的英文缩写,并在可能的情况下给出了相关的解释。
随着基础模型如CLIP和SAM的出现,零样本异常分割(ZSAS)取得了显著的进展。如图1所示,基于CLIP的方法,如WinCLIP和APRIL-GAN,通过比较图像块 Token 和文本块 Token 之间的相似性来确定每个块的异常分类。虽然CLIP具有强大的语义理解能力,但这是通过将语言和视觉的局部特征对齐来实现的,因此对于细粒度分割任务来说,这种方法并不适用。
另一方面,研究行人已经探索了SAM基础方法以辅助ZSAS任务。SAM具有优越的分割能力,可以接受多种提示,包括点、框和文本提示,以指导分割过程。为此,SAA如图1所示,使用带有文本提示的SAM生成大量候选Mask,并进行后处理过滤。然而,简单的文本提示可能不足以准确描述异常区域,导致异常定位性能不佳和SAM能力利用率低下。同时,模糊的提示会导致生成冗余Mask,需要进一步选择正确的Mask。
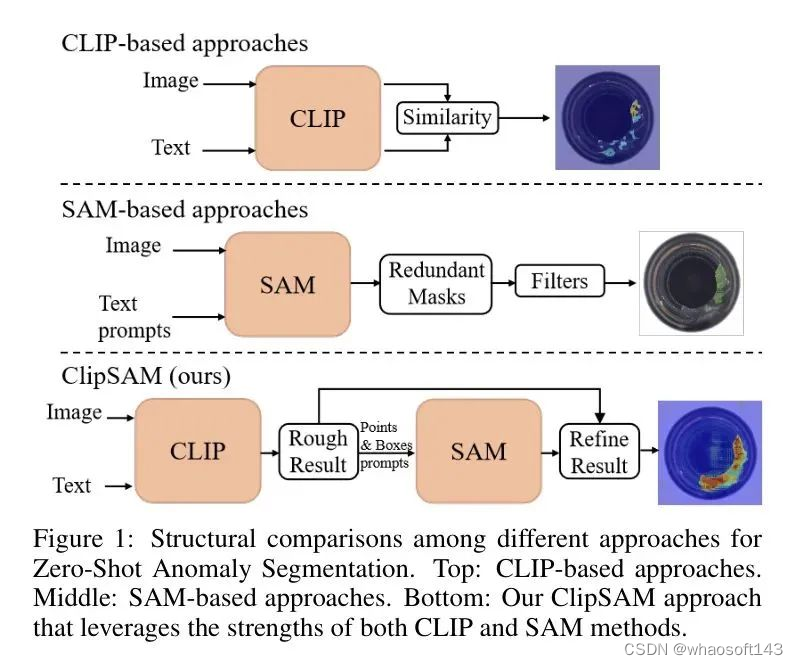
在这些观察的基础上,作者创新性地提出了一种CLIP和SAM协作框架,首先使用CLIP进行异常定位和粗略分割,然后利用SAM和定位信息来优化异常分割结果。对于CLIP阶段,将语言 Token 和图像块 Token 的融合以及模型依赖性的建模是非常关键的,因为跨模态交互和融合已被证明在许多研究中对定位和目标分割有益。
此外,许多显著的工作专注于通过关注行和列特征来增强模型的局部语义理解。受这些研究启发,作者开发了一种新颖的跨模态交互策略,它使文本和视觉特征在行-列和多尺度 Level 上进行交互,从而适当地增强CLIP对异常部分定位和分割的能力。
对于SAM阶段,为了充分利用其细粒度分割能力,作者利用CLIP的定位能力以点或边界框形式提供更明确的提示。这种方法极大地提高了SAM准确分割异常区域的能力。此外,作者注意到,当提供相同的提示时,SAM的分割结果通常显示不同粒度的Mask。为了避免进一步的Mask过滤导致的不必要的后处理,作者提出了一种更高效的Mask优化策略,将不同粒度的Mask无缝集成,从而提高异常分割结果。
作为结论,作者提出了一种新颖的两阶段框架,名为CLIP和SAM协作(ClipSAM),用于ZSAS。与先前的相关工作相比,结构比较如图1所示。在第一阶段,作者使用CLIP进行异常定位和粗略分割。为了实现不同 Level 多模态特征的融合,作者设计了一个统一多尺度跨模态交互(UMCI)模块。UMCI将来自水平和垂直方向的图像块 Token 聚合,并利用相应的行和列特征与语言特征进行交互,感知不同方向上的局部异常。UMCI还考虑了语言和多尺度视觉特征的交互。在第二阶段,作者利用CLIP的定位信息指导SAM进行分割优化。
具体而言,作者提出了多级Mask细化(MMR)模块,首先从CLIP的异常定位结果中提取多样化的点框提示,然后使用这些提示引导SAM生成精确的Mask。最后,作者将这些Mask与根据不同Mask置信度从CLIP获得的Mask结果进行融合。
作者的主要贡献可以总结如下:
- 提出了一种新颖的框架,名为CLIP和SAM协作(ClipSAM),用于充分利用不同大型模型在ZSAS任务上的特性。具体而言,作者首先使用CLIP定位和粗略分割异常物体,然后使用SAM和定位信息来优化分割结果。
- 为了更好地协助CLIP实现预期的定位和粗略分割,作者提出了一种统一多尺度跨模态交互(UMCI)模块,该模块通过在行-列和多尺度 Level 上与语言特征交互视觉特征来学习异常部分的局部和全局语义。
- 为了适当地优化SAM的分割结果,作者设计了一种多级Mask细化(MMR)模块。该模块从CLIP的定位信息中提取点框提示,以引导SAM生成精确的Mask,并将这些Mask与CLIP的结果进行融合,以实现细粒度的分割。
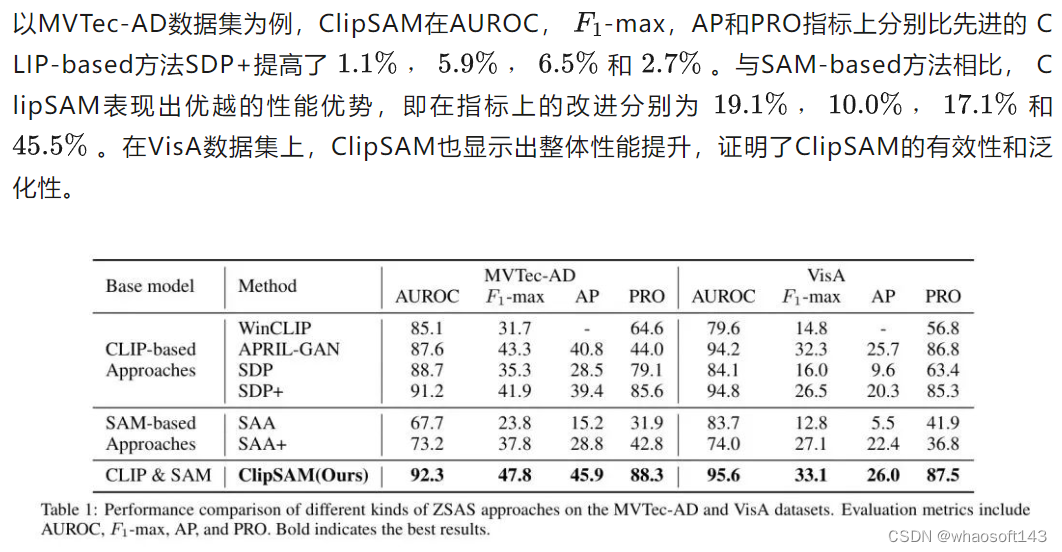
- 在多个数据集上的广泛实验证实了ClipSAM可以实现最先进的零样本异常分割结果。尤其是在MVTec-AD数据集上,ClipSAM在像素 Level 的AUROC方面比基于SAM的方法提高了+19.1,在F1最大值方面提高了+10.0,在Pro指标方面提高了+45.5。
2 Methodology
CLIP and SAM Collaboration
CLIP具有对不同模态的强大语义理解能力,而SAM可以轻松检测细粒度物体的边缘,这两者对于异常分割都是重要的。在这篇论文中,作者提出了一种新颖的CLIP和SAM协作框架,名为ClipSAM,旨在提高零样本异常分割的性能。概述的体系结构如图2所示。
具体而言,作者利用CLIP进行初始的粗糙分割,并将其作为约束用于优化SAM的分割结果。在CLIP阶段引入了统一多尺度跨模态交互(UMCI)模块,以实现准确的粗糙分割和异常定位。在3.3节中设计了一种多级Mask细化(MMR)模块,它将CLIP的指导纳入SAM,以帮助其生成更精确的Mask以实现细粒度分割。此外,讨论了整个框架的优化函数。
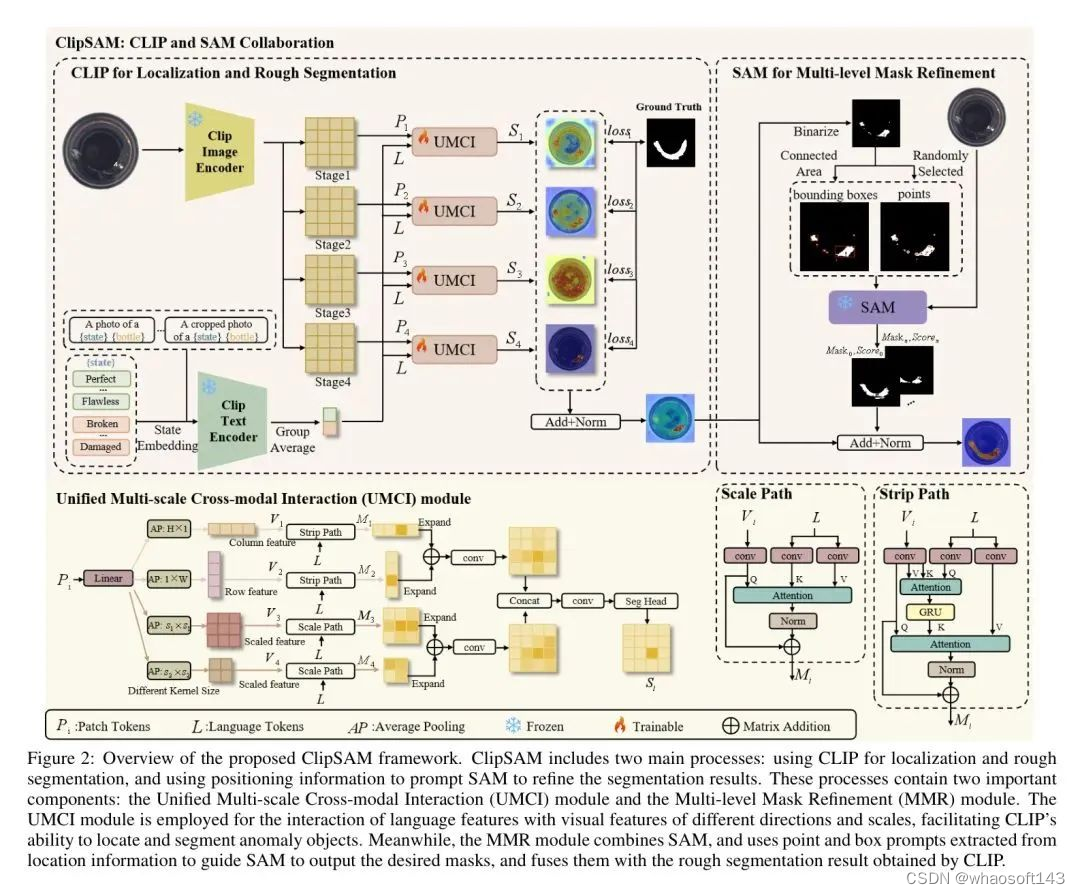
Unified Multi-scale Cross-modal Interaction

具体而言,UMCI模型包含两个并行路径:Strip Path和Scale Path。Strip Path捕获块 Token 的行和列 Level 特征,以精确地确定位置。Scale Path专注于捕捉图像的各种尺度下的全局特征,从而全面理解异常。以下将详细描述。
(1)Strip Path 。

(2) Scale Path

(3) Dual - path Fusion

Multi-level Mask Refinement
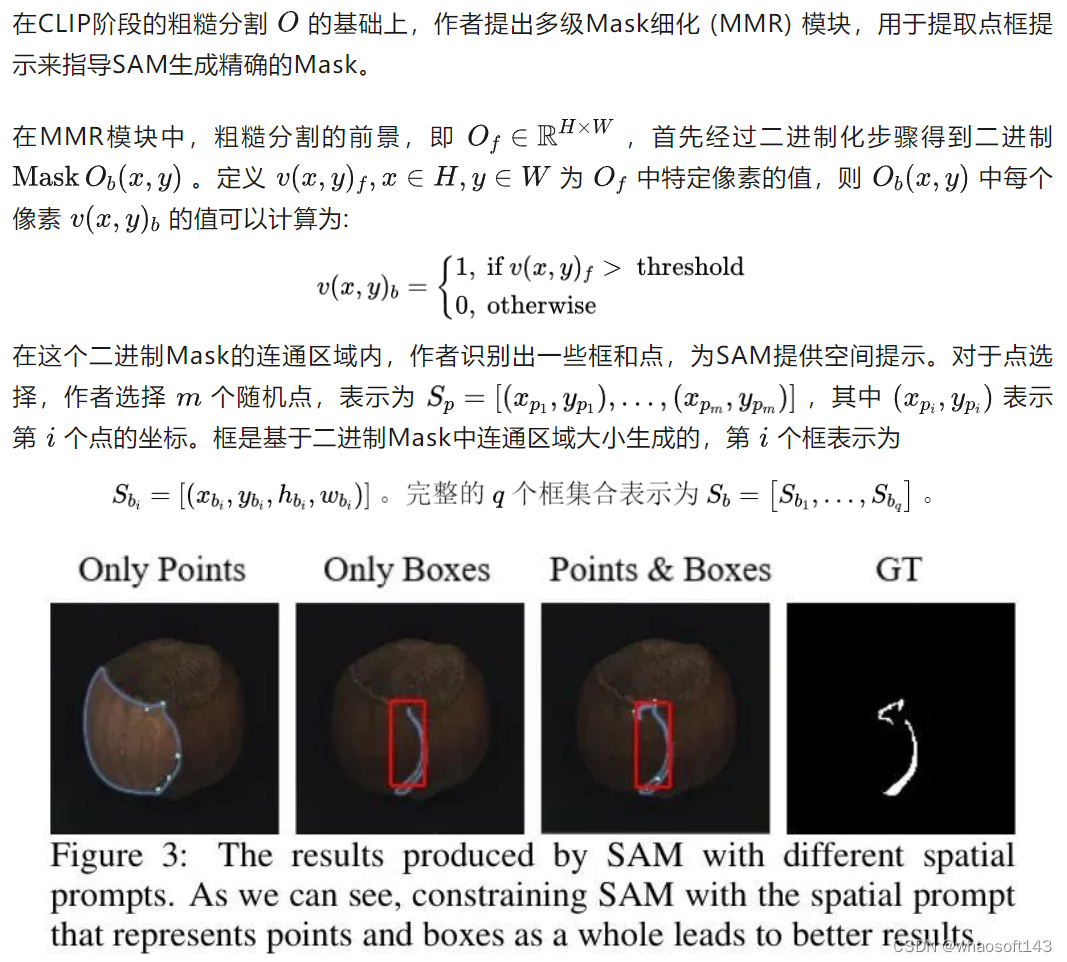

Objective Function
在ClipSAM框架中,只有UMCI模块需要训练。为了有效地优化这个模块,作者采用了Focal Loss和Dice Loss,它们都适合分割任务。
Focal Loss。Focal Loss主要应用于解决类别不平衡问题,这是分割任务中常见的一个挑战。由于异常通常只占据整个物体的很小一部分,因此它在异常分割中是合适的。
Focal Loss的表达式如下:

4 Experiments
Experimental Setup
数据集。在本研究中,作者在两个常用的工业异常检测数据集上进行实验,分别是VisA和 MVTec-AD,这些数据集涵盖了正常或异常的工业物体。作者遵循现有零样本异常分割研究的训练设置来评估ClipSAM性能。
具体来说,模型首先在MVTec-AD数据集上进行训练,然后在VisA数据集上进行测试,反之亦然。其他数据集上的附加实验结果请参阅附录C 。

Experiments on MVTec-AD and VisA
与最先进方法的比较。 在本节中,作者在MVTec-AD和VisA数据集上评估作者提出的ClipSAM框架在ZSAS方面的有效性。表1显示了作者的提出的ClipSAM与现有最先进的ZSAS方法在不同的数据集和各种指标上的全面比较。可以得出结论,ClipSAM在四个指标上都优于现有的最先进方法。
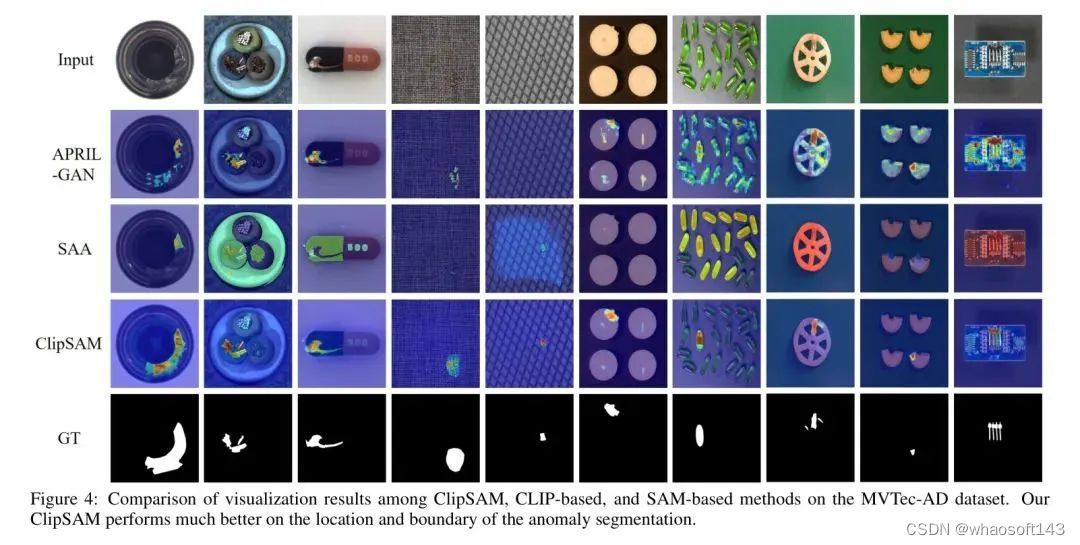
定性比较。作者提供一些ZSAS结果的视觉化示例,以进一步证明作者提出的方法的有效性。为了进行比较,作者还展示了APRIL-GAN(基于CLIP的方法)和SAA(基于SAM的方法)的分割可视化。可以观察到,APRIL-GAN可以大致定位异常,但无法提供出色的分割结果。
相比之下,SAA可以执行良好的分割,但无法准确覆盖异常区域。与这些方法相比,作者提出的ClipSAM既提供准确的定位,又提供良好的分割结果。更多的可视化结果请参阅附录D。为了更好地理解ClipSAM框架中每个模块的作用,作者还展示了CLIP阶段的粗糙分割结果和输入到SAM阶段的处理提示的视觉化示例。它表明CLIP对异常部分的粗糙分割并生成相应的提示,以完成SAM的进一步优化。请参阅附录E以获取更多信息。
Ablation Studies
在这个部分,作者在MVTec-AD数据集上进行几个消融研究,以进一步探索不同组件和实验设置对所提出的ClipSAM框架中结果的影响。
组件的影响。表2显示了ClipSAM中不同组件的影响。具体而言,作者首先探讨在UMCI模块中仅保留一条路径的影响,然后测试从框架中移除UMCI或MMR模块的影响。
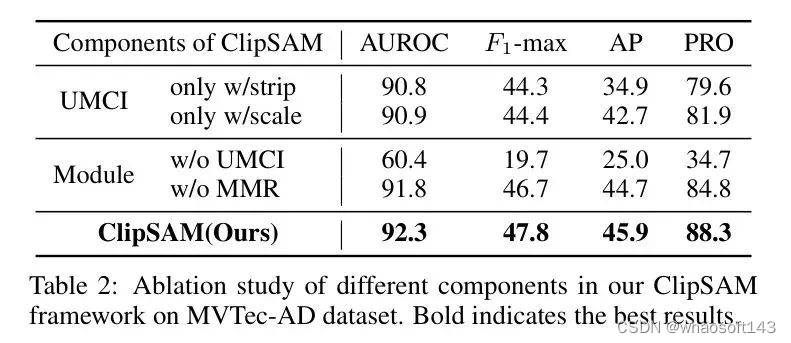
可以发现,从UMCI模块中移除一条路径会导致性能下降,而移除尺度路径的影响更大,反映出将两个路径结合在UMCI模块中的必要性。在模块 Level ,移除MMR模块将稍微降低性能。与SDP+进行比较,作者惊讶地发现CLIP阶段生成的粗糙分割结果的性能甚至优于CLIP基础方法。
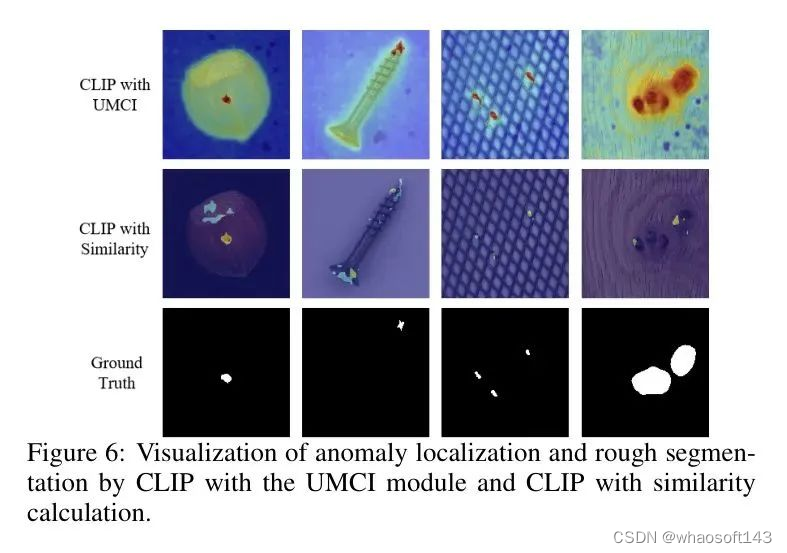
图6展示了粗糙分割和APRIL-GAN(由于SDP不是开源的)之间的可视化比较。图6的第一两列表明UMCI可以更准确地定位异常,最后两列显示UMCI提供了更好的分割。与MMR模块相比,移除UMCI模块意味着将相似性分割视为粗糙分割结果。然而,如图4所示,相似性分割无法为后续MMR模块提供文本对齐的块 Token 和准确的局部空间提示,这导致了性能崩溃,这表明在ClipSAM框架中,UMCI模块起着重要作用。
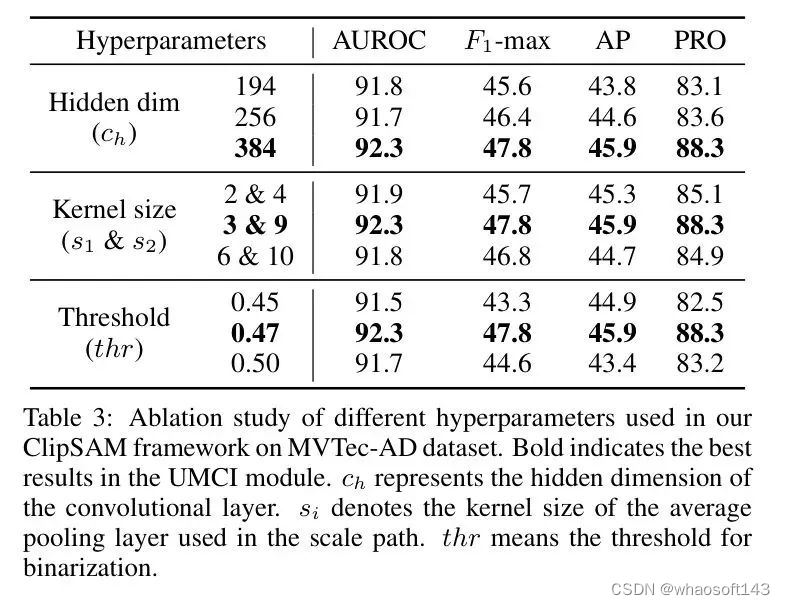
超参数的影响。作者探索了各种超参数对ClipSAM框架的影响,并记录了结果在表3中。根据结果,作者提供了每个超参数在ClipSAM框架中的作用分析。隐层维度()决定了卷积层的输出特征维度。较大的值有助于模型有效解释视觉特征。核大小()影响多尺度视觉特征的大小,它应该适中,以提供易于理解的视觉上下文。阈值值()主要影响SAM阶段初始二进制分割。的设置也应该适中:较小的值可能会导致非异常区域被错误分类,从而无法为SAM生成准确的Mask;较大的值可能会忽略一些异常,无法检测到。
5 Conclusion
作者首次提出CLIP和SAM协作(ClipSAM)框架来解决零样本异常分割问题。为了有效地级联这两个基础模型,作者引入了两个模块。一个是UMCI模块,它明确推理异常位置并实现粗糙分割。另一个是MMR模块,它通过使用具有精确空间提示的SAM来优化粗糙分割结果。
实验结果表明,ClipSAM通过利用不同基础模型的特性,为改进零样本异常分割提供了一个新的方向。在未来的工作中,作者将进一步研究如何将不同模型的知识整合起来,以增强零样本异常分割的性能。















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









