






这是关于模型验证环节AP值以及小目标检测中的召回率偏低的踩坑详解。
年初yolov8的更新上线让大家再次感受到"白嫖"的喜悦,项目上用了许久的模型终于可以更新换代。作为"白嫖党"的一员,我目前项目中使用的一直是自己优化的nanodet,所以也希望能借助yolov8实现"无痛涨点"。
但是在模型实际训练过程中,我发现了两个问题:
1、在yolov8模型的验证环节,采用自带验证代码计算得到AP值会与通过COCO数据集官方接口pycocotools计算得到的AP存在几个百分点的差距。
2、在yolov8模型相比nanodet模型相比召回率偏低,尤其对于小目标(320*192输入尺寸10*10左右)。
接下来,针对这两个问题会进行分析及实验。
1. 通过对yolov8和pycocotools关于AP计算的方式进行对比,发现两者的差异在于获取PR曲线采样点时是否采用线性插值的方式。
yolov8采用线性插值:

pycocotools采用临近真值:
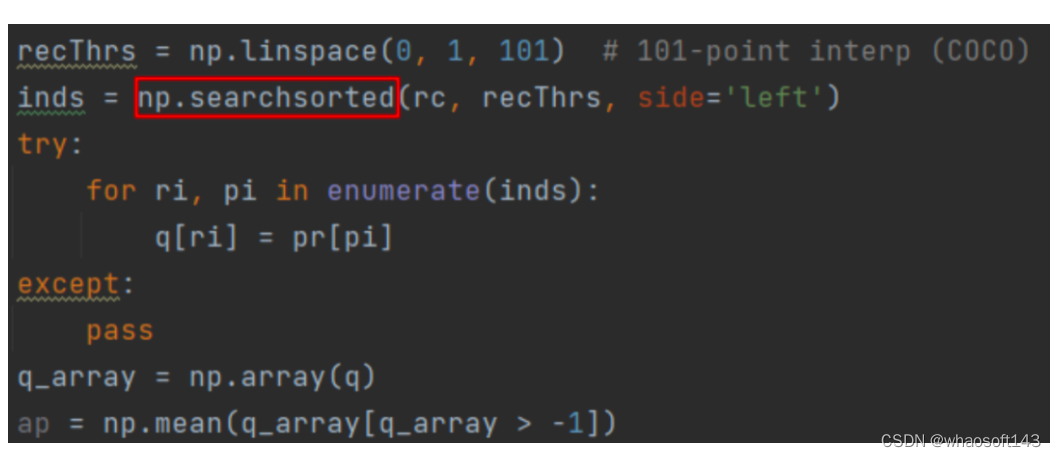
两者为什么会有这种差异?AP的计算需要采样点绘制出PR曲线,其中R∈[0:.01:1],共需采样101点。因为PR的原始真值点并不是按照R均匀分布,数量也不固定,所以需要在原始真值点的基础上采样出101个点用于计算AP。
在R依次从0均匀采样到1的过程中,遇到没有对应P真值的情况时,yolov8采用的线性插值方式会寻找左右临近两个真值点通过线性插值计算得到采样点对应P值,而pycocotools采用的临近真值方式则是寻找最接近采样点的真值点的P值作为采样点P值。最后对101个采样得到的P值取均值得到AP。
这样就明显发现两者AP计算存在的差异,尤其在PR曲线波动比较大的类别,两者的结果会差距更大。
个人觉得,pycocotools采用的临近真值方式会更加合理,因为参与计算的P值全部是真值,而yolov8采用的线性插值方式会存在估值误差。另外,pycocotools作为COCO官方接口使用也更广泛。
针对yolov8的AP计算代码做以下修改即可达到和pycocotools相同的结果:
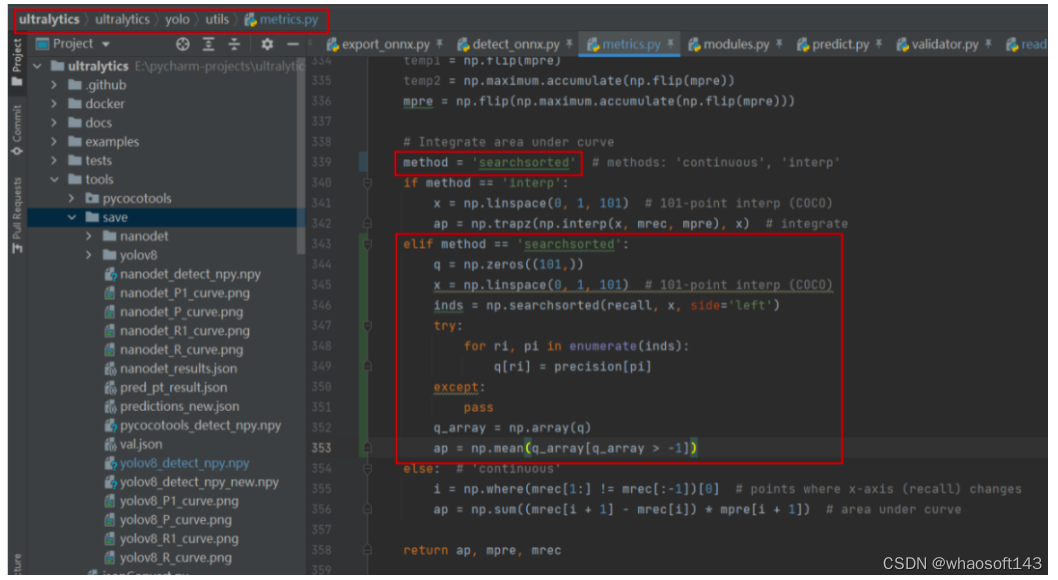
具体代码:
2、针对小目标召回率低的问题,首先采用和现有优化版nanodet相同策略------增大输出特征图尺寸,使用yolov8n-p2训练。
通过下图明显发现,增大输出特征图尺寸后,yolov8准确率依然占优,整体召回率有明显提升,只有香烟类别召回率依然较nanodet低。
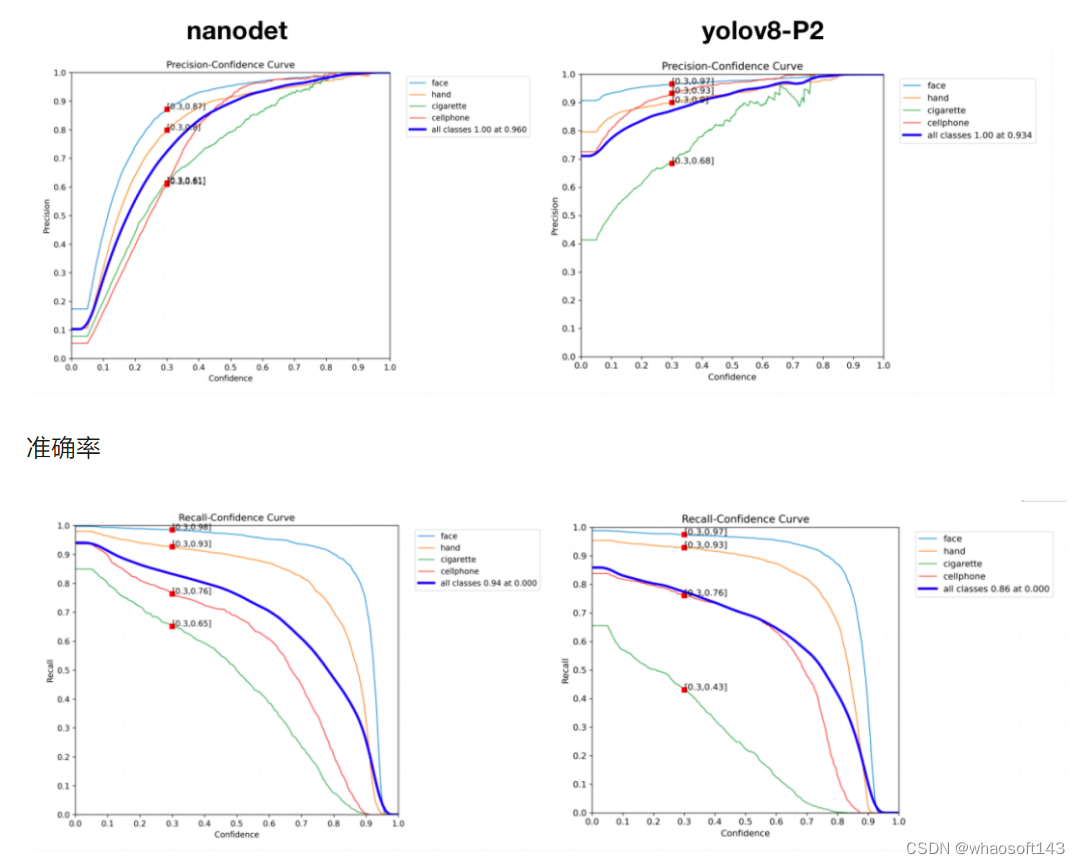
召回率
接下来,详细对比了nanodet与yolov8的模型结构,最终怀疑是标签分配策略导致。
将yolov8中标签分配方法TAL更换为ATSS后,香烟召回率和手机AP均有明显提升。虽然相同阈值下,除香烟外其他三类准确率略有下降,但是实际效果影响不大。
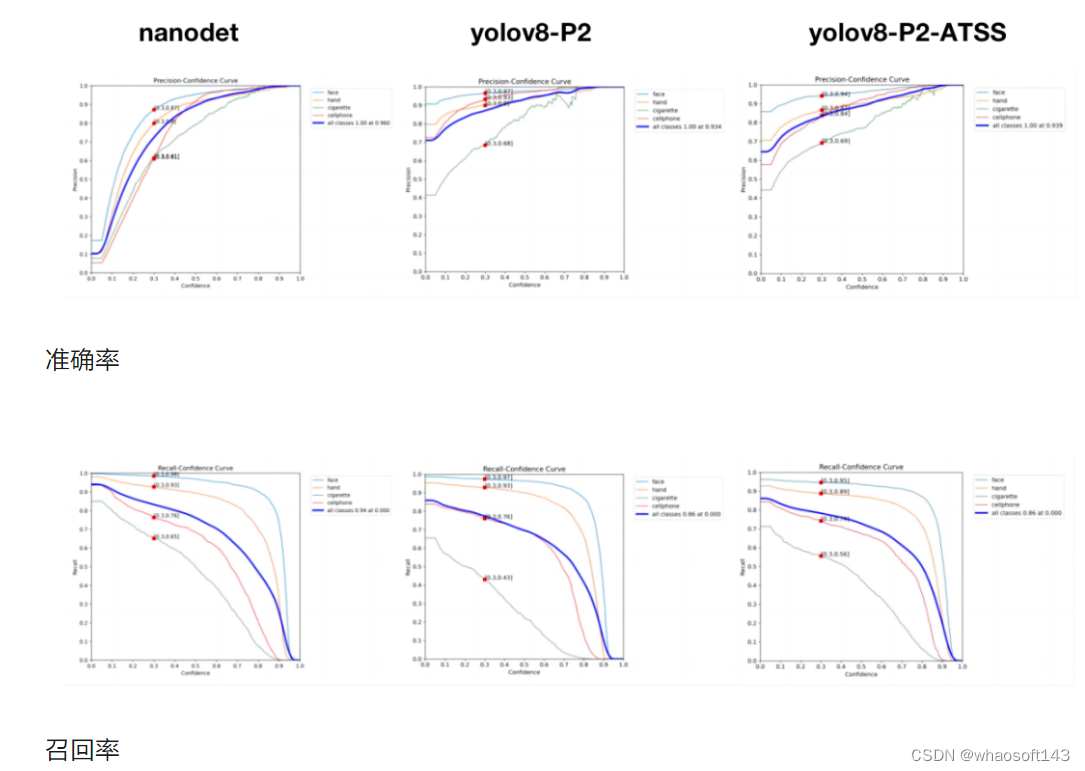
如果大家需要自己绘制上面这些P/R图,我已经集成到pycocotools官方工具中,开源地址:https://github.com/CPFelix/pycocotools。
总结:
在对比不同模型的指标时,最好使用同一统计工具。关于AP的计算,还需强调一点的是在横向对比其他模型时,一定要保证模型输出的置信度阈值和NMS阈值保持一致。
关于yolov8对于小目标的优化,目前行之有效的策略有两种:增大输出特征图和标签分配采用ATSS。
增大输出特征图很好理解,更大的特征图带来更加精细的底层特征,也意味着更多的候选正样本(落入GT框内),召回率自然会拉升。
而标签分配也是影响最终正样本的重要因素,为什么yolov8使用的TAL会损害小目标的召回呢?
个人看法,欢迎指正:TAL使用模型预测输出的分数和IOU作为度量分数区分正负样本,会存在两个问题:1、冷启动;2、小目标IOU波动大。冷启动的问题在基于模型预测输出区分正负样本的标签分配策略都存在,就是在模型刚开始训练时模型输出是混乱的,正负样本的分配效果也会很差,进而可能导致收敛效果不好。相比中大目标,小目标对于IOU会更加敏感,两个框很小的偏移就会带来IOU很大的差值。两方面因素叠加就会导致最终分配到小目标的正样本偏少,召回率偏低。
另外,在使用ATSS时还可以将锚点框的默认尺寸由5改为3,这样最终生成的默认锚点框会更小,也更适配小目标,会产生更多正样本。
参考文献:















 2208
2208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









