







Abstract
CLIP 和 Segment Anything Model(SAM)是卓越的视觉基础模型(VFMs)。SAM 在各种领域的分割任务中表现出色,而 CLIP 以其零样本识别能力而闻名。本文深入探讨了将这两种模型整合到一个统一框架中的方法。具体而言,我们引入了开放词汇表 SAM(Open-Vocabulary SAM),一种受 SAM 启发的模型,旨在同时进行交互式分割和识别,并利用两个独特的知识转移模块:SAM2CLIP 和 CLIP2SAM。前者通过蒸馏和可学习的变压器适配器将 SAM 的知识适配到 CLIP 中,而后者则将 CLIP 的知识转移到 SAM 中,增强其识别能力。在各种数据集和检测器上的广泛实验表明,开放词汇表 SAM 在分割和识别任务中都表现出色,显著优于简单组合 SAM 和 CLIP 的天真基线。此外,在图像分类数据训练的帮助下,我们的方法可以分割和识别大约22,000个类别。
代码地址:
https://github.com/HarborYuan/ovsam
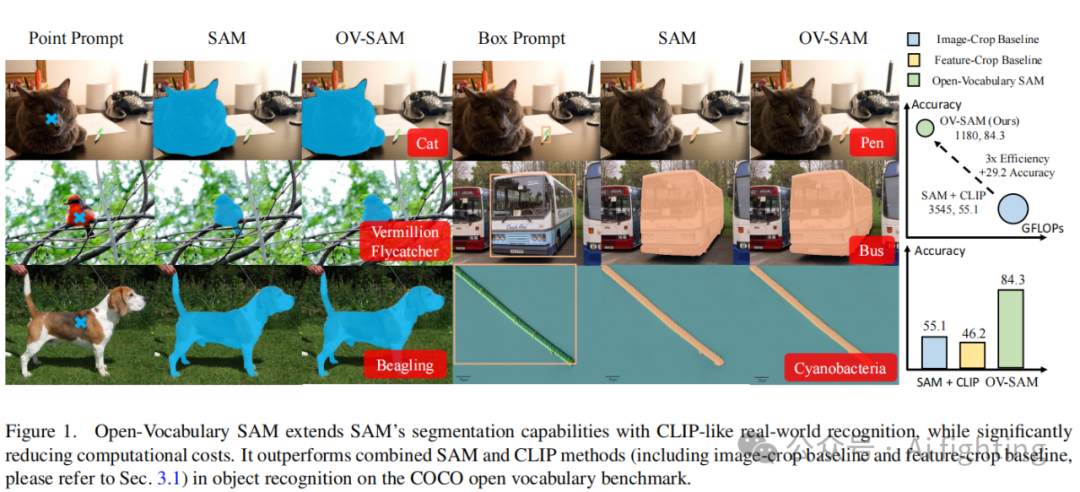
Introduction
Segment Anything Model(SAM)和 CLIP在各种视觉任务中取得了显著进展,分别在分割和识别方面展示了卓越的泛化能力。特别是 SAM,通过大量的掩码标签数据进行训练,使其通过交互式提示能够高度适应各种下游任务。而 CLIP 通过训练数十亿对文本-图像对,拥有了前所未有的零样本视觉识别能力。这引发了许多研究,探索将 CLIP 扩展到开放词汇任务中,如检测和分割。
尽管 SAM 和 CLIP 提供了显著的优势,但它们在原始设计中也存在固有的局限性。例如,SAM 缺乏识别其识别出的分割部分的能力。为了解决这一问题,一些研究通过整合分类头进行尝试,但这些解决方案仅限于特定数据集或封闭集环境。另一方面,CLIP 由于使用图像级对比损失进行训练,在适应密集预测任务时面临挑战。为了解决这一问题,一些研究探讨了对齐 CLIP 表示以进行密集预测的方法。然而,这些方法往往是数据集特定的,并不具有普遍适用性。例如,一些研究专注于在 ADE-20k数据集上的开放词汇分割,并使用 COCO数据集进行预训练。将 SAM 和 CLIP 以天真方式合并,如图 2 (a) 和 (b) 所示,被证明效率低下。这种方法不仅会产生大量计算开销,还会导致次优结果,包括小规模对象的识别,如我们的实验结果所示。
在这项研究中,我们通过统一的编码器-解码器框架解决了这些挑战,该框架集成了 CLIP 编码器和 SAM 解码器,如图 2 © 所示。为了有效地桥接这两个不同的组件,我们引入了两个新模块,SAM2CLIP 和 CLIP2SAM,促进双重知识转移。首先,我们通过 SAM2CLIP 从 SAM 编码器向 CLIP 编码器蒸馏知识。这一蒸馏过程不是直接在 CLIP 编码器上执行&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









