






摘要:讲师通过介绍MongoDB的日志审计和慢查询、解析即将商业化的MongoDB索引推荐功能,利用MapReduce&Flink做审计日志分析、以及通过创建索引的最佳实践的例子让大家了解阿里云是如何利用大数据对MongoDB里面的数据和信息做分析的。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要分为以下四个部分:
一、MongoDB日志审计和慢查询介绍
二、MongoDB索引推荐解析
三、利用mapreduce&flink做sql分析
四、创建索引的最佳实践
MongoDB的特性
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。MongoDb具有如下主要特性:
1. 支持单文档事务;
2. 灵活的json格式存储,最接近真实对象模型;
3. 高可用,运维简单,故障自动切换(自带读写功能,和指读功能);
4. 可扩展分片集群海量数据存储;
5. 支持多种引擎wiretiger rocksdb;
6. 适用场景:游戏,物流,电商,社交等。
MongoDB的日志审计和慢查询介绍
在使用MongoDB的使用过程当中,经常会遇到如下问题:
1. 查询超时报错;
2. 数据库响应慢;
3. CPU达到100%;
以上是用户经常反馈的性能问题,出现问题的原因一般是因为用户的某一个查询进行全表扫描导致性能差,或者使用的索引不够好。
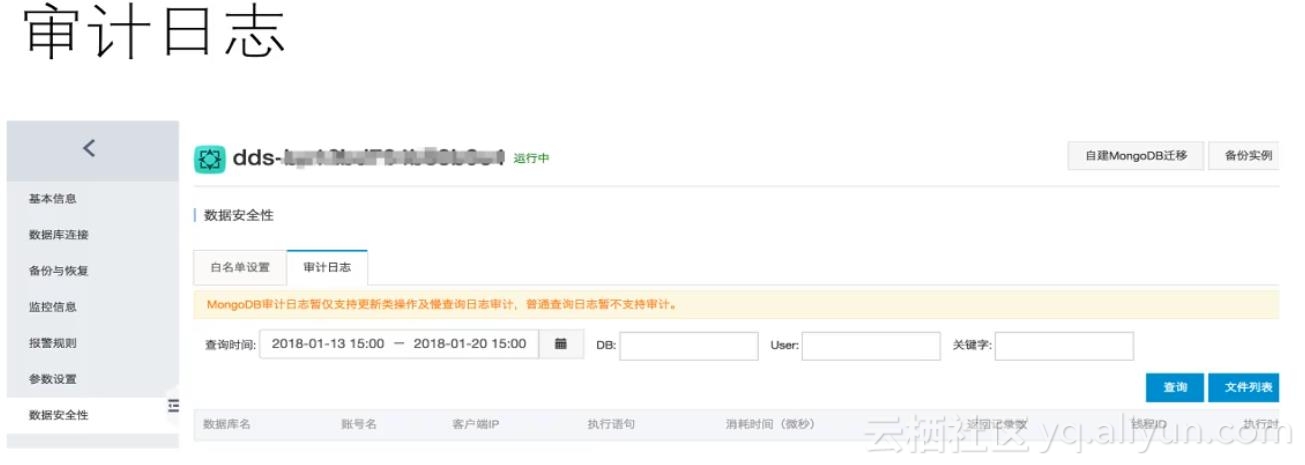
用户如何知道哪些SQL导致进行全表扫描?这些都可以在审计日志中查看。当选择MongoDB服务时,在数据安全性中,审计日志的标签下就可看到某一个时间段内这个数据库所有的更新,删除包括慢查询的SQL。用户可通过更新和删除操作来判断数据库有没有恶意操作以及非预期操作。审计日志图如下所示:
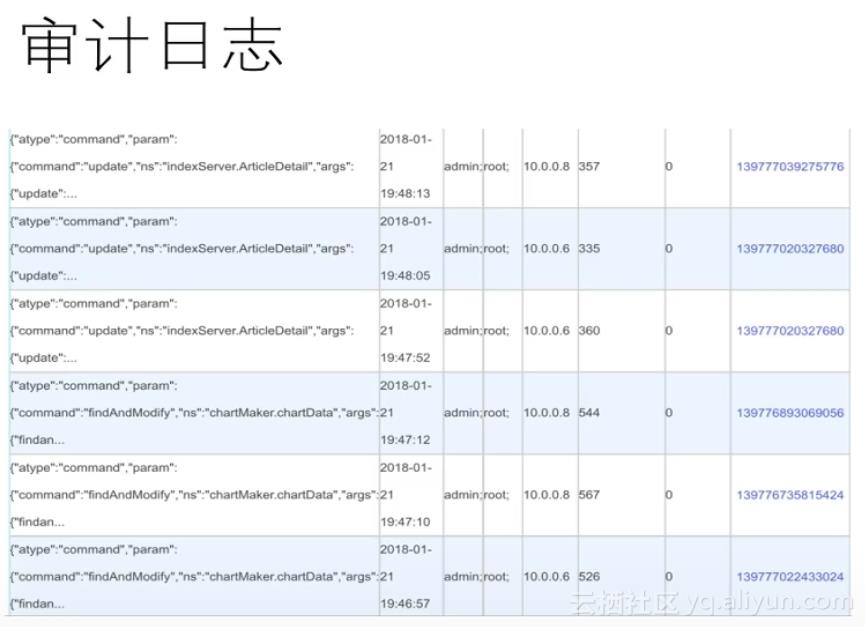
在审计日志中,有多种更新的方式(例如update、find and modify),第二列是操作的执行时间,第三列是访问的DB以及使用的账号,从这用户即可通过审计日志发现数据库内容的变更情况,并且对这些更新操作来做一个审计,来发现是否有误操作和非预期操作。
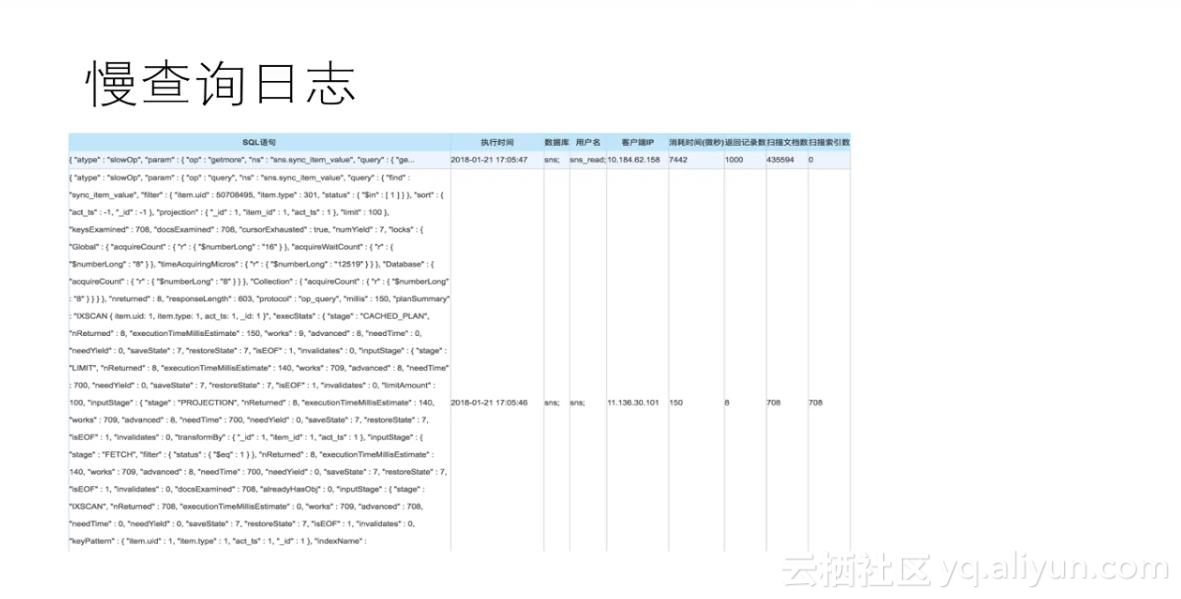
atype等于slowOp的一些查询日志就是慢查询,一般超过100毫秒的SQL会被记为慢查询并出现在审计日志里,用户再通过slowOp这个关键字去查找就能找出所有的慢查询。这个效果和用户通过直连数据库的查询效果是一样的。并且通过审计日志查询,对用户数据库的使用没有任何性能影响。
MongoDB索引推荐解析
当发现MongoDB存在慢查询的时候,传统优化慢查询的方法一般是人工优化慢查询、创建复合索引等方法。然而使用直连数据库去查的话,会对用户的数据库产生性能开销,并且复合索引列的顺序不同,产生的优化效果差异也大。除此之外,传统优化还有以下不足:
1. MongoDB的DBA极少;
2. 慢查询缺少统计;
3. 成本高。
正因如此,阿里云推出了MongoDB索引推荐服务:
1. 对慢查询进行统计和索引推荐;
2. 对不支持索引推荐的命令进行改写或者提示;
3. 对索引推荐的效果进行定量分析;
4. 索引推荐服务在四月份左右商业化。
索引推荐服务经历了两代架构的调整:
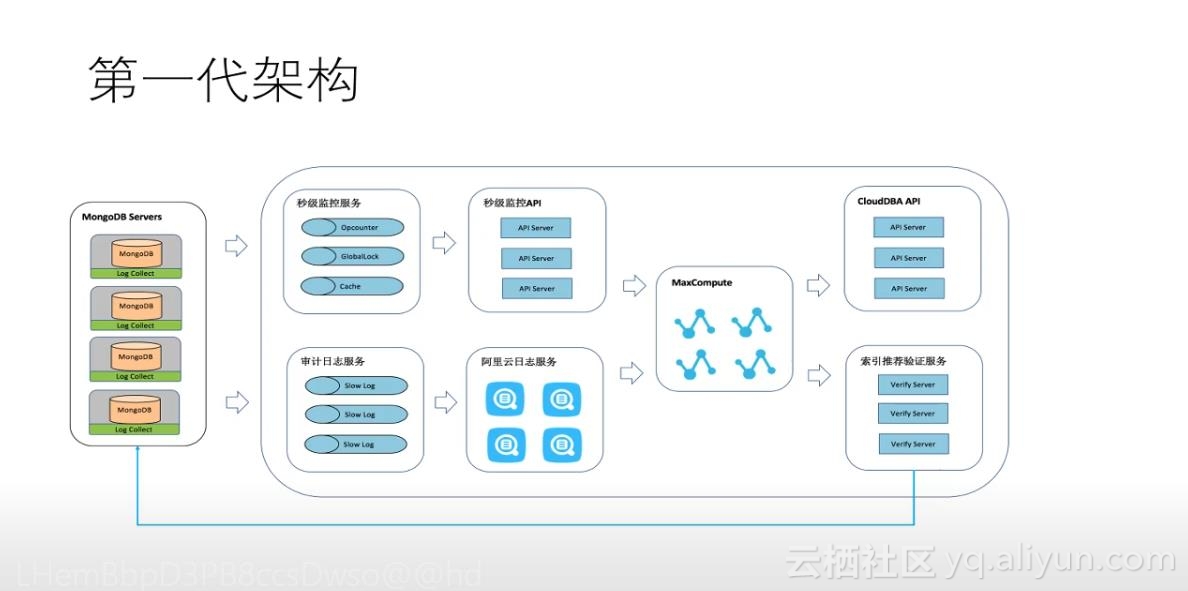
第一代架构调整是基于批量的计算引擎来得到的一些计算结果,架构图如上所示。
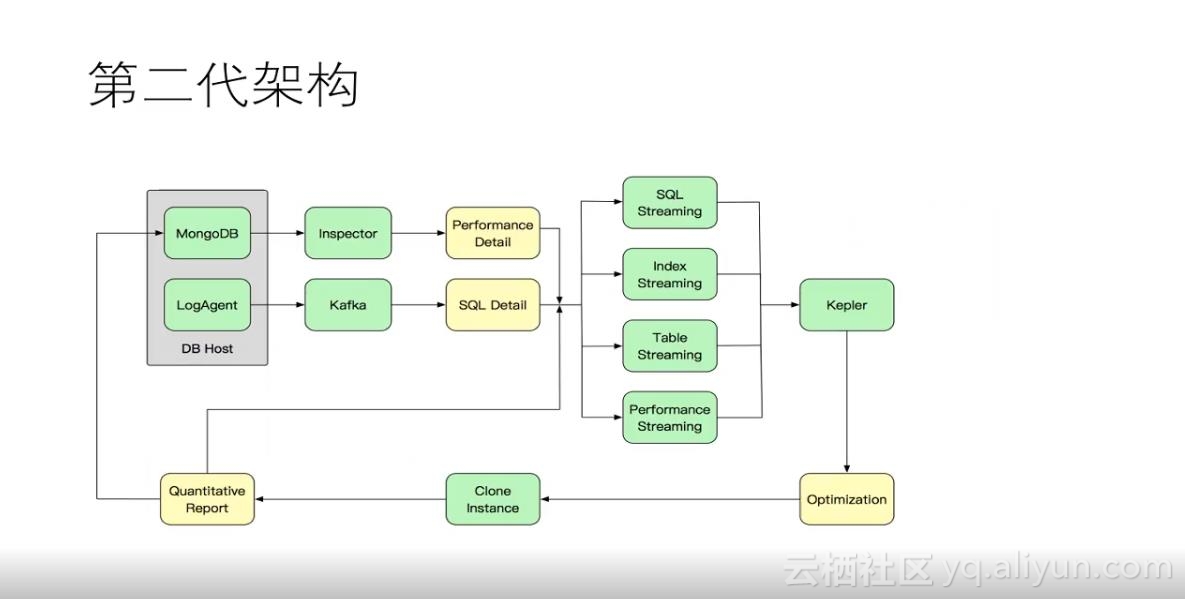
之所以要有第二代架构是因为第一代架构只支持批量的运算,运行的时间也较长,比较适用于每天做一次的离线分析,并且用户对实施性的要求变高了。第二代是基于流式的引擎,主要是利用flink做的索引推荐的分析服务,它同样是在MongoDB上面做一些采集。
利用MapReduce&Flink做审计日志分析
MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
Flink流式引擎的核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能,Flink流式引擎的主要特点如下:
1、连续流操作符——在数据到达时进行处理,没有任何数据收集或处理延迟;
2、支持SQL;
3、提供恰好一次的保证,及每条记录都仅处理一次;
4、提供一个非常高的吞吐量;
5、容错和开销都非常低;
索引推荐服务会从中分类出如下四种模型:
1、CURD模型;
2、索引模型;
3、表模型;
4、数据模型。
这些模型期望达到的监控用户有没有做一些非预期的更新和删除操作、根据提供的索引或者是删除一些冷索引达到提升性能的目标、通过对冷表更高效的压缩来达到减少空间的目标。
索引推荐的实现主要是通过每天离线推荐服务,具体的实现包括以下四个部分:
1、获取审计日志;
2、对审计日志进行查询模板化的处理;
3、选出核心慢查询(基于统计分析选出最值得优化的慢查询);
4、推荐索引和查询的改写。
创建索引的最佳实践
接下来通过一个实例来实践操作:
例如查询样例如下:
db.staff.find(
{
“birth_city:{
“$in”:[“beijing”,”shenzhen”]
},
”work_city”:”hangzhou”,
”age”:{
“$gte”:20
}
}).sort({“birthday”:1})
通过模板化,去掉业务数据:
集合名:staff
操作符:query
查询命令:
{“birth_city”:{“$in”,”<val>”},”work_city”:<val>,”age”:{“$gte”:”<val>”}}
排序命令:{“birthday”:1}
通过这样的方法,用户类似的查询都会统一为这样的模版,通过这些模版,对于执行时间超过100ms的模板化的查询,统计以下数据:
1、平均执行时长;
2、平均文档扫描次数;
3、平均索引扫描次数;
4、平均返回行数;
5、是否使用内存排序;
6、最后执行时间;
7、执行计划。
得到这些统计的数据以后,选择最值得优化的慢查询,这里有个最简单的规则:等号操作的列要放在in操作列的前面,in操作列要放在sort操作列的前面,sort操作列又要放在范围操作列的前面,当用户创建索引的时候,希望遵循这个规则去创建。例如如上所说的例子:
查询命令:
{“birth_city”:{“$in”,”<val>”},”work_city”:<val>,”age”:{“$gte”:”<val>”}}
排序命令:{“birthday”:1}
最终创建索引:{“work_city”:1,”birth_city”:1,”birthday”:1,”age”:1}
因为work_city列是等号操作,所以放在第一个位置,根据规则,以此类推birth_city放在第二个位置等等。

目前的索引推荐功能,是以pdf的方式发送给用户,效果如上图所示。
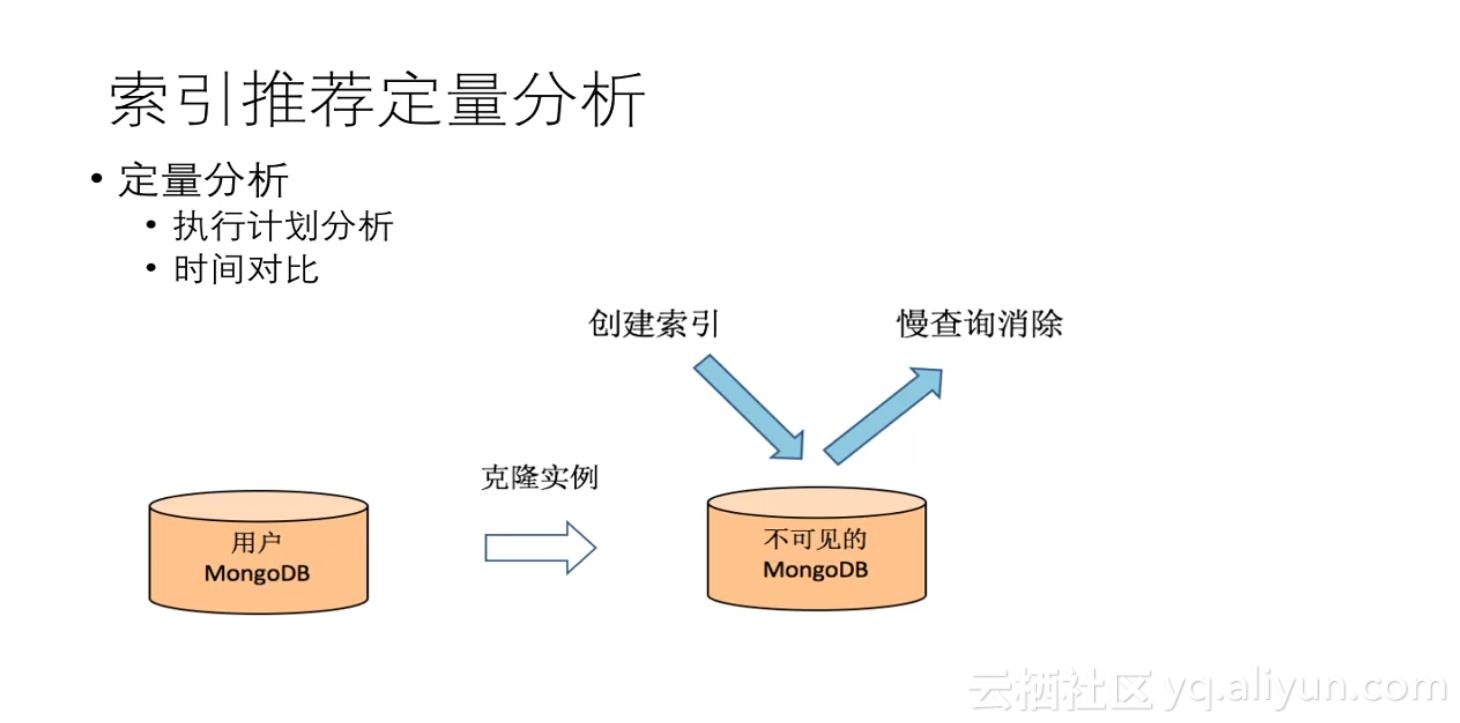
推荐的索引会自动克隆出一个用户不可见的MongoDB数据库,系统会在该数据库创建索引,来比对索引创建前后的计划、执行时间有无降低、慢查询有无消除等。该查询结果信息会反馈给用户,让用户决策该索引是否需要创建。目前定量分析是免费提供给用户使用。
截至到目前,索引推荐服务试用内测了三个月,经历了两代架构调整,按照推荐去建索引的用户,慢查询量明显下降。有用户按照推荐建索引,每天减少90多万条慢查询,占其慢查询总量99.5%以上。














 1897
1897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









