







简介:YOLOX算法是YOLO系列的改进版本,它通过优化网络结构和训练策略来提升目标检测的性能和速度。本项目实现了YOLOX算法在Keras上的应用,让使用者能够训练自己的数据集并生成适用于特定场景的权重。本项目的源码包括模型定义、数据预处理、损失函数、训练过程、验证与评估以及权重的保存与加载等关键部分,为用户提供了一个完整的YOLOX目标检测算法学习和应用工具链。 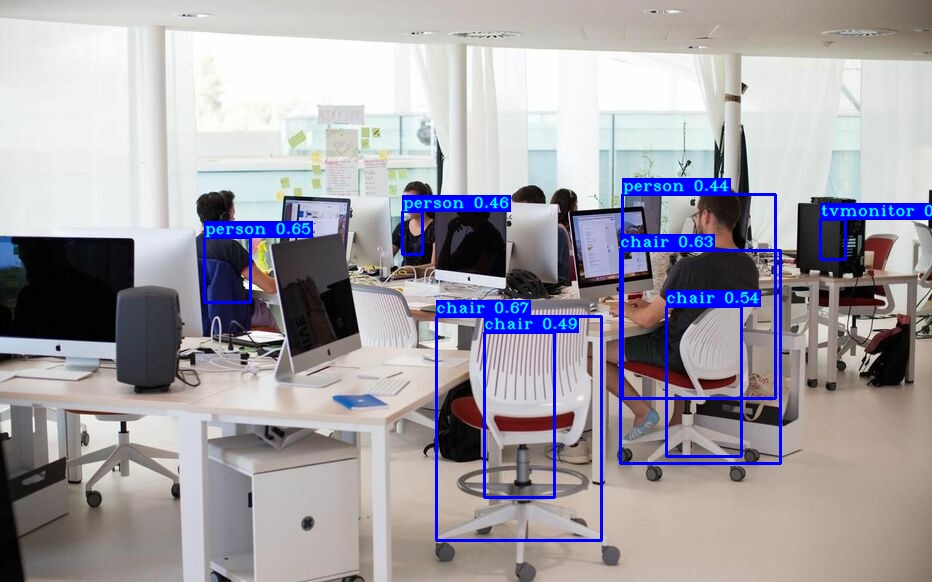
1. YOLOX算法介绍与优化
YOLOX算法的背景
YOLOX是YOLO(You Only Look Once)系列目标检测算法的一个最新变种。它在保持YOLO快速高效特点的同时,引入了诸如anchor-free机制和多尺度预测等创新技术,以提升检测的精度。算法的优化思路和实际应用已逐渐受到业界关注。
算法核心优势
YOLOX的核心优势之一是它抛弃了传统YOLO版本中使用的anchor机制。Anchor-free设计降低了模型的复杂度,并在某种程度上提高了检测的速度与准确性。此外,YOLOX还引入了其他先进的深度学习技术,例如利用空间金字塔池化(SPP)增强特征图的表达能力,以及通过增强特征融合来提高小目标检测的能力。
算法优化路径
为了在各种应用场景中达到最佳性能,YOLOX算法提供了多个优化路径。开发者可以通过调整超参数、采用不同的损失函数设计或改进网络结构来提升模型的性能。例如,针对硬件资源有限的情况,可以通过减少模型的参数量和计算量来优化模型的实时性能,或者通过模型剪枝技术来加速推理速度。
在下一章节中,我们将探讨YOLOX算法在Keras框架上的具体实现细节,以及如何搭建起YOLOX的基本模型架构。这将为理解YOLOX的深入优化奠定基础。
2. YOLOX在Keras上的实现
2.1 模型架构的搭建
2.1.1 YOLOX模型的基本结构
YOLOX(You Only Look Once X)是基于YOLO系列目标检测算法的进一步改进,它继承了YOLO的高效性,同时通过引入一些新的技术来提升检测精度。YOLOX模型基本结构主要由三个部分组成:Backbone(主干网络)、Neck(连接网络)和Head(输出网络)。Backbone负责提取图像特征,Neck将特征进行融合,而Head负责最终的预测任务。
2.1.2 Keras框架下的模型搭建方法
在Keras框架中搭建YOLOX模型,首先需要定义这三个主要的组成部分。Keras提供了丰富的API来构建深度学习模型。使用 Sequential 或者 Functional API 可以构建出Backbone,然后将特定设计的Neck和Head连接上。在构建过程中,可以利用Keras预定义的层,例如 Conv2D , BatchNormalization , LeakyReLU 等,来构造出复杂的网络结构。
2.2 网络组件的集成
2.2.1 Darknet网络的集成
Darknet是一个非常流行的用于目标检测的网络结构,YOLOX沿用了Darknet作为其基础网络。在Keras中集成Darknet网络相对简单,可以通过定义一个新的 Model 类,将Darknet的各个层按照顺序进行堆叠。下面是一个简化的Darknet网络层定义示例:
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, BatchNormalization, LeakyReLU, Input, MaxPooling2D, Flatten
from tensorflow.keras.models import Model
def darknet_block(x, filters, size=3, strides=1):
x = Conv2D(filters=filters, kernel_size=(size, size), strides=strides, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.1)(x)
return x
# Define Darknet structure
input_image = Input(shape=(None, None, 3))
x = darknet_block(input_image, filters=32, size=3)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = darknet_block(x, filters=64)
# ... continuing the Darknet architecture ...
2.2.2 YOLOX特有的网络组件
YOLOX在Darknet的基础上增加了一些特有的网络组件,比如SPP (Spatial Pyramid Pooling)和PAN (Path Aggregation Network)。这些组件为YOLOX提供了更好的特征表达能力。SPP可以增强模型对于不同尺寸目标的适应性,而PAN有助于信息在特征层之间的更高效流动。
2.3 性能优化与调优
2.3.1 模型加速与优化技术
为了在保持YOLOX检测精度的同时提升性能,可以从多个层面进行优化。在Keras框架中,常见的性能优化技术包括使用高效层、减少网络冗余和利用特定硬件的加速功能。例如,将标准卷积替换为深度可分离卷积可以显著降低模型的计算成本,而且Keras已经内置了 DepthwiseConv2D 层来支持这种操作。
2.3.2 针对不同硬件的优化策略
针对不同的硬件平台,可以采用不同的优化策略。例如,在GPU上可以使用混合精度训练来加速模型训练过程,而在CPU上则可能需要利用模型量化或者模型剪枝等技术来提升推理速度。在Keras中,可以利用TensorFlow后端的特性来启用这些优化功能。
下面的代码展示了如何在Keras中启用混合精度训练:
from tensorflow.keras import mixed_precision
policy = mixed_precision.Policy('mixed_float16')
mixed_precision.set_global_policy(policy)
# After setting the policy, ***
***pile(optimizer='adam', loss='categorical_crossentropy')
通过本章节的介绍,我们理解了YOLOX在Keras框架上的实现方式,从基础的模型架构搭建到网络组件的集成,再到性能优化与调优。这些内容对于构建高效、准确的目标检测模型至关重要,也为后续章节中模型训练和性能评估提供了扎实的基础。
3. 训练自定义数据集生成权重
3.1 数据集的准备与预处理
3.1.1 数据集的收集和整理
在计算机视觉任务中,数据集的质量直接影响到模型训练的效果和最终的泛化能力。因此,数据集的准备是至关重要的一步。在准备数据集时,我们需要考虑以下几个方面:
- 数据多样性:确保数据集包含足够多的变化,例如不同的视角、光照条件、背景和物体大小等。
- 数据标注精度:标注必须精确,这是保证模型训练过程中能够正确学习特征的前提。
- 数据量:一般来说,数据量越大,模型训练的效果越好,但同时也意味着更高的计算成本。
- 数据隐私和版权:在使用数据集时,必须确保遵守相关的隐私和版权规定。
数据集的收集通常可以分为两大类:公开数据集和私有数据集。公开数据集可以通过网络搜索获得,如COCO、PASCAL VOC等。私有数据集则需要我们自己收集和标注,这可能涉及到数据采集设备(如相机、无人机等)的使用,以及后续的标注工作。
3.1.2 图像的标注与格式转换
图像标注是将图像中感兴趣的目标用边界框的形式标记出来,并对每个目标进行分类的过程。标注的准确性直接关系到模型训练的质量。常见的图像标注工具有LabelImg、CVAT等,这些工具能够帮助我们快速准确地标记图像中的对象。
标注完成后,需要将标注信息转换为模型训练所需的格式。例如,YOLO系列模型通常需要的标注文件格式为 .txt ,每行包含目标的类别ID、中心点坐标(x, y)以及宽度和高度信息。
下面是一个标注文件的示例代码:
0 0.506885 0.293115 0.572500 0.***
***.493115 0.485714 0.544375 0.***
***.485714 0.548571 0.531250 0.697143
在这段标注信息中,每一行代表一个目标,第一个值是类别索引,后四个值分别是目标边界框的中心点坐标(x, y)和宽度、高度(归一化到0-1之间)。
完成图像的收集、标注和格式转换之后,数据集的准备工作就完成了。接下来,我们可以使用这些数据来训练YOLOX模型,并生成我们自己的权重。
3.2 权重训练的初始化
3.2.1 预训练权重的下载与使用
预训练权重通常指的是在大规模数据集上预先训练好的模型参数。使用预训练权重作为模型训练的起点能够加速训练过程,并且有助于模型更好地收敛,特别是在数据集较小的情况下。YOLOX模型也支持使用预训练权重来初始化训练过程。
一般来说,从官方或可信的源下载预训练权重是推荐的做法。使用预训练权重时,需要注意权重的来源与版本,确保它们与我们使用的模型架构和代码版本兼容。例如,在Keras框架中,加载预训练权重的代码可能如下:
from tensorflow.keras.models import load_model
# 假设我们已经下载了YOLOX的预训练权重文件 'yolox_weights.h5'
model = load_model('yolox_weights.h5')
加载预训练权重后,可以根据需要冻结某些层或者继续训练整个网络以适应新的数据集。
3.2.2 模型的配置与训练准备
在训练YOLOX模型之前,需要对其模型配置进行适当的调整以适应新的数据集。这包括设置类别数、调整网络的输入尺寸、设置训练的参数等。此外,还需要设置一些训练的策略,比如批处理大小、学习率等。
配置文件(通常以 .yaml 格式存在)是调整这些参数的主要方式。下面是一个配置文件的简单示例:
model:
name: YOLOX
backbone:
name: C3Ghost
depth_multiple: 0.33
width_multiple: 0.50
neck:
name: YOLOXPAFPN
num_repeat: 1
head:
name: YOLOXHead
act: silu
num_classes: 80 # 根据你的数据集类别数进行修改
train:
batch_size: 8
subdivisions: 1
train_image_folder: /path/to/train/images
train_anno_***
***
***
***
***
***
***
***
***
在上述配置文件中,模型参数(如backbone结构、neck、head等)、训练参数(如batch_size、learning_rate等)以及优化器参数均可以进行自定义配置。在实际应用中,可能还需要根据具体情况进行细致调整以获得最优的训练效果。
完成这些配置之后,就可以进入模型的训练阶段了。
3.3 自定义数据集的训练过程
3.3.1 训练参数的设置
在开始训练之前,合理设置训练参数是至关重要的。这些参数包括学习率、损失函数、优化器选择等。学习率决定了参数更新的步长大小,是影响模型收敛速度和效果的关键因素。通常,我们会采用一些策略来动态调整学习率,例如学习率预热(warmup)和周期性衰减。
接下来,我们以Keras框架为例,展示如何配置训练参数:
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
# 设置优化器
optimizer = Adam(learning_rate=1e-3, beta_1=0.9, beta_2=0.999, decay=0.0)
# 设置学习率调度
def scheduler(epoch, lr):
if epoch < 10:
return lr
else:
return lr * tf.math.exp(-0.1)
# 保存最佳权重的回调函数
checkpoint = ModelCheckpoint('best_yolox.h5', save_best_only=True, monitor='val_loss', mode='min')
# 设置回调函数
callbacks = [checkpoint, LearningRateScheduler(scheduler)]
在上述代码中,我们定义了一个学习率调度器和一个模型检查点回调函数,以保存最佳的模型权重。
3.3.2 模型的训练与监控
在一切准备就绪之后,我们可以开始模型的训练过程。在Keras中,模型训练主要通过 fit 方法完成。下面是一个训练过程的代码示例:
model.fit(
train_data,
validation_data=val_data,
epochs=50,
callbacks=callbacks,
verbose=1
)
在这个例子中, train_data 和 val_data 分别是训练和验证数据集。我们设定训练的总轮次为50轮,同时应用之前定义的回调函数。训练过程中,我们可以监控各种指标来评估模型的训练效果,例如损失函数的值、准确率等。
在训练过程中,应当对模型的性能进行监控,确保模型没有过拟合或欠拟合,并根据监控结果对训练参数进行适当的调整。
在训练完成后,我们可能需要对模型进行评估,以确定模型在独立测试集上的泛化能力。这时可以使用一些评估指标,如mAP(mean Average Precision)等,来衡量模型性能。对于目标检测任务来说,mAP是一个常用的评估指标,它综合考虑了模型的分类准确性和定位精度。
最终,我们可以使用训练好的模型权重进行推理,对新的图像进行目标检测。这将是下一章讨论的重点内容。
4. ```
第四章:模型结构定义与训练策略
4.1 YOLOX的网络层定义
4.1.1 网络层功能与作用
YOLOX,作为对YOLO系列网络的一种改进,其网络层定义是实现高性能检测的关键。每一个网络层都有其特定的功能和作用,比如卷积层用于提取特征,池化层用于降维,激活层用于引入非线性。对于YOLOX而言,其网络层设计在保持了Darknet的高效特征提取能力的同时,也引入了一些新的网络组件,比如CSPNet结构,用以进一步提高模型的表现。
在深度学习模型中,网络层的组合和层次结构决定了模型的复杂度和抽象能力。YOLOX模型通过精心设计的层次结构,能够逐步从简单的边缘和纹理等低级特征,抽象到高级特征,如物体的形状和类别等。这样的结构设计能够使模型更好地适应复杂的图像检测任务。
4.1.2 各层参数的设置方法
在Keras框架中,设置网络层参数的过程相对直观和简单。例如,在实现YOLOX的网络层时,每一个卷积层、池化层或者全连接层都需要指定其过滤器数量、核大小、激活函数等参数。在设置这些参数时,需要考虑模型的深度、宽度以及网络的容量等因素。
例如,卷积层的一个关键参数是过滤器(filter)的数量,它决定了该层的输出特征图的深度。过滤器数量过少可能导致特征提取不足,而数量过多可能会增加模型的计算量并导致过拟合。另外一个重要的参数是卷积核(kernel)的大小,它决定了接受域的范围。大的卷积核可以捕获更宽泛的上下文信息,但同时也会增加计算量。
在YOLOX模型中,除了这些常规参数外,还需要关注如深度可分离卷积、残差连接等高级结构的配置,它们对于构建高效和准确的检测器至关重要。
4.2 训练策略的设计
4.2.1 学习率调度策略
学习率调度策略是模型训练过程中的一个关键因素,它可以显著影响训练的稳定性和最终模型的性能。一个常见的策略是在训练初期使用较大的学习率,以快速地进行权重更新;随着训练过程的进行,逐渐减小学习率以获得更精细的权重调整。
在YOLOX模型的训练中,可以使用一些先进的学习率调度策略,比如余弦退火学习率、周期性学习率变化等。这些策略可以在训练过程中动态调整学习率,帮助模型更好地收敛。
在Keras中,可以通过回调函数(callbacks)机制实现这些学习率调度策略。例如, LearningRateScheduler 回调函数允许用户定义自己的学习率调整逻辑,根据训练阶段动态改变学习率。
4.2.2 批处理大小与优化器的选择
批处理大小(batch size)是训练深度学习模型时另一个需要考虑的重要因素。较大的批处理大小可以利用GPU的高效并行计算能力,加速模型训练,但同时也可能导致梯度估计的方差增大,影响模型的收敛性。
在实际操作中,批处理大小的选择需要权衡模型的内存占用和训练速度。例如,在YOLOX模型训练时,可能需要在保证训练稳定性的前提下,尽可能使用较大的批处理大小,以缩短训练时间。
除了批处理大小,选择合适的优化器也至关重要。优化器负责根据损失函数来更新网络权重。常见的优化器包括SGD、Adam、RMSprop等。在YOLOX模型训练中,可以考虑使用Adam优化器,因为它结合了RMSprop和Momentum两种优化器的优点,能够提供更快的收敛速度和更好的稳定性。
在Keras中配置优化器非常简单,只需要在模型编译时指定优化器类型和参数即可。例如:
``` pile(optimizer=Adam(learning_rate=0.001), loss='categorical_crossentropy')
在上述代码中,我们将学习率设置为0.001,并选择了Adam作为优化器,这将帮助YOLOX模型在训练过程中有效地优化权重。
**注解:**
在本章中,我们对YOLOX模型结构定义中的网络层功能与作用进行了阐述,并详细讨论了网络层参数设置的重要性。我们还探讨了设计高效训练策略时所必须考虑的学习率调度策略、批处理大小和优化器选择。下一章将着重讨论数据预处理流程,这是模型训练前非常关键的一个步骤,它直接影响到模型能否学习到有效的特征表示。
5. 数据预处理流程
在深度学习中,模型的性能往往受限于输入数据的质量和多样性。因此,数据预处理流程是计算机视觉任务中至关重要的一步。本章将详细探讨数据预处理流程,包括数据增强技术和输入数据的标准化处理。
5.1 数据增强技术
5.1.1 常见的数据增强方法
数据增强是一种在不收集新数据的情况下增加数据多样性的技术。在目标检测任务中,以下是一些常用的数据增强方法:
- 图像旋转(Rotation) :通过旋转图像来增加模型对目标方向的鲁棒性。
- 缩放(Scaling) :对图像进行放大或缩小,增加模型对目标大小变化的适应能力。
- 平移(Translation) :水平或垂直移动图像中的内容,以模拟目标的位移。
- 翻转(Flipping) :对图像进行水平或垂直翻转,以增加模型对目标方向变化的识别能力。
- 色彩变换(Color Jittering) :调整图像的亮度、对比度和饱和度,模拟不同光照条件下的图像变化。
- 噪声注入(Noise Injection) :在图像中加入随机噪声,提高模型对噪声的容忍度。
from imgaug import augmenters as iaa
# 定义一系列的数据增强操作
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 50%的概率水平翻转
iaa.Flipud(0.2), # 20%的概率垂直翻转
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # 缩放
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}, # 平移
rotate=(-15, 15) # 旋转
),
iaa.GammaContrast(gamma=(0.8, 1.2)) # 色彩变换
])
5.1.2 数据增强对模型性能的影响
恰当的数据增强可以显著改善模型的泛化能力。通过模拟训练数据集中不存在的各种变化,数据增强能够帮助模型学习到更为鲁棒的特征表示。例如,在图像识别任务中,数据增强可以使得模型对于目标的不同角度、不同光照条件以及遮挡情况下的表现更加稳定。
然而,数据增强的策略必须精心设计,不恰当的数据增强可能会引入噪声,干扰模型的训练过程。因此,实验不同的数据增强组合并验证其效果是模型开发的重要一环。
5.2 输入数据的标准化处理
5.2.1 图像的归一化方法
图像的归一化是将图像数据缩放到一个标准的数值范围内,这通常是通过减去数据集的平均值并除以标准差来完成的。在深度学习框架中,这一过程可以通过数据加载管道自动完成。
from keras.preprocessing.image import ImageDataGenerator
# 创建一个ImageDataGenerator实例用于数据归一化
datagen = ImageDataGenerator(
featurewise_center=True, # 对数据集进行标准化
featurewise_std_normalization=True
)
# 计算数据集的统计信息(均值和标准差),然后应用到数据上
datagen.fit(x_train)
5.2.2 处理流程的实现与优化
在使用数据增强和归一化处理的过程中,要合理安排处理流程的实现,这包括:
- 并行处理 :当处理大量数据时,可以使用多线程或GPU加速数据增强和归一化的计算。
- 缓存机制 :将处理过的数据缓存起来,避免重复处理同一个样本,这样可以显著提高效率。
- 在线与离线处理 :对于实时性要求不高的场景,可以采用离线处理的方式,预先将数据处理好存入硬盘,训练时直接从硬盘读取。
数据预处理流程的设计和优化,直接影响到深度学习模型的训练效率和最终性能,必须给予足够的重视。在下一章节中,我们将继续深入了解YOLOX模型的结构定义及其训练策略。
6. 损失函数的定义与分类、定位损失
6.1 损失函数的作用与原理
损失函数是深度学习中优化模型的核心组件,用于衡量模型预测值与真实值之间的差异。在目标检测任务中,损失函数尤为关键,因为它需要处理分类准确性和目标定位精度两个不同的问题。
6.1.1 损失函数的类型与选择
在目标检测领域,最常用的损失函数是YOLO系列的损失函数,它结合了多个子损失函数,包括分类损失、定位损失和目标存在性损失。对于YOLOX模型,主要关注分类损失和定位损失。
分类损失通常使用交叉熵损失函数,适用于处理多类别分类问题。定位损失则根据所选的目标检测架构的不同而有所变化,如YOLOv3使用了均方误差损失函数进行定位。
选择正确的损失函数对于提高模型性能至关重要。例如,YOLOX使用了二元交叉熵(Binary Cross-Entropy)作为分类损失,并引入了DIoU(Distance IoU)作为定位损失,以更准确地度量预测框与真实框之间的距离,从而优化了定位性能。
6.1.2 损失函数在训练中的重要性
损失函数直接决定了模型在训练过程中的优化方向。优化损失函数,实际上是在调整模型权重,以减少预测值与真实值之间的差异。好的损失函数能更敏感地反映模型预测的准确度,从而加速模型的收敛速度,并提高最终的模型性能。
6.2 分类损失与定位损失的实现
6.2.1 分类损失的计算方式
在YOLOX模型中,分类损失通常使用二元交叉熵损失函数。对于一个目标,它的计算公式如下:
def binary_cross_entropy_loss(y_true, y_pred):
# y_true 是一个包含真实标签的张量
# y_pred 是一个包含预测概率的张量
return -tf.reduce_sum(y_true * tf.math.log(y_pred + eps))
在这个函数中, y_true 是一个包含0和1的二元数组,表示每个类别的存在性。 y_pred 是一个概率值,表示每个类别被正确分类的概率。 eps 是避免对0取对数的小常数。
6.2.2 定位损失的计算与优化
定位损失关注的是目标的边界框预测准确性。在YOLOX中,使用DIoU作为定位损失。DIoU计算了预测框与真实框中心点之间的距离以及两个框的交并比(IoU),这有助于使预测框更快地与真实框重合。
DIoU的计算公式如下:
def diou_loss(y_true, y_pred):
# y_true 和 y_pred 分别是真实框和预测框的坐标
# 计算框中心点之间的距离
c2 = tf.reduce_sum(tf.square(y_true - y_pred), axis=-1)
# 计算框之间的IoU
u = (y_true[:, 0] + y_true[:, 2]) * (y_true[:, 1] + y_true[:, 3])
v = (y_pred[:, 0] + y_pred[:, 2]) * (y_pred[:, 1] + y_pred[:, 3])
iou = (u + eps) / (v + eps) - c2 / ((u - v) ** 2 + eps)
# 计算中心点距离和IoU的组合
diou = iou - (b_true - b_pred).square() / ((c_true - c_pred).square() + eps)
return tf.reduce_mean(1 - diou)
通过这样的计算,模型能够更加关注于优化边界框的位置,尤其是在目标重叠或者密集场景中表现更为出色。
在实际应用中,除了上述的分类损失和定位损失,还会有其他辅助损失函数,如目标存在性损失(objectness loss),用于平衡模型对于有无目标的关注程度。这种损失函数通常会在模型的多个输出层上实现,有助于提高对小目标或者遮挡目标的检测能力。
7. 模型训练与性能评估
7.1 训练参数的设置与模型保存
在深度学习模型训练过程中,合理配置训练参数是至关重要的。这些参数包括但不限于学习率、批次大小、迭代次数和优化器类型。这些参数的选择会直接影响模型的收敛速度、训练稳定性以及最终的性能。
7.1.1 训练过程中的关键参数
- 学习率(Learning Rate) :学习率决定了权重更新的幅度,过高可能导致模型无法收敛,过低则会导致训练过程缓慢。可以通过学习率预热(warm-up)和学习率衰减策略动态调整学习率。
-
批次大小(Batch Size) :批次大小是每次迭代中用于模型更新的样本数量。较小的批次大小有利于模型捕捉数据的多样性,但可能会增加训练时间。较大的批次大小可以加速训练,但可能会降低模型的泛化能力。
-
迭代次数(Epochs) :迭代次数是指模型遍历整个训练数据集的次数。过多的迭代次数可能会导致过拟合,而太少则可能导致欠拟合。
-
优化器(Optimizer) :优化器是用于最小化损失函数的算法,常见的有SGD、Adam和RMSprop等。不同的优化器可能会对模型的收敛速度和性能产生影响。
# 示例代码:设置Keras模型训练参数
from keras.optimizers import Adam
# 学习率、批次大小和迭代次数
learning_rate = 0.001
batch_size = 32
epochs = 50
# 创建优化器并传入学习率
optimizer = Adam(learning_rate=learning_rate)
# 编译模型时设置优化器
***pile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
7.1.2 权重的保存与备份方法
为了防止训练过程中的意外情况导致模型权重丢失,应该定期保存训练过程中的最佳模型。这样即使训练中断,也可以从中断的地方继续训练,或者在需要时回滚到之前的最优状态。
# 使用Keras的回调函数保存模型
from keras.callbacks import ModelCheckpoint
# 设置保存模型的回调函数
checkpoint = ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True, mode='min')
# 编译模型时添加回调
***pile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=epochs, validation_data=(X_val, y_val), callbacks=[checkpoint])
7.2 性能验证与模型评估
模型训练完成后,需要对其性能进行验证和评估,这包括使用验证集进行内部验证和使用测试集进行性能测试。
7.2.1 评估指标的选择与计算
常用的评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-Score)以及混淆矩阵(Confusion Matrix)。针对不同的应用,某些指标比其他指标更重要。例如,在不平衡数据集中,召回率可能比准确率更受关注。
from sklearn.metrics import classification_report
# 假设y_true为真实标签,y_pred为模型预测标签
report = classification_report(y_true, y_pred)
print(report)
7.2.2 模型的对比与分析
在多个模型的对比中,应使用相同的评估标准和数据集。通过比较不同模型的性能指标,可以分析出哪个模型更适合当前的任务。在模型评估时,还应考虑模型的复杂度、训练时间和资源消耗等因素。
# 示例表格展示两个模型的性能对比
| 模型 | 准确率 | 精确率 | 召回率 | F1分数 | 训练时间 |
|--------|----------|----------|----------|----------|----------|
| 模型A | 0.95 | 0.93 | 0.94 | 0.935 | 1小时 |
| 模型B | 0.96 | 0.94 | 0.95 | 0.945 | 2小时 |
模型的评估和对比是模型开发过程中不可或缺的一部分,它不仅帮助我们验证模型的有效性,还能指导我们在后续的研究中不断改进模型。在实际应用中,通过综合考虑模型的性能指标和实际应用的需求,可以作出更合理的模型选择决策。
简介:YOLOX算法是YOLO系列的改进版本,它通过优化网络结构和训练策略来提升目标检测的性能和速度。本项目实现了YOLOX算法在Keras上的应用,让使用者能够训练自己的数据集并生成适用于特定场景的权重。本项目的源码包括模型定义、数据预处理、损失函数、训练过程、验证与评估以及权重的保存与加载等关键部分,为用户提供了一个完整的YOLOX目标检测算法学习和应用工具链。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









