







目录
1. 为什么使用partition by, 而不是group by?
2. 为什么使用row_numbe,而不是rank 或者dense_rank?
一、提取患者首次入ICU信息


思路:
-
患者入ICU信息存储在mimic_icu.icustays表中,intime为患者入ICU的时间。我们的思路是根据患者的subject_id分组 (分组SQL我们一般使用:group by 或者 partition by )
-
然后以intime升序排序,看每行记录对应的是该患者第几次入ICU,
-
最后取第一次入ICU的,即为首次入ICU信息。
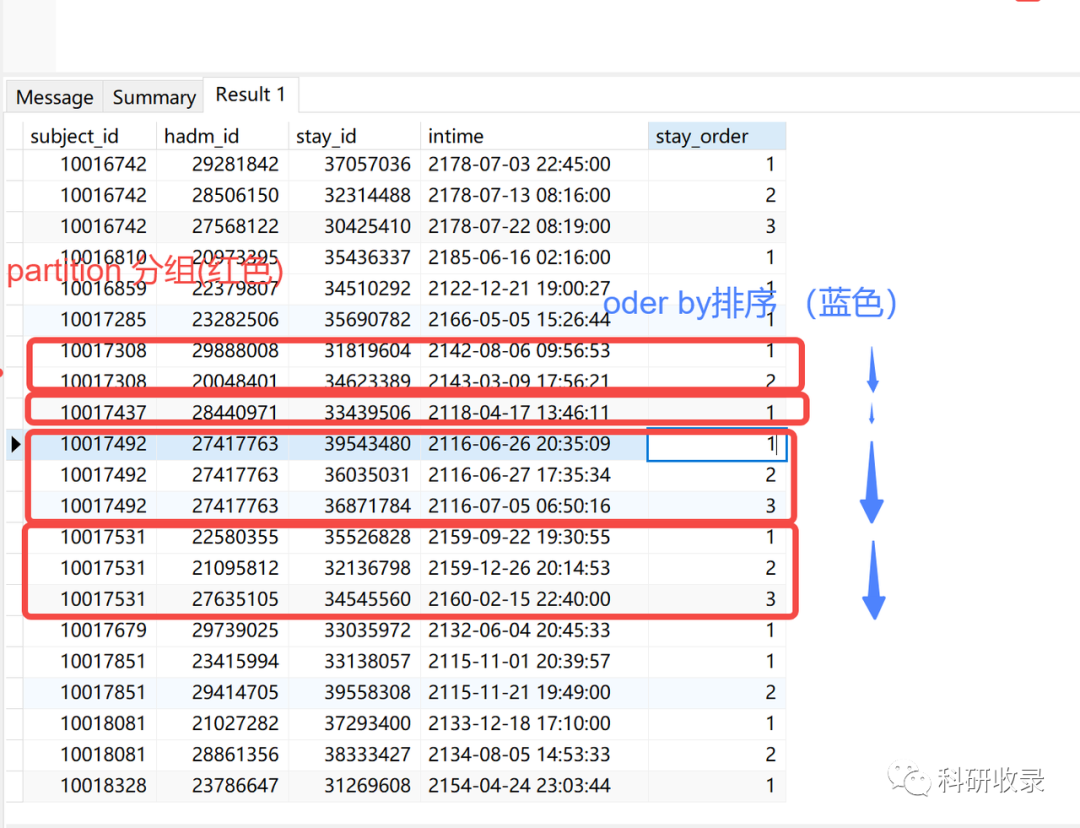
比如233患者三次入ICU,我们需要根据入ICU时间intime从小到大生成排名,也就是入ICU顺序

这里stay_id 410这条就是患者233首次入icu的信息
为了实现这个思路,我们需要用到row_number()排名函数,用SQL实现如下

这个SQL的意思是:以subject_id分组,每组以intime从小到大排序,生成排名,比如该subject_id下最小的intime所在的这一行,排名设为1。

-
按照subject_id分组: partition by用来对表分组,在这个例子中,所以我们指定了按“subject_”分组(partition by subject_id)
-
按intime排名: order by子句的功能是对分组后的结果进行排序,默认是按照升序(asc)排列, 在本例中(order by intime)是按intime这一列排序,加了desc关键词表示降序排列。
通过下图,我们就可以理解partiition by(分组)和order by(在组内排序)的作用了。
接着,我们需要从这个查询的结果中取stay_order=1的,那么如何从这些查询结果中再查询数据呢?有很多种方式都可以实现,比如将上述查询的结果创建成表、物化视图、或者用子查询,这里介绍一个比较优雅的常用的方案,with子句。
with可以将查询结果作为一个临时表,供后续查询复用该临时表,这样可以将复杂的大型查询分解为多次简单查询
用SQL实现提取首次入ICU信息:
WITH stay_order_view AS (
SELECT
subject_id,
hadm_id,
stay_id,
intime,
-- 以subject_id分组, 每组以intime从小到大排序(默认升序),生成排名
ROW_NUMBER ( ) OVER ( PARTITION BY subject_id ORDER BY intime ) AS stay_order
FROM
mimiciv_icu.icustays
) SELECT
*
FROM
stay_order_view
WHERE
stay_order = 1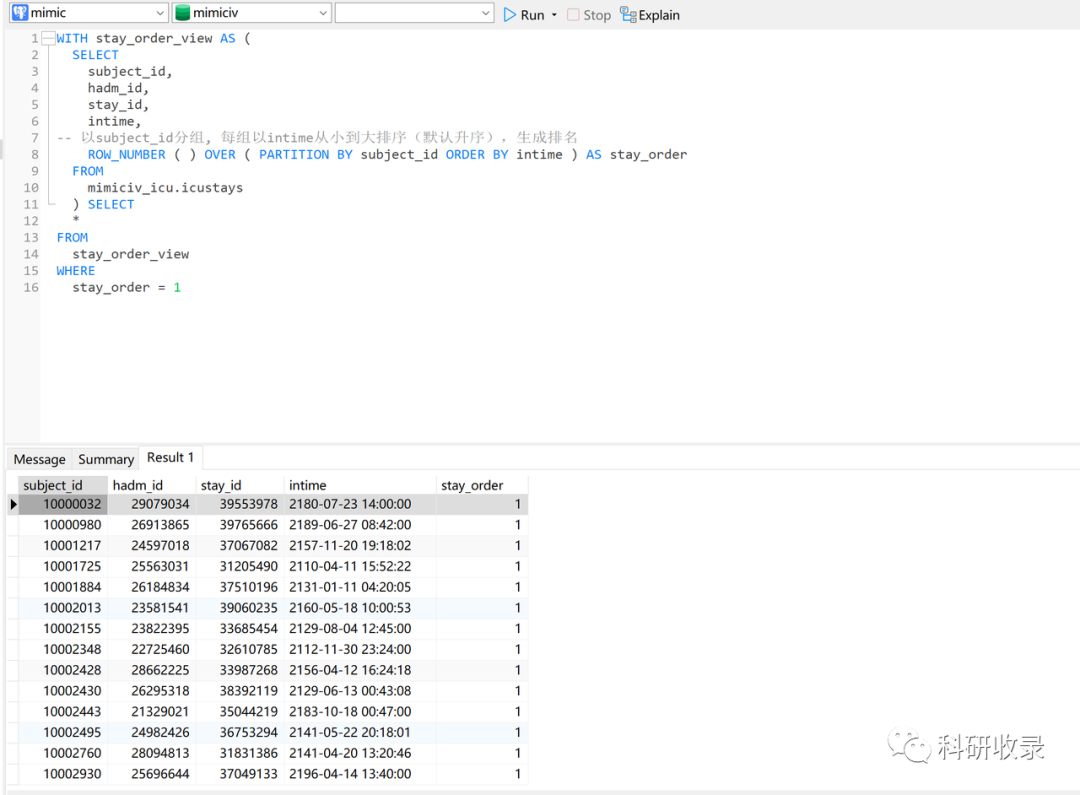
我们前面生成患者入ICU顺序的语句放到stay_order_view这个临时表中,然后从stay_order_view中获取in_order=1的所有数据,查询结果如下,可以看到提取出了患者首次入ICU的stay_id。
然后如果要获取患者首次入ICU的其他信息,只需要用该查询结果中的stay_id或者hadm_id在其他表进行关联查询即可
1. 为什么使用partition by, 而不是group by?
group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。例如下面统计每个医院的人数。


这里主要两个作用
-
同时具有分组和排序的功能
-
不减少原表的行数
注意事项partition子句是可省略,省略就是不指定分组
2. 为什么使用row_numbe,而不是rank 或者dense_rank?
专用窗口函数rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:

得到结果:
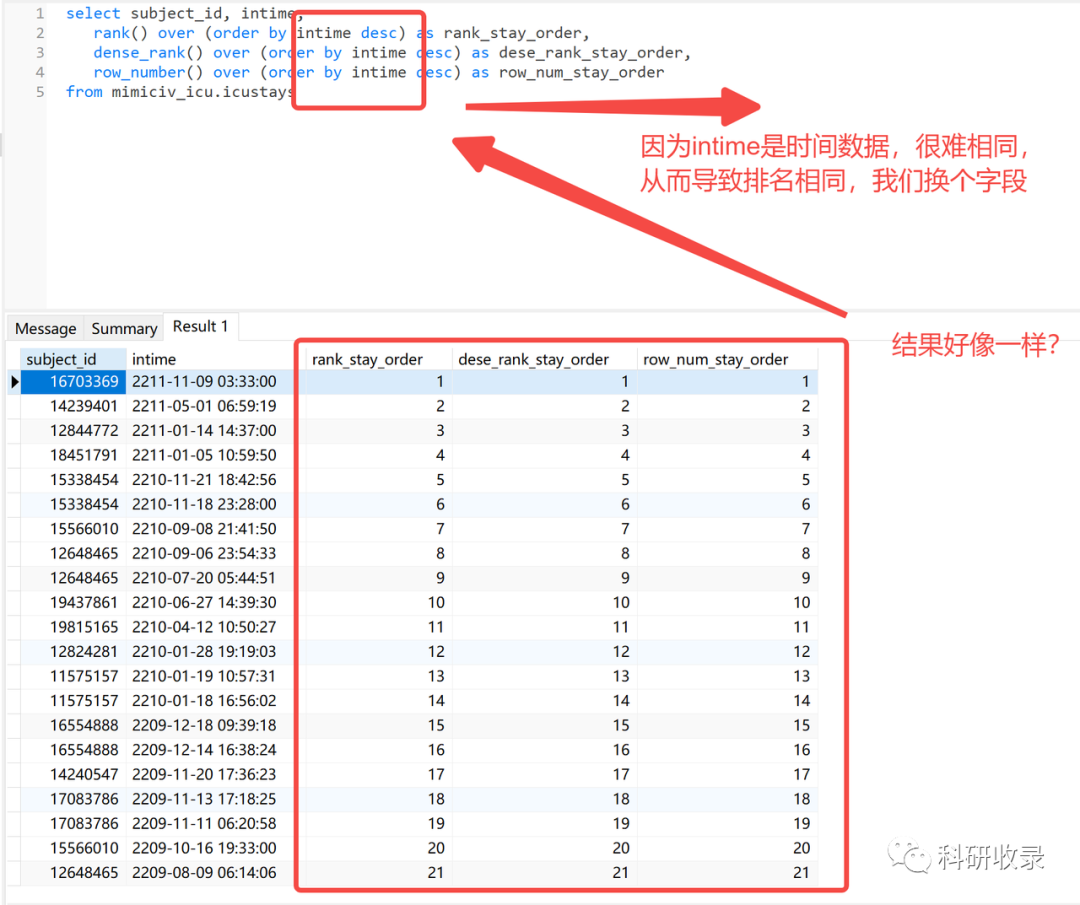
我们把intime字段换成subject_id, 因为subject_id是有可能相同的

从上面的结果可以看出:
rank函数:这个例子中是7位,7位,9位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
dense_rank函数:这个例子中是7位,7位,8位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
row_number函数:这个例子中是7位,8位,9位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
这三个函数的区别如下:

二、提取进入ICU的基线检验数据(铁蛋白FER为例)

很多同学反馈装好mimic数据库后,发现数据量太大,无从下手。
对于初学者来说,这些数据完全用不上。
我们只需要进入ICU的基线数据,
就可以做出很好的临床研究了。
如何拿到基线检验结果,
帮大家集成了一段代码,
轻松搞定 MIMIC-IV 数据库第一天检查的
最大值,最小值,算数平均值和第一次的检查结果
下一章重点讲解 【提取进入ICU的基线检验数据(铁蛋白FER为例)】,感兴趣同学可以提前公众号后台回复"icu基线检查数据"获取代码
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









