









 本文详细介绍了如何配置和使用MIMIC-IV数据库的衍生表格mimic_derived,包括数据示例、衍生表格的生成步骤、实例应用(如计算患者真实年龄和筛选特定条件的首次入院记录),以及官方函数的安装和使用方法。
本文详细介绍了如何配置和使用MIMIC-IV数据库的衍生表格mimic_derived,包括数据示例、衍生表格的生成步骤、实例应用(如计算患者真实年龄和筛选特定条件的首次入院记录),以及官方函数的安装和使用方法。

有很多同学反馈上一篇文章
没有完全看懂,不知道如何配置物化视图或衍生表格 和使用衍生表格
本篇文章旨在系统介绍下衍生表格mimic_derived的配置, 并演示如何使用。
使用以下实例您还需要用到官方函数, 可以看往期这篇
一、MIMIC-IV数据库衍生表格(mimic_derived)简介
MIMIC IV数据库衍生表格实际上就是对数据库数据进一步归纳整理后的数据。由于
mimic_derived 参与了很多内容的查询,熟悉这个模块的内容还是很有必要的,但是官方
对这个模块缺乏详细的介绍。模块mimic_derived, 而且这个模块仅存在与谷歌云的mimic
数据库中, 本地建立的数据库中虽然有这个模块,但是没有内容,需要自己根据官方提供的
代码生成。
二、衍生表格示例
这些示例每一个后面都会单章一一讲解
1.age,为患者入院(admission)时的年龄,存储在age列。
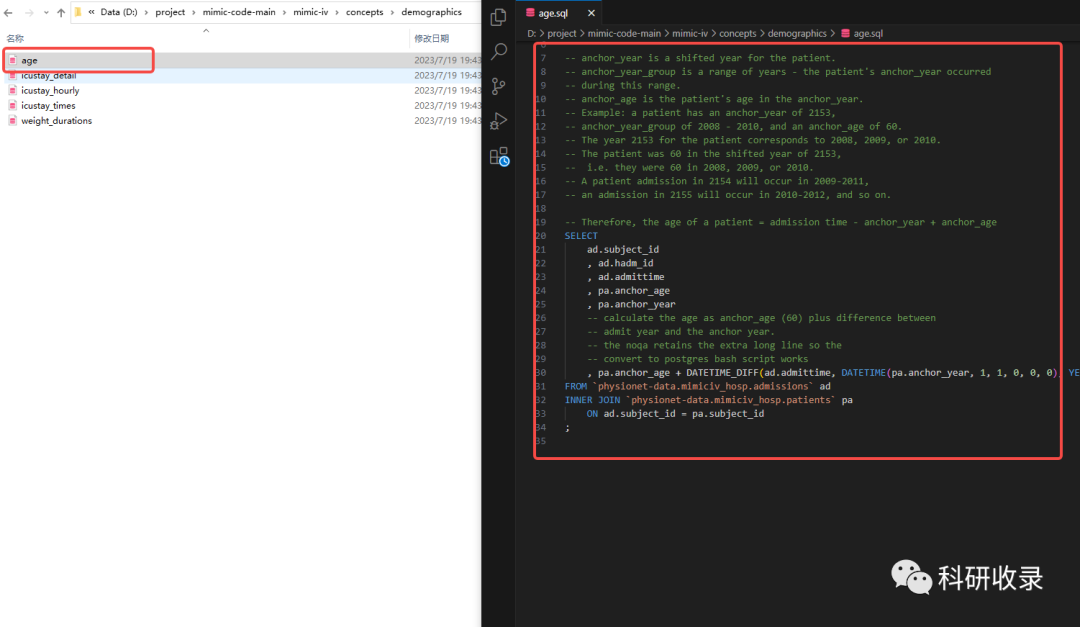
SELECTad.subject_id, ad.hadm_id, ad.admittime, pa.anchor_age, pa.anchor_year, mimiciv_derived.DATETIME_DIFF(ad.admittime, mimiciv_derived.DATETIME(pa.anchor_year, 1, 1, 0, 0,0),'YEAR') + pa.anchor_age AS ageFROM mimiciv_hosp.admissions AS adINNER JOIN mimiciv_hosp.patients AS paON ad.subject_id = pa.subject_id;
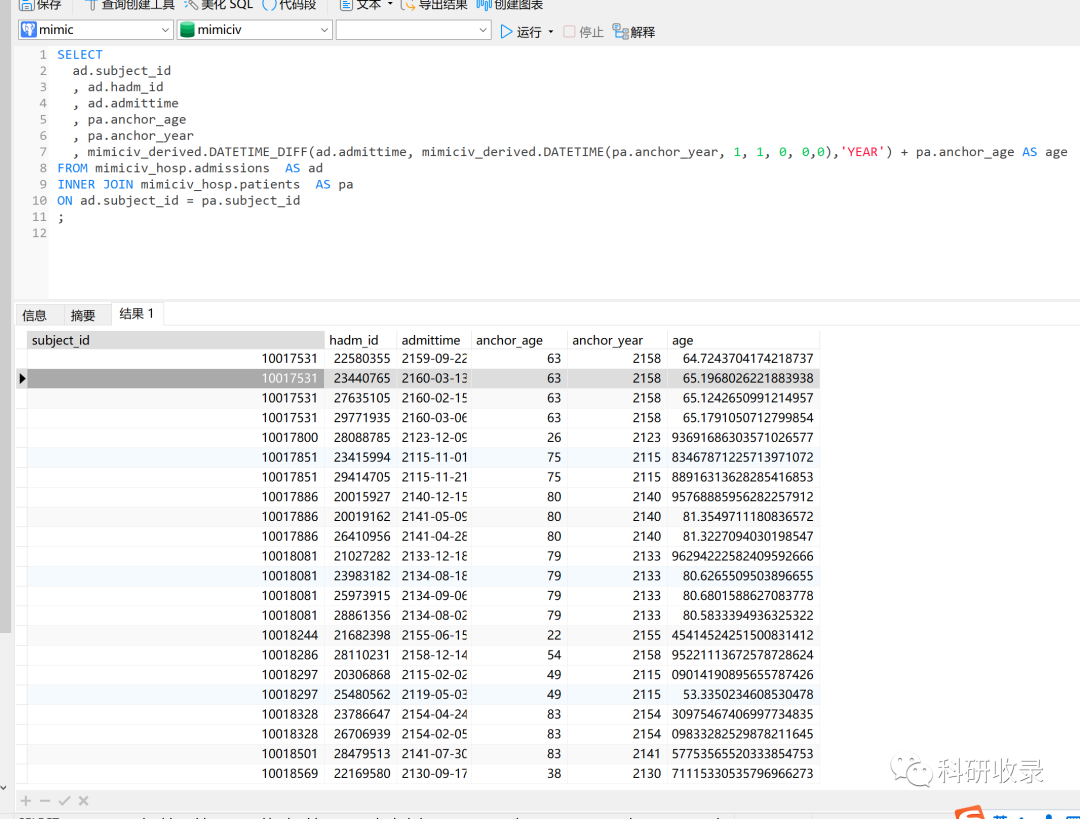
这里就使用了官方函数 "mimiciv_derived.DATETIME_DIFF" 和 “mimiciv_derived.DATETIME”, 如果您没有安装官方函数就会报错!
安装好的官方函数长这样:

2.weight_duration, ICU期间体重的变化,体重是反应患者营养状况的重要因素。
-- THIS SCRIPT IS AUTOMATICALLY GENERATED. DO NOT EDIT IT DIRECTLY.DROP TABLE IF EXISTS weight_durations; CREATE TABLE weight_durations AS-- This query extracts weights for adult ICU patients with start/stop times-- if an admission weight is given, then this is assigned from intime to outtimeWITH wt_stg as(SELECTc.stay_id, c.charttime, case when c.itemid = 226512 then 'admit'else 'daily' end as weight_type-- TODO: eliminate obvious outliers if there is a reasonable weight, c.valuenum as weightFROM mimic_icu.chartevents cWHERE c.valuenum IS NOT NULLAND c.itemid in(226512 -- Admit Wt, 224639 -- Daily Weight)AND c.valuenum > 0)-- assign ascending row number, wt_stg1 as(selectstay_id, charttime, weight_type, weight, ROW_NUMBER() OVER (partition by stay_id, weight_type order by charttime) as rnfrom wt_stgWHERE weight IS NOT NULL)-- change charttime to intime for the first admission weight recorded, wt_stg2 AS(SELECTwt_stg1.stay_id, ie.intime, ie.outtime, wt_stg1.weight_type, case when wt_stg1.weight_type = 'admit' and wt_stg1.rn = 1then DATETIME_SUB(ie.intime, INTERVAL '2' HOUR)else wt_stg1.charttime end as starttime, wt_stg1.weightfrom wt_stg1INNER JOIN mimic_icu.icustays ieon ie.stay_id = wt_stg1.stay_id), wt_stg3 as(selectstay_id, intime, outtime, starttime, coalesce(LEAD(starttime) OVER (PARTITION BY stay_id ORDER BY starttime),DATETIME_ADD(outtime, INTERVAL '2' HOUR)) as endtime, weight, weight_typefrom wt_stg2)-- this table is the start/stop times from admit/daily weight in charted data, wt1 as(selectstay_id, starttime, coalesce(endtime,LEAD(starttime) OVER (partition by stay_id order by starttime),-- impute ICU discharge as the end of the final weight measurement-- plus a 2 hour "fuzziness" windowDATETIME_ADD(outtime, INTERVAL '2' HOUR)) as endtime, weight, weight_typefrom wt_stg3)-- if the intime for the patient is < the first charted daily weight-- then we will have a "gap" at the start of their stay-- to prevent this, we look for these gaps and backfill the first weight-- this adds (153255-149657)=3598 rows, meaning this fix helps for up to 3598 stay_id, wt_fix as(select ie.stay_id-- we add a 2 hour "fuzziness" window, DATETIME_SUB(ie.intime, INTERVAL '2' HOUR) as starttime, wt.starttime as endtime, wt.weight, wt.weight_typefrom mimic_icu.icustays ieinner join-- the below subquery returns one row for each unique stay_id-- the row contains: the first starttime and the corresponding weight(SELECT wt1.stay_id, wt1.starttime, wt1.weight, weight_type, ROW_NUMBER() OVER (PARTITION BY wt1.stay_id ORDER BY wt1.starttime) as rnFROM wt1) wtON ie.stay_id = wt.stay_idAND wt.rn = 1and ie.intime < wt.starttime)-- add the backfill rows to the main weight tableSELECTwt1.stay_id, wt1.starttime, wt1.endtime, wt1.weight, wt1.weight_typeFROM wt1UNION ALLSELECTwt_fix.stay_id, wt_fix.starttime, wt_fix.endtime, wt_fix.weight, wt_fix.weight_typeFROM wt_fix;
3.GCS评分, 神经系统功能评分。
with base as(selectsubject_id, ce.stay_id, ce.charttime-- pivot each value into its own column, max(case when ce.ITEMID = 223901 then ce.valuenum else null end) as GCSMotor, max(casewhen ce.ITEMID = 223900 and ce.VALUE = 'No Response-ETT' then 0when ce.ITEMID = 223900 then ce.valuenumelse nullend) as GCSVerbal, max(case when ce.ITEMID = 220739 then ce.valuenum else null end) as GCSEyes-- convert the data into a number, reserving a value of 0 for ET/Trach, max(case-- endotrach/vent is assigned a value of 0-- flag it here to later parse speciallywhen ce.ITEMID = 223900 and ce.VALUE = 'No Response-ETT' then 1 -- metavisionelse 0 end)as endotrachflag, ROW_NUMBER ()OVER (PARTITION BY ce.stay_id ORDER BY ce.charttime ASC) as rnfrom mimic_icu.chartevents ce-- Isolate the desired GCS variableswhere ce.ITEMID in(-- GCS components, Metavision223900, 223901, 220739)group by ce.subject_id, ce.stay_id, ce.charttime), gcs as (select b.*, b2.GCSVerbal as GCSVerbalPrev, b2.GCSMotor as GCSMotorPrev, b2.GCSEyes as GCSEyesPrev-- Calculate GCS, factoring in special case when they are intubated and prev vals-- note that the coalesce are used to implement the following if:-- if current value exists, use it-- if previous value exists, use it-- otherwise, default to normal, case-- replace GCS during sedation with 15when b.GCSVerbal = 0then 15when b.GCSVerbal is null and b2.GCSVerbal = 0then 15-- if previously they were intub, but they aren't now, do not use previous GCS valueswhen b2.GCSVerbal = 0thencoalesce(b.GCSMotor,6)+ coalesce(b.GCSVerbal,5)+ coalesce(b.GCSEyes,4)-- otherwise, add up score normally, imputing previous value if none available at current timeelsecoalesce(b.GCSMotor,coalesce(b2.GCSMotor,6))+ coalesce(b.GCSVerbal,coalesce(b2.GCSVerbal,5))+ coalesce(b.GCSEyes,coalesce(b2.GCSEyes,4))end as GCSfrom base b-- join to itself within 6 hours to get previous valueleft join base b2on b.stay_id = b2.stay_idand b.rn = b2.rn+1and b2.charttime > DATETIME_ADD(b.charttime, INTERVAL '6' HOUR))-- combine components with previous within 6 hours-- filter down to cohort which is not excluded-- truncate charttime to the hour, gcs_stg as(selectsubject_id, gs.stay_id, gs.charttime, GCS, coalesce(GCSMotor,GCSMotorPrev) as GCSMotor, coalesce(GCSVerbal,GCSVerbalPrev) as GCSVerbal, coalesce(GCSEyes,GCSEyesPrev) as GCSEyes, case when coalesce(GCSMotor,GCSMotorPrev) is null then 0 else 1 end+ case when coalesce(GCSVerbal,GCSVerbalPrev) is null then 0 else 1 end+ case when coalesce(GCSEyes,GCSEyesPrev) is null then 0 else 1 endas components_measured, EndoTrachFlagfrom gcs gs)-- priority is:-- (i) complete data, (ii) non-sedated GCS, (iii) lowest GCS, (iv) charttime, gcs_priority as(selectsubject_id, stay_id, charttime, gcs, gcsmotor, gcsverbal, gcseyes, EndoTrachFlag, ROW_NUMBER() over(PARTITION BY stay_id, charttimeORDER BY components_measured DESC, endotrachflag, gcs, charttime DESC) as rnfrom gcs_stg)selectgs.subject_id, gs.stay_id, gs.charttime, GCS AS gcs, GCSMotor AS gcs_motor, GCSVerbal AS gcs_verbal, GCSEyes AS gcs_eyes, EndoTrachFlag AS gcs_unablefrom gcs_priority gswhere rn = 1;
只是简单列举了几个常用表格,具体的表格说明可以查询github上官方源代码中的concept文件夹内的代码和注释。
之前未下载的同学也可以后台回复 【mimiccode】领取
三、衍生表格配置
1.参考前面数据安装步骤,打开命令界面,进入mimiciv数据库,配置数据库函数
这里具体看这篇文章 MIMIC数据库官方函数的安装与使用
set search_path to mimic_derived;
2.运行shell脚本生成衍生表格数据文件夹postgres(windows运行shell脚本可通过安装git运行,可自行百度安装)。
3.衍生表格数据。
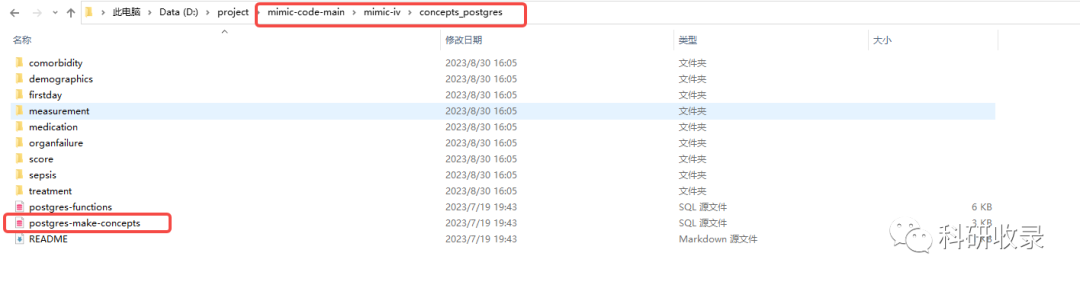
4.修改postgres-make-concepts.sql文件。
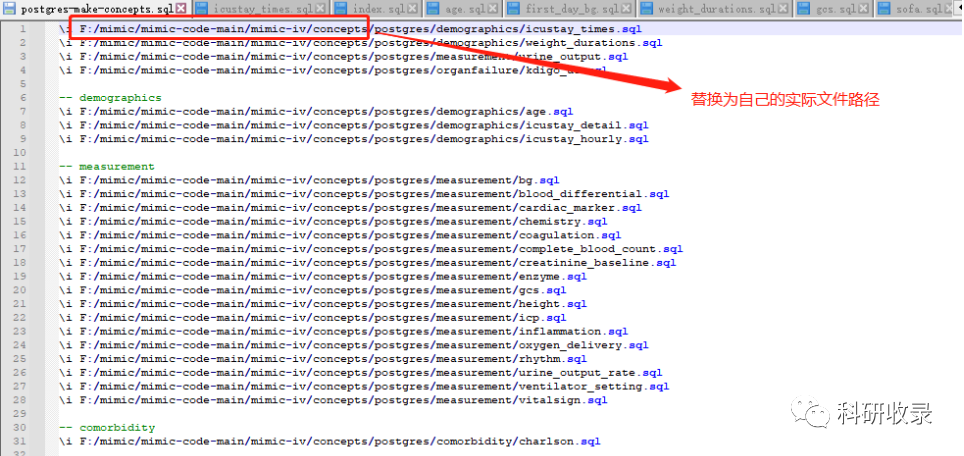
5.运行postgres-make-concepts.sql文件(注意替换为自己的文件路径)
运行时间有点长,耐心等待。
set search_path to mimic_derived;\encoding 'UTF-8';\i F:/mimic/mimic-code-main/mimic-iv/concepts/postgres/postgres-make-concepts.sql;
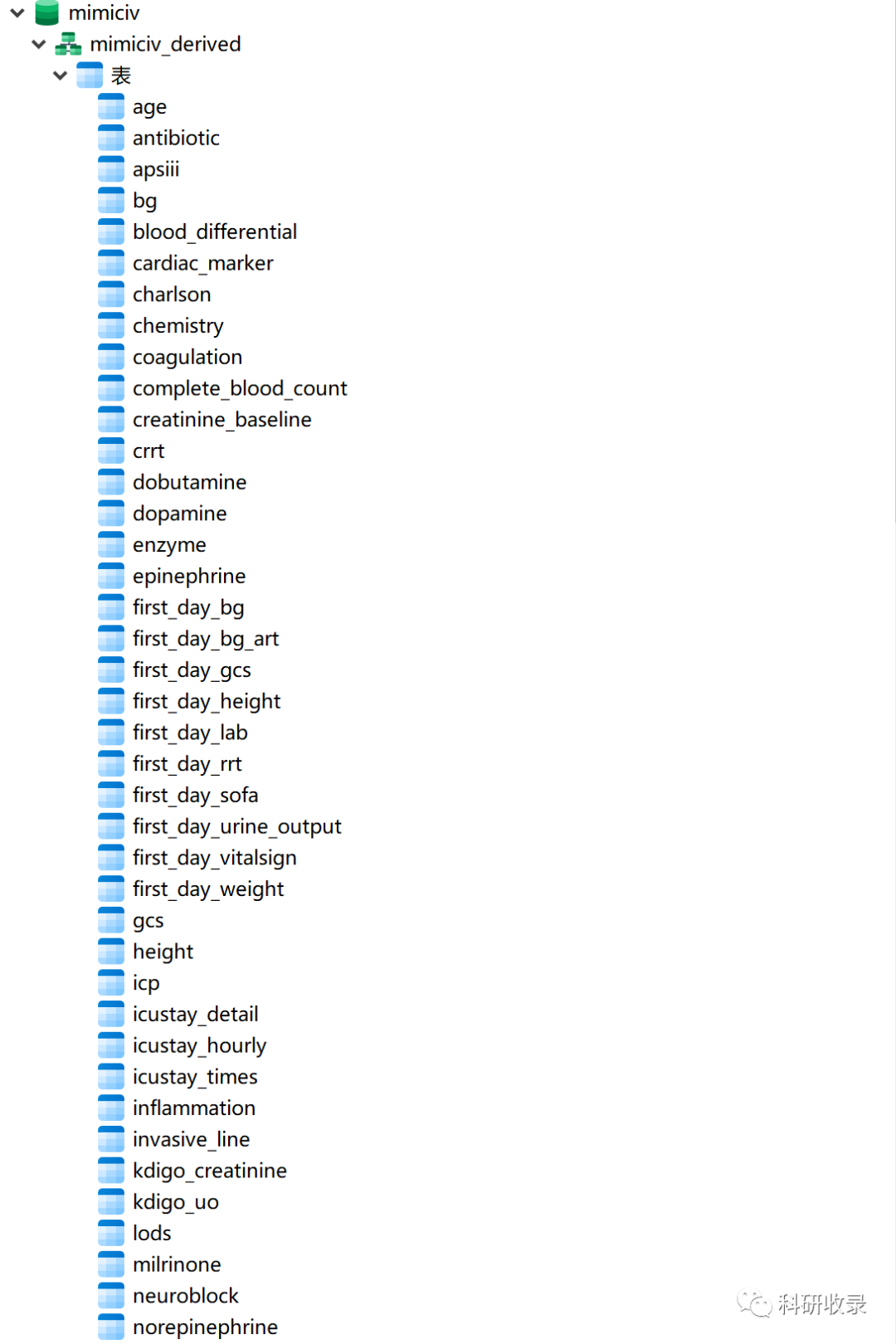
6.表格生成成功,一共58个表格。

四、实例使用演示
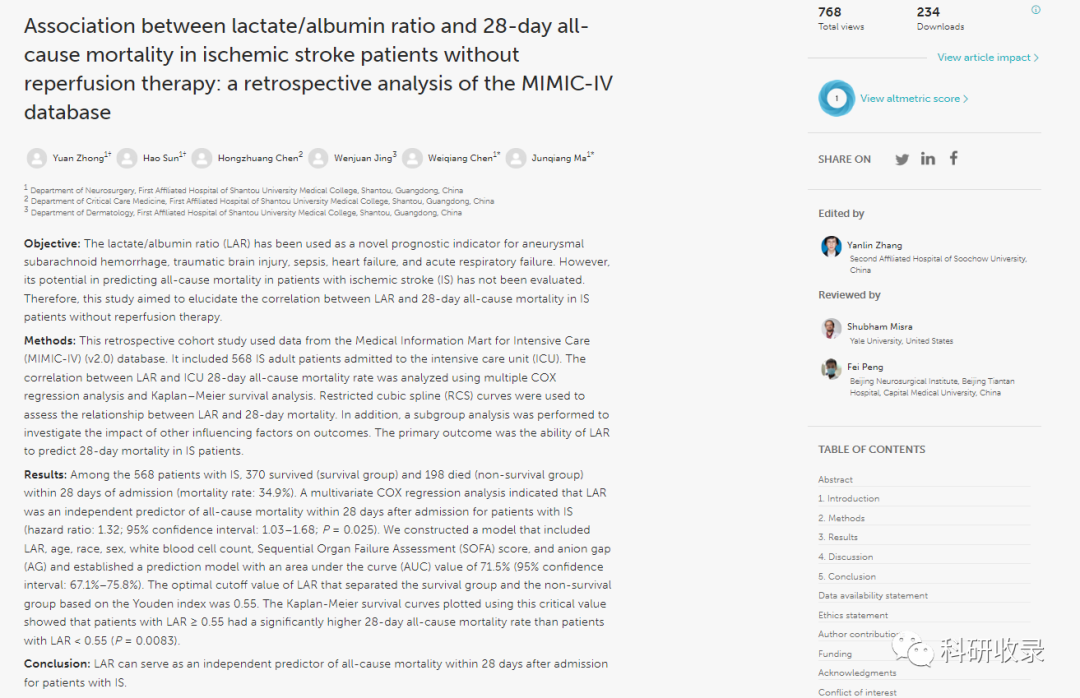
我们分析的是一篇利用MIMIC数据库发表的SCI论文,这是一篇2022年12月份发表在《Inflammation》期刊上的论文。
论文名为《Association between lactate-to-albumin ratio and 28-days all-cause mortality in patients with acute pancreatitis: A retrospective analysis of the MIMIC-IV database.》
中文名为《急性胰腺炎患者乳酸白蛋白比值与28天内全因死亡率的关系:对MIMIC-IV数据库的回顾性分析》
关注公众号“科研收录”,后台回复“急性胰腺炎患者死亡率”,即可获得该SCI论文
该论文在使用MIMIC数据库时候,筛选患者的标准如下:

所以我们这里讲围绕【如何提取年龄大于18岁的患者的首次入院记录】来教大家提取数据
4.1 年龄过滤:首次入院时年龄小于18岁的患者
mimiciv数据库中并没有直接记录患者的真实年龄,mimiciv_hosp.patients表中有一个关于关于年龄的字段anchor_age,注意这并不是患者的真实年龄,是是经过mimic偏移的年龄。
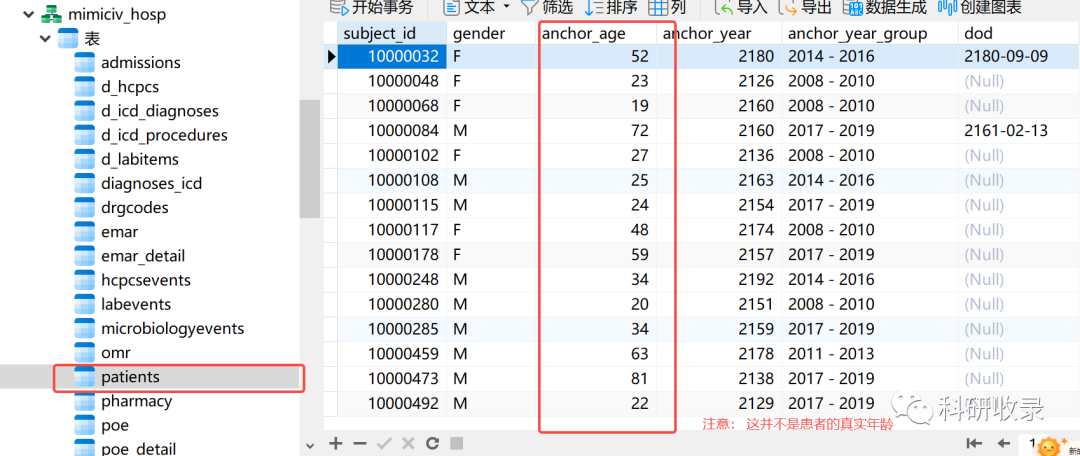
4.1.1 计算患者的真实年龄
患者的真实年龄 = anchor_age + admittime - anchor_year
-
anchor_age,anchor_year可以在mimiciv_hosp.patients表中找到
-
患者的入院年龄可以在mimiciv_hosp.admissions表中找到。
以下为患者的真实年龄的计算SQL:
pa.anchor_age + mimiciv_derived.DATETIME_DIFF(ad.admittime,mimiciv_derived.DATETIME(pa.anchor_year, 1, 1, 0, 0, 0)
注意:如果你将官方函数DATETIME_DIFF与DATETIME安装在了public模块中(小编这里安装在的mimiciv_derived),请修改成如下
pa.anchor_age + public.DATETIME_DIFF(ad.admittime,public.DATETIME(pa.anchor_year, 1, 1, 0, 0, 0)
这个算法算出来的年龄是小数,我们可以使用ROUND函数转成整数,完整SQL如下:
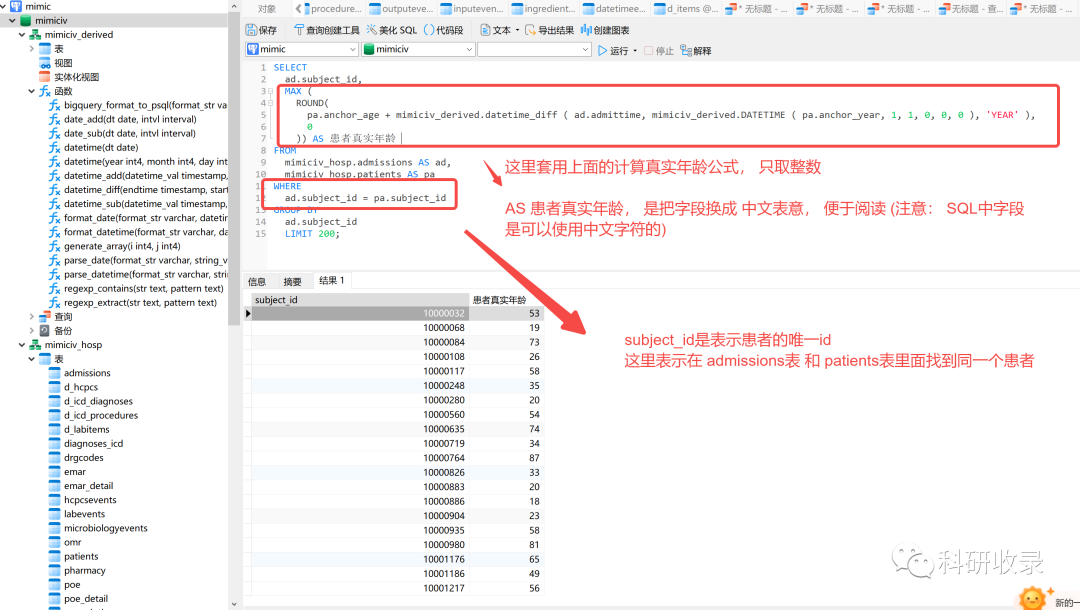
SELECTad.subject_id,MAX (ROUND(pa.anchor_age + mimiciv_derived.datetime_diff ( ad.admittime, mimiciv_derived.DATETIME ( pa.anchor_year, 1, 1, 0, 0, 0 ), 'YEAR' ),0)) AS 患者真实年龄FROMmimiciv_hosp.admissions AS ad,mimiciv_hosp.patients AS paWHEREad.subject_id = pa.subject_idGROUP BYad.subject_idLIMIT 200;
4.1.2 排除小于18岁的患者
我们可以先使用子查询先查询出来患者的真实年龄,再排除掉小于18岁的患者
关于子查询语句我们将在下一篇文章 《MIMIC数据库,常用查询指令SQL基础(二)》中详细讲解,这里大家可以先照着用就行
with base as (SELECTad.subject_id,MAX(ROUND(pa.anchor_age + mimiciv_derived.DATETIME_DIFF(ad.admittime,mimiciv_derived.DATETIME(pa.anchor_year, 1, 1, 0, 0, 0), 'YEAR'),0)) AS ageFROM mimiciv_hosp.admissions ad, mimiciv_hosp.patients paWHERE ad.subject_id = pa.subject_idGROUP BYad.subject_id)SELECT * FROM base WHERE base.age >=18 limit 100;
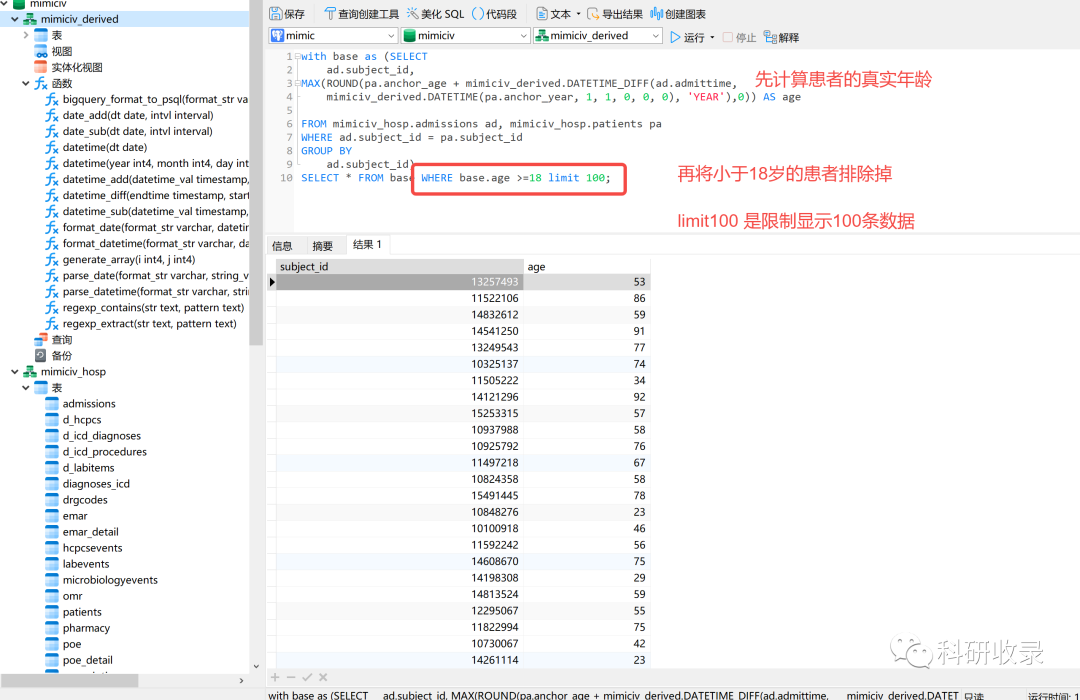
以上我们就筛选出大于等于18岁的患者,大家可以根据代码修改筛选出来其他年龄段的患者。
4.2 首次入院记录:因急性胰腺反复入院的患者,仅保留首次入院数据
mimiciv数据库记录了29万个病人的43万条入院记录,但是我们在做数据分析和提取的时候,通常只需要提取某个病人的首次入院记录。
4.2.1 入院时间排序
要获取患者的首次入院记录,我们需要使用到postgres数据库的内置函数ROW_NUMBER函数,该函数会将患者进行分组,并可以按照入院时间排序。
关于SQL语句ORDER BY 使用, 看这里
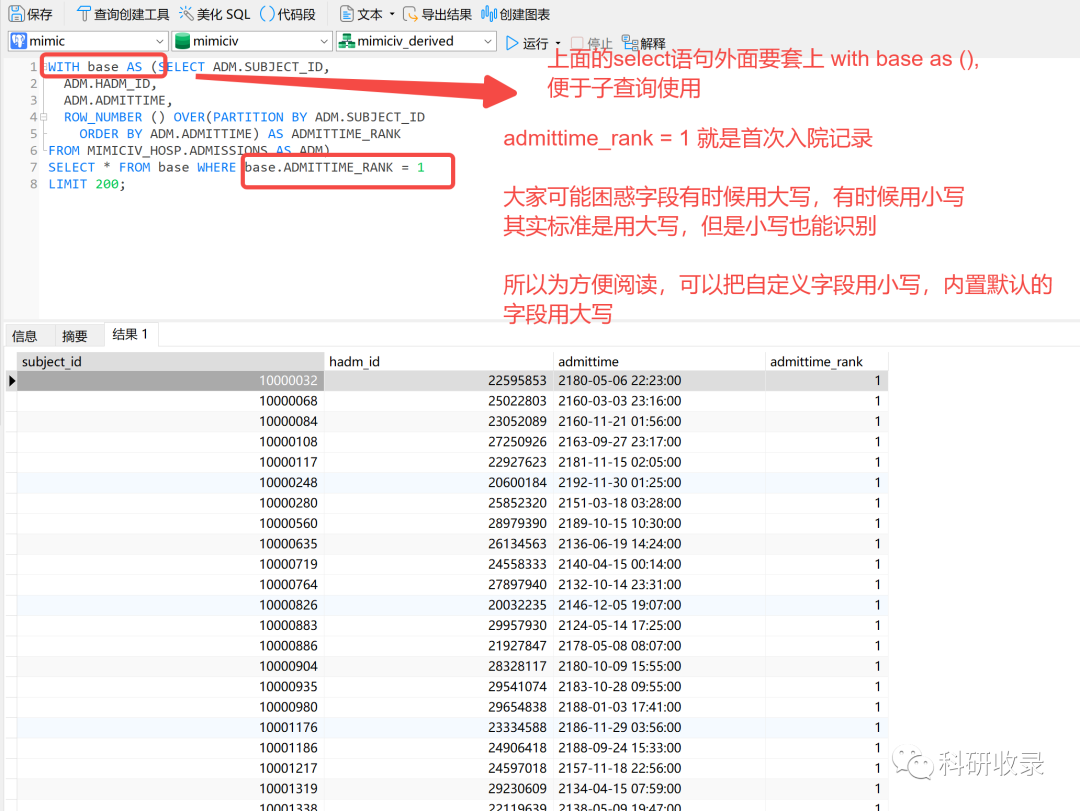
SELECT ADM.SUBJECT_ID,ADM.HADM_ID,ADM.ADMITTIME,ROW_NUMBER () OVER(PARTITION BY ADM.SUBJECT_IDORDER BY ADM.ADMITTIME) AS ADMITTIME_RANKFROM MIMICIV_HOSP.ADMISSIONS AS ADMLIMIT 100;
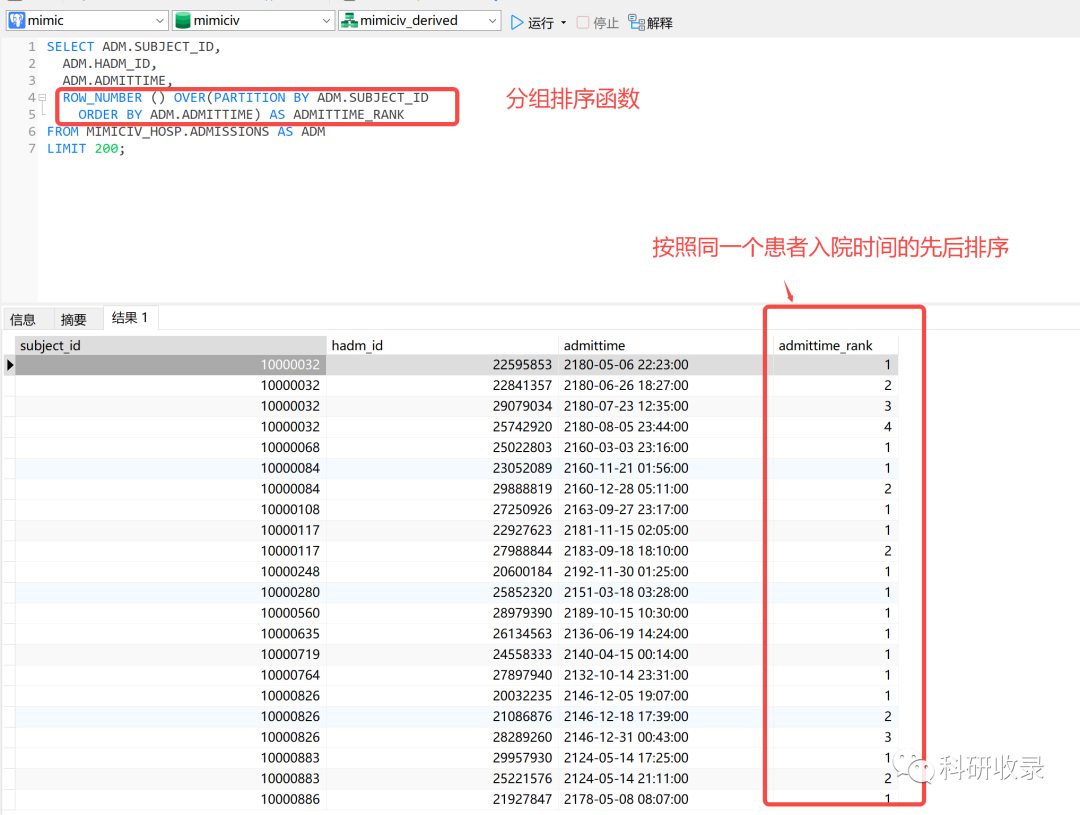
4.2.2 获取首次入院记录
利用postgres数据库的子查询,过滤出患者的首次入院记录
WITH base AS (SELECT ADM.SUBJECT_ID,ADM.HADM_ID,ADM.ADMITTIME,ROW_NUMBER () OVER(PARTITION BY ADM.SUBJECT_IDORDER BY ADM.ADMITTIME) AS ADMITTIME_RANKFROM MIMICIV_HOSP.ADMISSIONS AS ADM)SELECT * FROM base WHERE base.ADMITTIME_RANK = 1LIMIT 200;
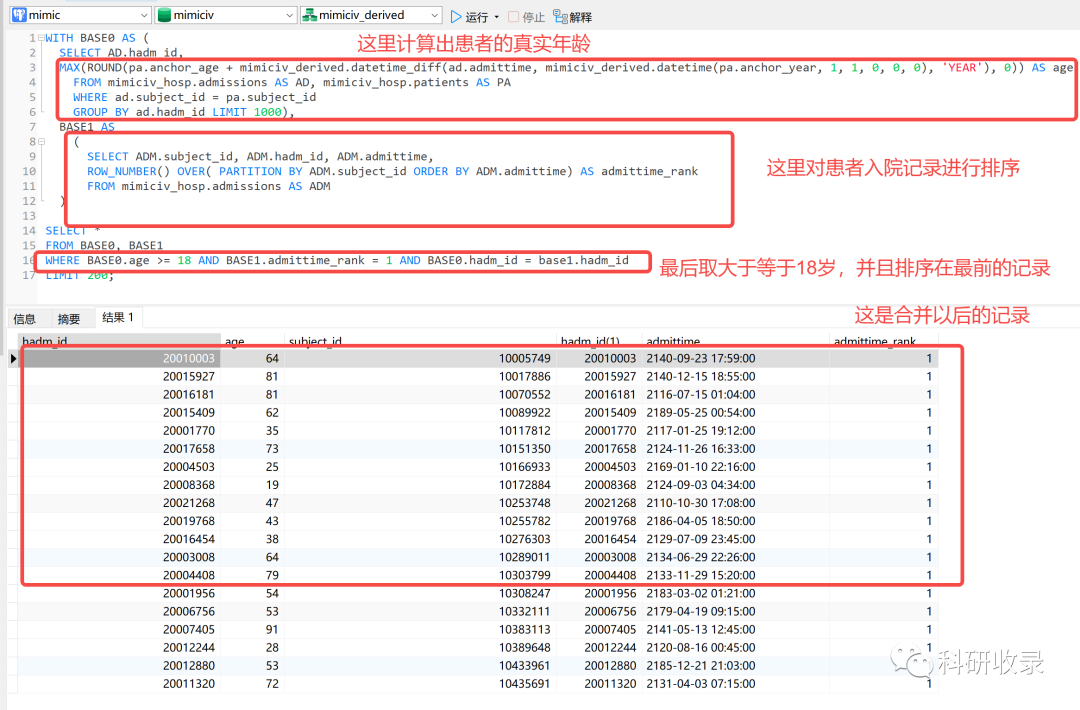
4.3 合并数据
根据年龄过滤出符合条件的患者,以及查出了患者的首次入院记录之后,我们需要把这两部分数据进行合并,也就是取出符合年龄条件的首次入院记录。
我们可以使用postgres数据库的子查询把这两部分数据合并在一起。
WITH BASE0 AS (SELECT AD.hadm_id,MAX(ROUND(pa.anchor_age + mimiciv_derived.datetime_diff(ad.admittime, mimiciv_derived.datetime(pa.anchor_year, 1, 1, 0, 0, 0), 'YEAR'), 0)) AS ageFROM mimiciv_hosp.admissions AS AD, mimiciv_hosp.patients AS PAWHERE ad.subject_id = pa.subject_idGROUP BY ad.hadm_id LIMIT 1000),BASE1 AS(SELECT ADM.subject_id, ADM.hadm_id, ADM.admittime,ROW_NUMBER() OVER( PARTITION BY ADM.subject_id ORDER BY ADM.admittime) AS admittime_rankFROM mimiciv_hosp.admissions AS ADM)SELECT *FROM BASE0, BASE1WHERE BASE0.age >= 18 AND BASE1.admittime_rank = 1 AND BASE0.hadm_id = base1.hadm_idLIMIT 200;
想获取mimiciv数据或者有问题的小伙伴可关注【科研收录】后台回复,谢谢!
阅读论文的同学会发现原文对提取的数据做了可视化图表展示和预测回归分析这部分我们会在往后的R语言和Python数据分析教程中涉及,敬请期待。


















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









