







Ranking Loss简介
ranking loss实际上是一种metric learning,他们学习的相对距离,而不在乎实际的值. 其应用十分广泛,包括是二分类,例如人脸识别,是一个人不是一个人。
在不同场景有不同的名字,包括 Contrastive Loss, Margin Loss, Hinge Loss or Triplet Loss. 但是他们的公式实际上非常一致的。大概有两类,一类是输入pair 对,另外一种是输入3塔结构。
Pairwise Ranking Loss
对于正样本。希望越接近越小。即LOSS = 距离
对于负样本,希望他们拉开m的差距。所以距离大于m的不考虑。
二分类Loss:
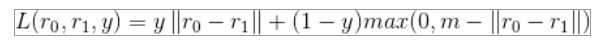
Triplet Ranking Loss
来自论文:
FaceNet: A Unified Embedding for Face Recognition and Clustering
论文阅读笔记
easy triplets(简单三元组): triplet对应的损失为0的三元组,形式化定义为d(a,n)>d(a,p)+margin,也就是负样本的距离远大于正样本的距离。
hard triplets(困难三元组): negative example 与anchor距离小于anchor与positive example的距离,形式化定义为d(a,n)<d(a,p),也就是负样本的距离远小于正样本的距离,意味着是易混淆的case。
semi-hard triplets(一般三元组): negative example 与anchor距离大于anchor与positive example的距离,但还不至于使得loss为0,即d(a,p)<d(a,n)<d(a,p)+margin,依旧是介于能区分与容易区分之间,有差距但是差距不够大。
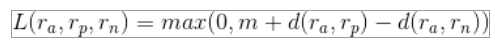
如何构造负样本
triple loss:
离线对比挖掘:
- 得到每一个样本的embedding.
- 计算 (与负样本d(a,n))和 (与正阳本d(a,p))与margin之间的距离差距。
- 判断属于easy triplets, hard triplets, semi-hard triplets,
- 选择其中hard or semi-hard triplets,因为easy太容易了,没有必要训练
在线对比挖掘
- batch all: 同批次计算所有的valid triplet,对hard 和 semi-hard triplets上的loss进行平均。
- 不考虑easy triplets,因为easy triplets的损失为0,平均会把整体损失缩小
- 将会产生PK(K-1)(PK-K)个triplet,即PK个anchor,对于每个anchor有k-1个可能的positive example,PK-K个可能的negative examples
- batch hard: 对于每一个anchor,选择hardest positive example(距离anchor最大的positive example)和hardest negative(距离anchor最小的negative example),
- 由此产生PK个triplet
- 这些triplet是最难分的
- 计算所有的embedding 两两距离得到distances:(batch, batch)
- 计算所有三元组的情况:(batch, batch, batch)
得到一个3D的mask [a, p, n], 对应triplet(a, p, n)是valid的位置是True
得到当下标(i, j, k)不相等, 且label[i]==label[j], label[i] != label[k]- 计算所有的triple loss * mask , 再求平均
- 取 K 距离最大的 pos , K 距离最小的neg
- pos_mask, neg_mask大小(batch, batch)
- batch hard loss =
max(pos_mask* distances - neg_mask* distances + margin, 0)
一些别名
在不同场景有不同的名字
- Ranking loss: 这个名字主要是在搜索场景用,希望模型能能够以一定顺序rank item。
- Margin Loss: 这个则是希望用margin去代表距离 。
- Contrastive Loss:【pairloss】
N个样本。
y=1相似或者同标签,
d代表两个的欧式距离,
margin为给定的阈值
- Triplet Loss: 通常是3塔结构
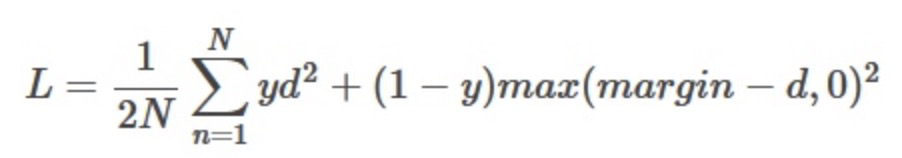
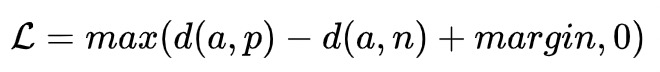
- Hinge loss: 也是max-margin objective. 也是SVM 分类的损失函数。max{0,margin-(S(Q,D+)-S(Q,D-))}
- WRGP loss 这个主要原理是认为随机抽样1000个
Git 代码
triple loss tensorflow
triplet loss pytorch
triplelet loss numpy
center loss pytorch
center loss
triplet学习的是样本间的相对距离,没有学习绝对距离,尽管考虑了类间的离散性,但没有考虑类内的紧凑性。
Center Loss希望可以通过学习每个类的类中心,使得类内的距离变得更加紧凑。Cyi表示深度特征的第yi类中心。
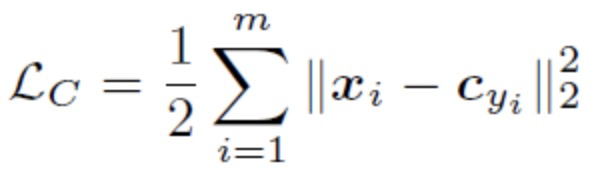
训练时:
第一是基于mini-batch执行更新。在每次迭代中,计算中心的方法是平均相应类的特征(一些中心可能不会更新)。
第二,避免大扰动引起的误标记样本,用一个标量 α 控制中心的学习速率,一般这个α 很小(如,0.005)。
计算梯度并更新
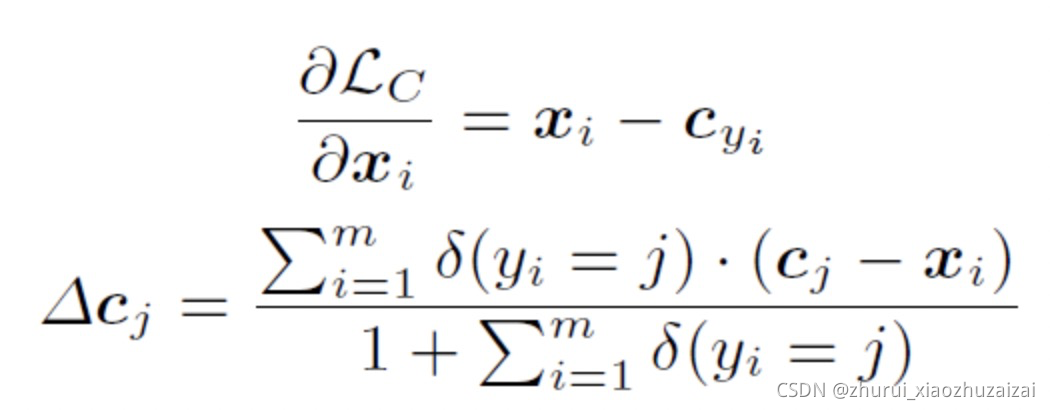
实际场景,可以利用triplet loss和center loss联合训练优化模型

















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









