







【参考链接】
- 一张图总结大语言模型的技术分类、现状和开源情况
- 大语言模型LLM微调技术:Prompt Tuning
- A Survey of Large Language Models
- The Practical Guides for Large Language Models
- GPT3:Language Models are Few-Shot Learners
随着GPU技术和经济的发展,深度学习的范式也不断被刷新。
- 基础阶段是需要研发人员准备大量的语料库设计网络架构进行参数优化的全网络训练(如基础Transformer),或者是冻结部分网络参数的迁移学习等方式;
- 第一个进阶阶段是参数量相较于之前量级增大的预训练模型(如Bert、GPT1、XLNet等),已经通过海量数据优化后的模型,只需要研发人员准备较少量的数据,进行微调即可实现在特定任务上的理想效果,形成了预训练+Fine-Tuning的范式;
- 第二个进阶阶段就是具有跨时代意义的模型(如BART、T5、GPT3),模型参数量更大、预训练的预料更丰富且是基于特定模版进行设计的生成式语料库(如:将分类任务转换成问答文本)、预训练任务涉及场景更广泛,研发人员可以基于特定的提示词文本(越接近训练语料的提问方式效果更好)作为大模型输入就能够得到基础满足任务目标的结果,通过对结果的解析来实现不同的任务,形成了预训练+Prompt-Tuning的范式,让模型的使用门槛更低,大大提升了各行各业的生产力。
第三个进阶阶段走向AIGC(Artificial Intelligent Generated Content)时代,模型参数规模步入千万亿(如GPT-4),模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型。

概述
主要语言模型基础架构有三种:Encoder-Only(自编码Auto encoding,如Bert等)、Decoder-Only(自回归Auto aggressive,如GPT等)和Encoder-Decoder(seq2seq,如:GLM等):

2019年以来大语言模型百花齐放,但是架构上还是保持了三种基础结构,随着GPT3的流行,Decoder-Only的架构成为了大多数大语言模型(Large Language Model,LLM)的底座架构。

2019 年以来出现的各种大语言模型(百亿参数以上)时间轴如下图所示,其中标黄的大模型已开源:

- LLM汇总,其中IT表示Instruct-Tuning,RLHF表示强化学习微调,ICL表示in-context learning,COT表示Chain of Thought。

优化大模型的应用效果有两条路线,一条是仅根据prompt去探索激发模型潜力的文本提示词(如COT、RAG等),另一条是基于预训练的语言模型底座进行微调(如RLHF等)得到针对特定场景的优化版微调模型。
GPT3
OpenAI的GPT发展路线如下图所示,GPT一直都是Decoder-Only的自回归生成式模型:

GPT3和GPT2、GPT1的网络结构的区别在于堆叠的Decoder层数更多,其参数量为1750亿。

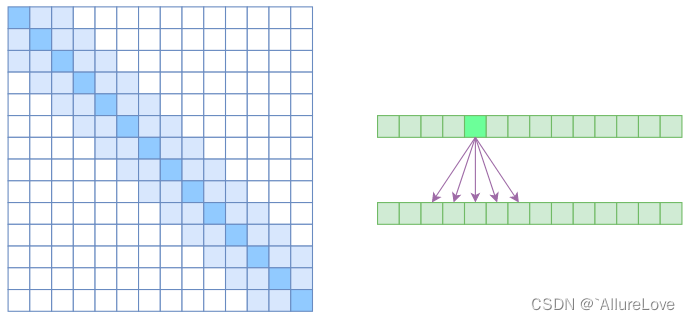
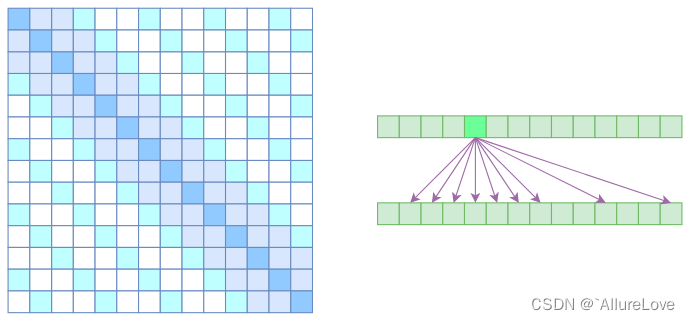
GPT3还提出了一种有化注意力计算的方法,采用了交替的密集和局部带状稀疏注意力来提升计算效率,具体为:
- Atrous Self Attention:启发于“Atrous Convolution”,其对相关性进行了约束,强行要求每个元素只跟它相对距离为k,2k,3k,…的元素关联,其中k>1,k是预先设定的超参数。从下左的注意力矩阵看,就是强行要求相对距离不是k的倍数的注意力为0;
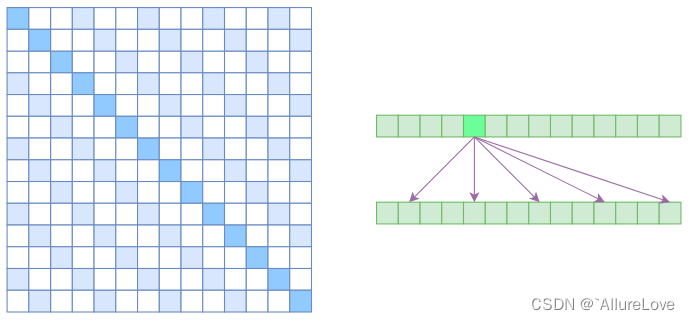
- Local Self Attention:放弃了全局关联,重新引入局部关联,做法就是约束每个元素只与前后k个元素以及自身有关联;
- Sparse Attention:最后将两部分注意力相加形成稀疏注意力机制;
现有的LLM大模型基础底座架构是上面提到的三种类型(Encoder-Only、Encoder-Decoder、Decoder-Only),框架结构不变,具体实现细节的差异体现在:1)框架细节的构造(细节结构优化、模型层次参数量等);2)数据集的设计(数据选取、数据筛选、数据量级等);3)是否特定领域微调(微调网络架构设计等);
LLM的应用可粗略划分成两种路线:1)Prompt路线,单从Prompt角度去提升模型预测的效果;2)微调路线,考虑用少量样本去提升模型在特定场景的性能;














 2484
2484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









