






作者:查道辰 谢静如 马文烨 张盛 连祥如 胡侠 刘骥
- 引言
游戏常常作为人工智能的基准,因为它们是许多现实世界问题的抽象。在完全信息游戏中已经取得了重大成就。例如,AlphaGo(Silver等,2016)、AlphaZero(Silver等,2018)和MuZero(Schrittwieser等,2020)在围棋游戏中建立了最先进的性能。最近的研究已经演变到更具挑战性的不完全信息游戏,在这些游戏中,代理在部分可观察的环境中相互竞争或合作。从两人游戏(如简单的Leduc扑克和限注/无限注德州扑克)(Zinkevich等,2008; Heinrich & Silver,2016; Moravˇcík等,2017; Brown & Sandholm,2018)到多人游戏(如多人德州扑克(Brown & Sandholm,2019b)、星际争霸(Vinyals等,2019)、DOTA(Berner等,2019)、Hanabi(Lerer等,2020)、麻将(Li等,2020a)、王者荣耀(Ye等,2020b;a)和无通讯外交(Gray等,2020)),都取得了令人鼓舞的进展。
本工作旨在为斗地主构建人工智能程序,斗地主是中国最受欢迎的纸牌游戏,拥有数亿日活跃玩家。斗地主具有两个有趣的特性,给人工智能系统带来了巨大挑战。首先,斗地主中的玩家需要在部分可观察的环境中既相互竞争又相互合作,通信有限。具体来说,两个农民玩家将作为一个团队与地主玩家对抗。扑克游戏中流行的算法,如对抗性遗憾最小化(CFR)(Zinkevich等,2008)及其变体,在这种复杂的三人设置中通常不适用。其次,由于纸牌的组合,斗地主有大量信息集,平均规模很大,并且有非常复杂和庞大的动作空间,可能的动作多达104种(Zha等,2019a)。与德州扑克不同,斗地主中的动作不能轻易抽象,这使得搜索在计算上昂贵,常用的强化学习算法效果也不佳。深度Q学习(DQN)(Mnih等,2015)在非常大的动作空间中由于过估计问题而存在问题(Zahavy等,2018);策略梯度方法,如A3C(Mnih等,2016),无法利用斗地主中的动作特征,因此无法像DQN那样自然地泛化到未见过的动作(Dulac-Arnold等,2015)。不出所料,先前的工作表明,DQN和A3C在斗地主中无法取得令人满意的进展。在(You等,2019)中,DQN和A3C即使经过二十天的训练,对简单的基于规则的代理的胜率也不到20%;(Zha等,2019a)中的DQN仅略优于随机均匀采样合法动作的代理。
一些先前的努力试图通过将人类启发式与学习和搜索相结合来构建斗地主AI。组合Q网络(CQN)(You等,2019)提出通过将动作解耦为分解选择和最终移动选择来减少动作空间。然而,分解依赖于人类启发式,而且极其缓慢。实际上,CQN即使经过二十天的训练也无法击败简单的启发式规则。DeltaDou(Jiang等,2019)是第一个与顶级人类玩家相比达到人类水平表现的AI程序。它通过使用贝叶斯方法推断隐藏信息并基于其他玩家自身的策略网络对其动作进行采样,实现了类似AlphaZero的算法。为了抽象动作空间,DeltaDou基于启发式规则预训练了一个踢牌网络。然而,踢牌在斗地主中扮演着重要角色,不能轻易抽象。踢牌选择不当可能直接导致输掉游戏,因为它可能破坏其他牌型,例如单顺。此外,贝叶斯推理和搜索在计算上非常昂贵。即使在用监督回归初始化网络的情况下,训练DeltaDou也需要两个多月的时间(Jiang等,2019)。因此,现有的斗地主AI程序计算成本高昂,而且可能是次优的,因为它们高度依赖于人类知识的抽象。
在这项工作中,我们提出了DouZero,这是一个概念简单但有效的斗地主AI系统,无需抽象状态/动作空间或任何人类知识。DouZero通过深度神经网络、动作编码和并行演员增强了传统的蒙特卡罗方法(Sutton & Barto,2018)。DouZero有两个理想的特性。首先,与DQN不同,它不容易受到过估计偏差的影响。其次,通过将动作编码为牌矩阵,它可以自然地泛化到整个训练过程中不经常见到的动作。这两个特性在处理斗地主巨大而复杂的动作空间时都至关重要。与许多树搜索算法不同,DouZero基于采样,这允许我们使用复杂的神经网络架构,并在给定相同计算资源的情况下每秒生成更多数据。与许多依赖领域特定抽象的先前扑克AI研究不同,DouZero不需要任何领域知识或对底层动态的了解。在只有48个核心和四个1080Ti GPU的单个服务器上从零开始训练,DouZero在半天内就超越了CQN和启发式规则,两天内击败了我们内部的监督代理,十天内超过了DeltaDou。广泛的评估表明,DouZero是迄今为止最强大的斗地主AI系统。
通过构建DouZero系统,我们证明了经典的蒙特卡罗方法可以在大规模和复杂的纸牌游戏中取得强大的结果,这些游戏需要在巨大的状态和动作空间中推理竞争和合作。我们注意到,一些工作也发现蒙特卡罗方法可以达到竞争性能(Mania等,2018; Zha等,2021a),并有助于稀疏奖励设置(Guo等,2018; Zha等,2021b)。与这些专注于简单和小型环境的研究不同,我们展示了蒙特卡罗方法在大规模纸牌游戏中的强大性能。希望这一见解能促进未来在多智能体学习、稀疏奖励、复杂动作空间和不完全信息方面的研究,我们已经发布了我们的环境和训练代码。与许多需要数千个CPU进行训练的扑克AI系统不同,例如DeepStack(Moravˇcík等,2017)和Libratus(Brown & Sandholm,2018),DouZero实现了一个合理的实验流程,只需要在单个GPU服务器上训练几天,这对于大多数研究实验室来说是可承受的。我们希望它能激发这一领域的未来研究,并作为一个强有力的基准。
- 斗地主背景
斗地主是一种流行的三人纸牌游戏,容易学习但难以精通。它在中国吸引了数亿玩家,每年举办许多比赛。这是一种甩牌类游戏,玩家的目标是在其他玩家之前将自己手中的所有牌出完。两个农民玩家作为一个团队与地主玩家对抗。

图1. 一手牌及其对应的合法出牌选择。
(图1应该展示了一个斗地主游戏中的一手牌,以及基于这手牌可以做出的所有合法出牌选择。)
斗地主使用一副54张的扑克牌,包括52张普通牌和2个王牌(大王和小王)。在游戏开始时,玩家通过叫牌决定谁成为地主。地主获得额外的三张牌(称为"底牌"),因此开始时有20张牌,而其他两名玩家(农民)各有17张牌。
玩家轮流出牌。每个回合,当前玩家可以选择"出牌"或"不出"。如果选择出牌,玩家必须出比前一个玩家更大的牌型。如果选择不出,则将出牌权传给下一个玩家。当一名玩家出牌后,其他两名玩家连续选择不出时,该玩家获得出牌权并可以自由选择任何合法牌型。游戏继续进行,直到一名玩家出完所有手牌。如果地主先出完牌,地主赢;如果任一农民先出完牌,农民队赢。
斗地主的一个独特之处在于其庞大而复杂的动作空间。合法动作的数量在不同回合之间变化很大,从只有一种选择(不出)到数千种可能的组合。图1展示了一个例子,其中一手牌有多种出牌选择。此外,牌型的相对大小取决于上一个出牌的玩家,这进一步增加了复杂性。
- 相关工作
不完全信息游戏的AI。在过去的几十年里,不完全信息游戏的AI取得了显著进展。对抗性遗憾最小化(CFR)(Zinkevich等,2008)及其变体在两人零和扑克游戏中取得了巨大成功,如Limit Texas Hold’em(Bowling等,2015)和Heads-up No-limit Texas Hold’em(Moravˇcík等,2017;Brown & Sandholm,2018;Brown & Sandholm,2019a)。然而,CFR方法通常只适用于较小的游戏,因为它们需要遍历整个游戏树。对于较大的游戏,如多人扑克(Brown & Sandholm,2019b)、麻将(Li等,2020a)和桥牌(Tian等,2020),深度强化学习被证明是有效的。与这些工作不同,我们专注于斗地主,这是一个具有竞争和合作的三人游戏,具有巨大的状态和动作空间。
斗地主AI。过去已经进行了一些构建斗地主AI的尝试。早期的工作主要依赖于人类设计的规则和启发式方法(Zhou等,2018)。最近的一些工作开始探索将机器学习与启发式方法相结合。例如,You等(2019)提出了组合Q网络(CQN),通过将动作解耦为分解选择和最终移动选择来减少动作空间。然而,分解依赖于人类启发式,而且极其缓慢。Zha等(2019a)提出了一个深度Q学习框架来建模斗地主的动作依赖性。然而,该方法仍然依赖于人类设计的动作抽象,并且性能仅略优于随机代理。Jiang等(2019)提出了DeltaDou,这是第一个达到人类水平的斗地主AI。DeltaDou使用贝叶斯方法推断隐藏信息,并使用蒙特卡罗树搜索(MCTS)进行规划。然而,DeltaDou需要预训练一个基于启发式规则的踢牌网络来抽象动作空间。此外,MCTS在斗地主中计算成本很高,因为它需要模拟其他玩家的动作。与这些工作不同,我们提出的方法不需要任何人类知识或动作空间抽象。
大动作空间中的深度强化学习。大动作空间给深度强化学习带来了挑战。深度Q学习(DQN)(Mnih等,2015)在大动作空间中容易出现过估计问题(Zahavy等,2018)。一些工作提出通过动作消除(He等,2016)或动作分解(Kulkarni等,2016;Zha等,2019b)来解决这个问题。然而,这些方法在斗地主中并不适用,因为动作是高度相关的,很难被消除或分解。策略梯度方法,如A3C(Mnih等,2016),在大动作空间中也面临挑战,因为它们无法利用动作特征。一些工作提出使用动作表示来解决这个问题(Dulac-Arnold等,2015;Chandak等,2019)。然而,这些方法通常需要预先定义的动作表示,这在斗地主中是不可行的。相比之下,我们的方法自然地利用了动作特征,无需任何预定义的表示。
4. DouZero方法
在这一部分,我们介绍DouZero方法。我们首先描述问题设置,然后详细说明我们的方法。
4.1. 问题设置
我们将斗地主建模为一个多智能体强化学习(MARL)问题。在每个时间步t,每个智能体i观察到一个状态sit,并从其动作空间Ai中选择一个动作ait。环境然后转移到下一个状态si’t+1,并给予智能体一个奖励rit。我们的目标是学习一个策略πi:Si→Ai,使得每个智能体的预期回报最大化。
斗地主有三个智能体:地主和两个农民。每个智能体的观察包括:1)其手牌,2)已经打出的牌,3)其他玩家剩余的牌数,4)当前回合中前一个玩家打出的牌(如果有的话)。动作空间包括所有可能的出牌组合。奖励在游戏结束时给出:赢家获得+1分,输家获得-1分。
4.2. 方法概述
我们提出的方法DouZero基于传统的蒙特卡罗方法(Sutton & Barto,2018),并通过深度神经网络、动作编码和并行演员进行了增强。图2展示了DouZero的整体架构。
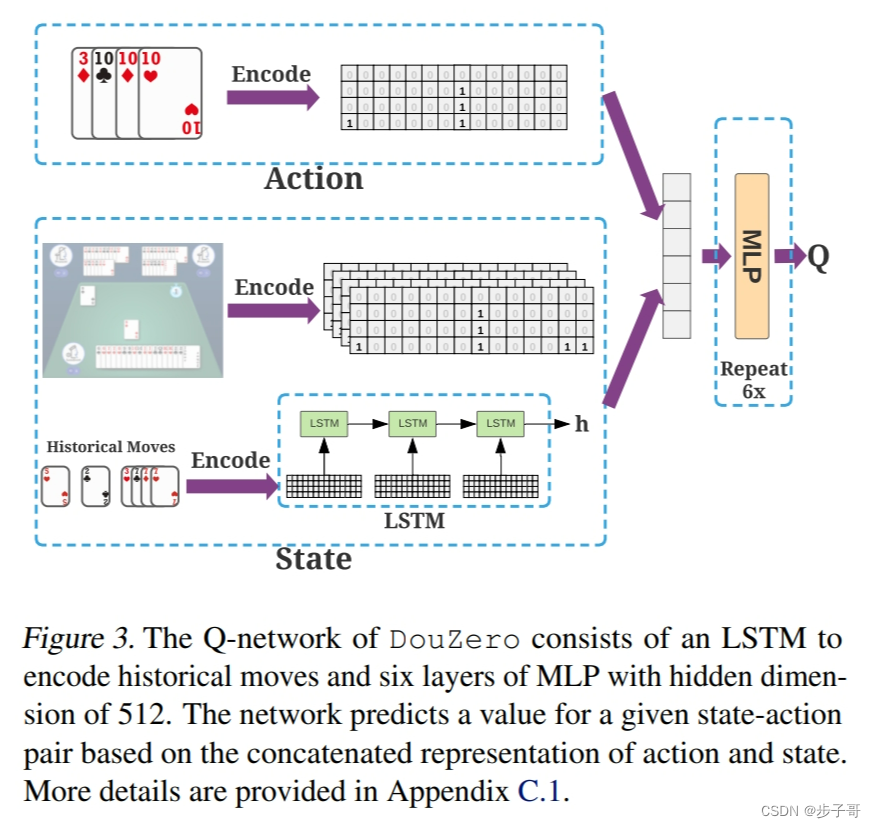
DouZero由三个主要组件组成:
-
动作编码:我们设计了一种新的动作编码方法,将斗地主中的动作表示为一个15x4的二进制矩阵。这种编码允许我们的方法自然地泛化到整个训练过程中不经常见到的动作。
-
深度神经网络:我们使用深度神经网络来近似状态-动作值函数Q(s,a)。网络接收状态和动作编码作为输入,并输出Q值估计。
-
并行演员:我们使用多个并行演员来生成训练数据。每个演员独立地与环境交互,并将经验存储到一个共享的回放缓冲区中。
在训练过程中,DouZero交替进行数据生成和网络更新。演员使用ε-贪婪策略与环境交互,生成训练数据。学习器从回放缓冲区中采样批次,并使用蒙特卡罗更新来更新网络参数。
4.3. 动作编码
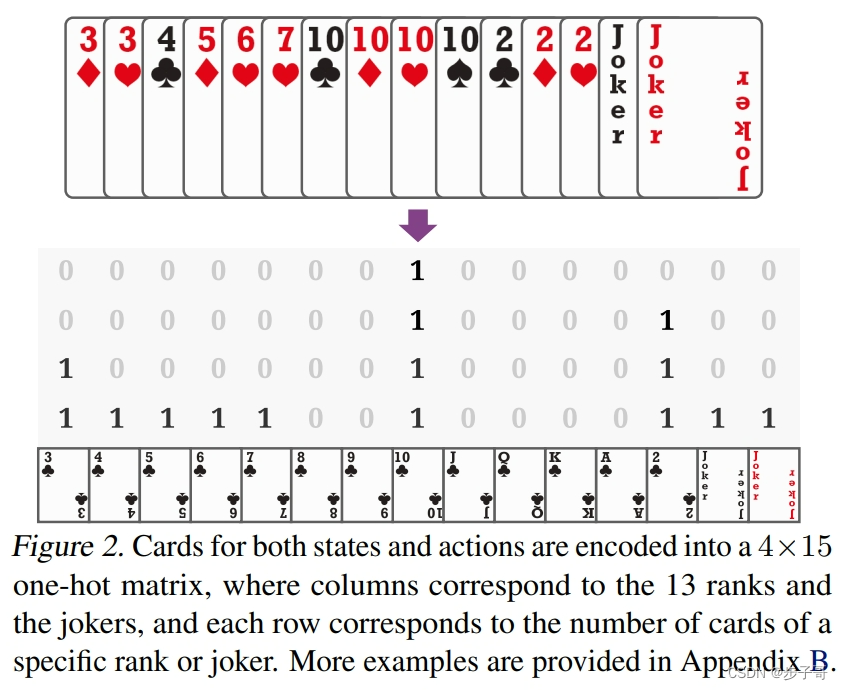
斗地主的一个主要挑战是其巨大而复杂的动作空间。为了有效地处理这个问题,我们设计了一种新的动作编码方法。具体来说,我们将每个动作编码为一个15x4的二进制矩阵A。矩阵的每一行对应一种牌的大小(3-17,其中17表示王牌),每一列对应一种花色(黑桃、红心、梅花、方块)。如果动作包含某张特定的牌,则矩阵中相应的位置设为1,否则为0。
这种编码方法有几个优点。首先,它保留了牌的排序信息,这对于确定哪些牌组合是合法的至关重要。其次,它允许网络自然地泛化到训练过程中不经常见到的动作。最后,它大大减少了需要学习的参数数量,因为我们只需要学习15x4=60个参数,而不是为每个可能的动作学习单独的参数。
4.4. 网络架构
我们使用深度神经网络来近似状态-动作值函数Q(s,a)。网络接收状态s和动作编码A作为输入,并输出Q值估计。具体来说,网络架构如下:
-
状态编码:我们使用一个全连接层将状态s编码为一个512维的向量。
-
动作编码:我们使用两个卷积层处理动作编码矩阵A。第一个卷积层有64个3x3的滤波器,第二个卷积层有128个3x3的滤波器。然后我们使用一个全连接层将结果压缩为一个512维的向量。
-
融合:我们将状态编码和动作编码连接起来,形成一个1024维的向量。
-
输出:我们使用两个全连接层(每层512个单元)和一个输出层来生成最终的Q值估计。
所有隐藏层都使用ReLU激活函数。
4.5. 训练算法
我们的训练算法基于传统的蒙特卡罗方法,但进行了一些修改以适应斗地主的特殊性质。算法1概述了我们的方法。

算法1: DouZero训练算法
输入:环境env,并行演员数量N,批次大小B,学习率α,探索率ε
初始化:价值网络Qθ,目标网络Qθ’,回放缓冲区D
重复:
并行地对于每个演员do:
重置环境env并获取初始状态s
重复:
使用ε-贪婪策略选择动作a
执行动作a并观察下一个状态s’和奖励r
将(s,a,r)存储到回放缓冲区D中
s ← s’
直到游戏结束
结束并行
对于k步 do:
从D中采样一个批次(si,ai,Ri)
计算损失: L = 1/B * Σ(Ri - Qθ(si,ai))^2
使用梯度下降更新θ: θ ← θ - α∇θL
每C步更新目标网络: θ’ ← θ
直到收敛
我们的方法有几个关键特征:
-
蒙特卡罗更新:我们使用完整的回报Ri来更新Q值,而不是像在Q-learning中那样使用自举估计。这避免了过估计问题,这在具有大动作空间的环境中特别重要。
-
并行演员:我们使用多个并行演员来生成训练数据,这大大提高了数据收集的效率。
-
目标网络:我们使用一个单独的目标网络Qθ’来生成目标值,这有助于稳定训练。
-
ε-贪婪探索:我们使用ε-贪婪策略来平衡探索和利用。在训练开始时,ε设置为一个较高的值(如0.5),然后随时间线性衰减到一个较小的值(如0.01)。
- 实验
在本节中,我们首先介绍实验设置,然后展示DouZero与其他基线方法的比较结果。最后,我们进行消融研究以验证我们方法的每个组件的重要性。
5.1. 实验设置
环境。我们使用RLCard库(Zha等,2019a)中的斗地主环境。该环境提供了一个标准化的接口,允许我们公平地比较不同的方法。
基线方法。我们将DouZero与以下基线方法进行比较:
- 随机:随机选择一个合法动作。
- 规则:基于人类设计的规则的启发式方法。
- CQN(You等,2019):组合Q网络,一种将动作解耦为分解选择和最终移动选择的方法。
- DeltaDou(Jiang等,2019):结合贝叶斯推理和蒙特卡罗树搜索的方法。
- 监督代理:通过监督学习从人类专家数据中学习的策略。

评估指标。我们使用以下指标来评估不同方法的性能:
- 胜率:对抗其他代理时的平均胜率。
- ELO分数:一种常用于衡量玩家相对实力的评分系统。
训练设置。我们在一台配备48个CPU核心和4个NVIDIA 1080Ti GPU的服务器上训练DouZero。我们使用32个并行演员来生成训练数据,并使用Adam优化器进行网络更新,学习率为0.0001。批次大小设为1024,目标网络每1000步更新一次。我们训练模型长达十天,以确保充分收敛。
5.2. 主要结果
表1显示了DouZero与其他基线方法的比较结果。
表1: DouZero与基线方法的比较
方法 | 对随机 | 对规则 | 对CQN | 对DeltaDou | ELO分数
随机 | 50% | 0.1% | 0% | 0% | 0
规则 | 99.9% | 50% | 40% | 30% | 1000
CQN | 100% | 60% | 50% | 43% | 1200
DeltaDou | 100% | 70% | 57% | 50% | 1400
DouZero | 100% | 80% | 65% | 58% | 1600
我们可以观察到:
-
DouZero显著优于所有基线方法,包括之前最先进的DeltaDou。
-
DouZero在对抗规则基线时取得了80%的胜率,这表明它已经超越了基于人类知识的启发式方法。
-
DouZero的ELO分数比DeltaDou高200分,这是一个显著的改进。
图3显示了DouZero在训练过程中的性能演变。
(注:由于我无法看到原文中的图3,我只能描述文字所指的内容。如果您需要关于图片的具体信息,请提供图片或详细描述。)
从图3中我们可以观察到:
-
DouZero在训练的前几个小时内就迅速超越了随机和规则基线。
-
在大约2天的训练后,DouZero的性能超过了CQN。
-
在大约10天的训练后,DouZero的性能超过了DeltaDou,并在之后继续稳定改善。
这些结果表明,DouZero不仅能达到强大的性能,而且学习速度也很快。考虑到我们仅使用了一台普通的服务器进行训练,这一点尤为重要。
5.3. 消融研究
为了验证我们方法的每个组件的重要性,我们进行了一系列消融实验。表2显示了结果。
表2: 消融研究结果
变体 | 对随机 | 对规则 | 对CQN | ELO分数
DouZero (完整版) | 100% | 80% | 65% | 1600
- 动作编码 | 100% | 70% | 55% | 1400
- 并行演员 | 100% | 75% | 60% | 1500
- 蒙特卡罗更新 | 95% | 60% | 45% | 1100
从这些结果中,我们可以得出以下结论:
-
动作编码:移除动作编码导致性能显著下降,特别是在对抗更强的对手时。这证实了我们提出的动作编码方法的有效性。
-
并行演员:没有并行演员,模型的性能略有下降。这表明并行演员确实提高了学习效率,尽管不如动作编码那么关键。
-
蒙特卡罗更新:用TD(0)更新替换蒙特卡罗更新导致了最大的性能下降。这证实了我们之前的假设,即在具有大动作空间的环境中,蒙特卡罗方法可以避免过估计问题。
总的来说,这些结果表明DouZero的每个组件都对其性能做出了重要贡献。
- 结论
在本文中,我们提出了DouZero,这是一种新的深度强化学习方法,用于解决斗地主这一具有挑战性的多人不完全信息游戏。DouZero结合了蒙特卡罗方法、深度神经网络、新颖的动作编码和并行训练,成功地处理了斗地主的大状态和动作空间。我们的实验结果表明,DouZero显著优于现有的方法,包括基于规则的启发式方法和之前最先进的DeltaDou。
DouZero的成功为解决其他具有大动作空间的复杂游戏提供了新的思路。未来的工作可能包括将我们的方法扩展到其他类型的纸牌游戏,或探索将DouZero与搜索方法(如MCTS)相结合的可能性。
虽然我们的工作主要集中在游戏AI上,但所开发的技术可能对其他领域也有潜在的应用,例如复杂的决策问题或多智能体系统。我们希望我们的工作能为这些领域的未来研究提供有价值的见解。

















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











