







一、原文链接
论文:https://arxiv.org/pdf/2103.10360.pdf
二、原文翻译
摘要:
目前已经发展出多种预训练模型,包括自编码模型(如BERT)、自回归模型(如GPT)和编码器-解码器模型(如T5)。然而,这些模型并未在自然语言理解(NLU)、无条件生成和条件生成这三类任务中都达到最佳表现。为此,我们提出了一个基于自回归式空格填充的通用模型(GLM)以应对这一挑战。GLM通过加入二维位置编码,并允许以任意顺序预测片段,优化了空格填充预训练,这使得其在NLU任务上的性能优于BERT和T5。同时,GLM可以通过调整空白数量和长度,针对不同类型的任务进行预训练。在包括NLU、条件生成和无条件生成的一系列任务中,GLM在相同模型大小和数据条件下,性能超越了BERT、T5和GPT,并且使用1.25倍BERTLarge参数的单一预训练模型取得了最佳性能,显示出其适用于多种下游任务的泛化能力。
1 介绍
在未标注文本上预训练的语言模型已经在各种自然语言处理(NLP)任务中显著提升了技术水平,这些任务包括自然语言理解(NLU)到文本生成(Radford等人,2018a;Devlin等人,2019;Yang等人,2019;Radford等人,2018b;Raffel等人,2020;Lewis等人,2019;Brown等人,2020)。过去几年中,下游任务性能以及参数规模也在持续增长。
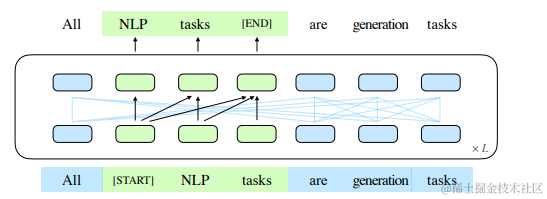
图 1:GLM 示意图。我们屏蔽文本片段(绿色部分)并以自回归方式生成它们。(一些注意力边缘被省略;参见 Figure 2。)
总的来说,现有的预训练框架可以分为三个家族:自回归模型、自编码模型和编码器-解码器模型。自回归模型,如 GPT (Radford et al., 2018a),学习从左到右的语言模型。尽管它们在长文本生成方面取得了成功,并在参数扩展到数十亿时显示出小样本学习能力(Radford et al., 2018b; Brown et al., 2020),但其固有的缺点是单向注意力机制,这在自然语言理解(NLU)任务中无法完全捕捉上下文单词之间的依赖关系。自编码模型,如 BERT (Devlin et al., 2019),通过去噪目标(例如遮蔽语言模型(MLM))学习双向上下文编码器。这些编码器产生适合自然语言理解任务的上下文化表示,但不能直接应用于文本生成。编码器-解码器模型对编码器采用双向注意力,解码器采用单向注意力,并在它们之间进行跨注意力(Song et al., 2019; Bi et al., 2020; Lewis et al., 2019)。它们通常用于条件生成任务,如文本摘要和响应生成。T5 (Raffel et al., 2020) 通过编码器-解码器模型统一了自然语言理解(NLU)和条件生成任务,但需要更多的参数来匹敌基于 BERT 的模型,如 RoBERTa (Liu et al., 2019) 和 DeBERTa (He et al., 2021) 的性能。
这些预训练框架中没有一个是足够灵活的,能够在所有自然语言处理(NLP)任务中都具有竞争力。先前的研究尝试通过多任务学习(Dong et al., 2019; Bao et al., 2020)结合不同框架的目标来实现框架的统一。然而,由于自编码和自回归目标在本质上存在差异,简单的统一无法完全继承两个框架的优势。
在本文中,我们提出了一种名为 GLM(通用语言模型)的预训练框架,基于自回归空白填充。我们从输入文本中随机屏蔽连续的 token 片段,遵循自编码的思想,并训练模型按顺序重建这些片段,遵循自回归预训练的思想(见图 1)。虽然空白填充已在 T5 (Raffel et al., 2020) 中用于文本到文本的预训练,但我们提出了两个改进,即片段shuffling和二维位置编码。实证研究表明,在相同数量的参数和计算成本下,GLM 在 SuperGLUE 基准测试中显著优于 BERT,领先幅度为 4.6% – 5.0%,并且在与 RoBERTa 和 BART 预训练相同大小的语料库(158GB)时也表现出优势。GLM 还在参数和数据较少的情况下,显著优于 T5 在自然语言理解(NLU)和生成任务上的表现。
受 Pattern-Exploiting Training (PET)(Schick and Schütze, 2020a)的启发,我们将自然语言理解(NLU)任务重新构想为模仿人类语言的精心设计的完形填空问题。与 PET 使用的基于 BERT 的模型不同,GLM 可以通过自回归空白填充自然地处理对完形填空问题的多 token 答案。
此外,我们还展示了通过改变缺失片段的数量和长度,自回归空白填充目标可以预训练适用于条件生成和无条件生成的语言模型。通过不同预训练目标的多任务学习,单一的 GLM 可以在自然语言理解(NLU)以及(条件和无条件的)文本生成方面表现出色。实证研究表明,与独立的基线模型相比,通过共享参数,进行多任务预训练的 GLM 在 NLU、条件文本生成和语言建模任务上均取得了整体性能的提升。
2 GLM 预训练框架
我们提出了一种新颖的基于自回归空白填充的通用预训练框架 GLM。GLM 将自然语言理解(NLU)任务构想为包含任务描述的完形填空问题,这些问题可以通过自回归生成来回答。
2.1 预训练目标
2.1.1 Autoregressive Blank Infilling
GLM 通过优化自回归空白填充目标进行训练。给定一个输入文本 x = [x1, · · · , xn],从中采样多个文本片段 {s1, · · · , sm},其中每个片段 si 对应于 x 中的连续 token 系列 [si,1, · · · , si,li]。每个片段被替换为一个单独的 [MASK] 符号,形成一个被破坏的文本 xcorrupt。模型从被破坏的文本中以自回归方式预测片段中的缺失 token,这意味着在预测一个片段的缺失 token 时,模型可以访问被破坏的文本和之前预测的片段。为了完全捕捉不同片段之间的相互依赖关系,我们像排列语言模型(Yang et al., 2019)一样随机排列片段的顺序。
正式地,设 Zm 是长度为 m 的索引序列 [1, 2, · · · , m] 的所有可能排列的集合,且 sz<i = [sz1, · · · , szi−1],我们定义预训练目标为:
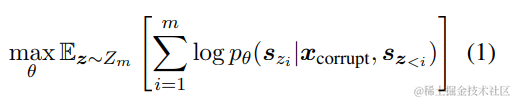
我们总是按照从左到右的顺序生成每个空白中的 token,即生成片段 si 的概率可以分解为:
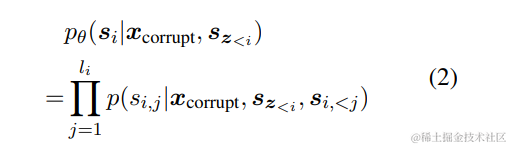
我们使用以下技术实现了自回归空白填充目标。输入 x 被分为两部分:部分 A 是被破坏的文本 xcorrupt,部分 B 包括被遮蔽的片段。部分 A 的 token 可以相互attend,但不能attend B 中的任何 token。部分 B 的 token 可以attend A 和 B 中的先行词,但不能attend B 中的任何后续 token。为了实现自回归生成,每个片段分别用特殊 token [START] 和 [END] 进行填充,用于输入和输出。通过这种方式,我们的模型自动学习了一个双向编码器(用于部分 A)和一个单向解码器(用于部分 B),在一个统一模型中。GLM 的实现如图 2 所示。
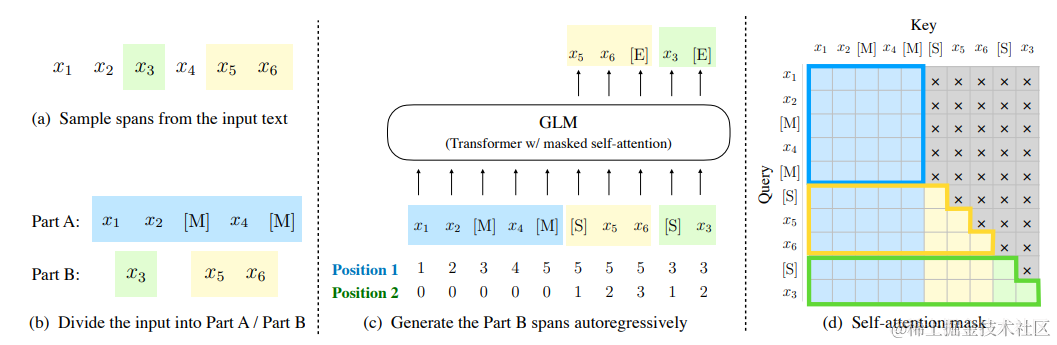
图 2:GLM 预训练。 (a) 原始文本是 [x1, x2, x3, x4, x5, x6]。采样了两个片段 [x3] 和 [x5, x6]。(b) 在部分 A 中用 [M] 替换采样的片段,并在部分 B 中打乱片段。 © GLM 自回归地生成部分 B。每个片段前面加上 [S] 作为输入,后面加上 [E] 作为输出。二维位置编码表示片段间和片段内的位置。 (d) 自注意力掩码。灰色区域被遮蔽。部分 A 的 token 可以相互关注(蓝色框架),但不能关注 B。部分 B 的 token 可以关注 A 和 B 中的先行词(黄色和绿色框架对应于两个片段)。 M := MASK, S := START, E := END
我们从泊松分布 λ=3 中随机采样片段的长度。我们重复采样新片段,直到至少 15% 的原始 token 被遮蔽。经验上,我们发现 15% 的比例对于下游 NLU 任务的优良性能至关重要。
2.1.2 Multi-Task Pretraining
在前一节中,GLM mask了短span,适用于 NLU 任务。然而,我们感兴趣的是预训练一个能够处理 NLU 和文本生成的单一模型。因此,我们研究了多任务预训练设置,其中与空白填充目标一起联合优化了生成更长文本的第二个目标。我们考虑以下两个目标:
• 文档级别。我们采样一个单一片段,其长度从原始长度的 50% 到 100% 的均匀分布中采样。该目标旨在进行长文本生成。
• 句子级别。我们限制被遮蔽的片段必须是完整的句子。采样多个片段(句子)以覆盖原始 token 的 15%。这个目标旨在进行 seq2seq 任务,其预测通常是完整的句子或段落。两个新目标都是以与原始目标相同的方式定义的,即 Eq. 1。唯一的区别是span的数量和span长度。
2.2 模型架构
GLM 使用了一个带有几处修改的单个 Transformer 架构: (1) 我们重新排列了层规范化(layer normalization)和残差连接(residual connection)的顺序,这在避免大规模语言模型中的数值错误方面已被证明是关键的(Shoeybi et al., 2019); (2) 我们使用了一个单线性层进行输出 token 预测; (3) 我们用 GeLU 激活函数替换了 ReLU 激活函数(Hendrycks and Gimpel, 2016)。
2.2.1 2D Positional Encoding
自回归空白填充任务的一个挑战是如何编码位置信息。Transformer 依赖于位置编码来注入 token 的绝对和相对位置。我们提出了二维位置编码来解决这个问题。具体来说,每个 token 被编码为两个位置 id。第一个位置 id 表示在破坏的文本 xcorrupt 中的位置。对于被遮蔽的片段,它是相应 token 的位置。第二个位置 id 表示片段内的位置。对于部分 A 中的 token,它们的第二个位置 id 是 0。对于部分 B 中的 token,它们从 1 变化到片段的长度。这两个位置 id 通过可学习的嵌入表被投射成两个向量,这两个向量都被添加到输入 token 嵌入中。
我们的编码方法确保在重建它们时,模型不会意识到被遮蔽片段的长度。这与其他模型相比是一个重要的不同点。例如,XLNet (Yang et al., 2019) 编码原始位置,以便它可以感知缺失的 token 数量,而 SpanBERT (Joshi et al., 2020) 用多个 token 替换片段并保持长度不变。我们的设计适合于下游任务,因为通常在生成文本之前,其长度是未知的。
2.3 微调 GLM
通常,对于下游 NLU 任务,一个线性分类器会采用预训练模型产生的序列或 token 的表示作为输入,并预测正确的标签。这些做法与生成式预训练任务不同,导致预训练和微调之间存在不一致性。
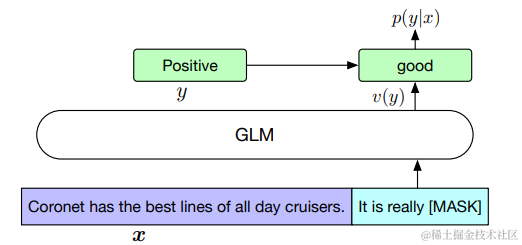
相反,我们遵循 PET (Schick and Schütze, 2020a) 的方法,将 NLU 分类任务重新表述为空白填充的生成任务。具体来说,给定一个带标签的示例(x, y),我们通过包含单个遮蔽 token 的模式将输入文本 x 转换为完形填空问题 c(x)。这个模式是用自然语言编写的,以表示任务的语义。例如,一个情感分类任务可以表述为:“{SENTENCE}。It’s really [MASK]”. 候选标签 y ∈ Y 也被映射为填空问题的答案,称为词化器 v(y)。在情感分类中,标签“正面”和“负面”被映射为单词“好”和“坏”。给定 x 的条件下预测 y 的条件概率为
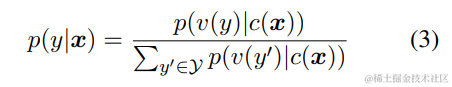
其中 Y 是标签集。因此,句子是正面或负面的概率与在空白中预测“好”或“坏”成正比。然后我们使用交叉熵损失(见图 3)微调 GLM。
对于文本生成任务,给定的上下文构成了输入的部分 A,并在最后添加了一个遮蔽 token。模型以自回归方式生成部分 B 的文本。我们可以直接将预训练的 GLM 应用于无条件生成,或者在下游的条件生成任务上对其进行微调。
2.4 讨论与分析
在本节中,我们讨论了 GLM 与其他预训练模型之间的差异。我们主要关注它们如何适应下游空白填充任务。
与 BERT (Devlin et al., 2019) 的比较。 正如 (Yang et al., 2019) 指出的,由于 MLM 的独立性假设,BERT 无法捕捉被遮蔽 token 之间的相互依赖性。BERT 的另一个缺点是,它无法正确填充多个 token 的空白。为了推断长度为 l 的答案的概率,BERT 需要执行 l 个连续的预测。如果长度 l 是未知的,我们可能需要枚举所有可能的长度,因为 BERT 需要根据长度改变 token 的数量。
与 XLNet (Yang et al., 2019) 的比较。 GLM 和 XLNet 都使用自回归目标进行预训练,但它们之间有两个差异。首先,XLNet 在破坏之前使用原始位置编码。在推理过程中,我们需要知道或枚举答案的长度,与 BERT 相同的问题。第二,XLNet 使用双流自注意力机制,而不是右移,以避免 Transformer 内的信息泄露。这使得预训练的时间成本翻倍。
与 T5 (Raffel et al., 2020) 的比较。 T5 提出了一种类似于空白填充的目标来预训练一个编码器-解码器 Transformer。T5 为编码器和解码器使用独立的 positional encodings,并依赖于多个哨兵 token 来区分被遮蔽的片段。在下游任务中,只使用其中一个哨兵 token,导致模型容量的浪费和预训练与微调之间的不一致。此外,T5 总是以固定的从左到右的顺序预测片段。因此,如第 3.2 节和第 3.3 节所述,GLM 可以在参数和数据更少的情况下,在 NLU 和 seq2seq 任务上显著优于 T5。
与 UniLM (Dong et al., 2019) 的比较。 UniLM 通过在自编码框架下改变注意力掩码,将不同的预训练目标结合起来,这些目标包括双向、单向和交叉注意力。然而,UniLM 总是用单个 token 替换被遮蔽的片段,这限制了它建模被遮蔽片段与其上下文之间依赖关系的能力。GLM 输入前一个 token 并自回归地生成下一个 token。UniLM 在下游生成任务上的微调也依赖于遮蔽语言模型,这效率较低。UniLMv2 (Bao et al., 2020) 为生成任务采用了部分自回归建模,同时为 NLU 任务保留了自编码目标。相反,GLM 通过自回归预训练统一了 NLU 和生成任务。
3 实验
现在我们描述我们的预训练设置和下游任务的评估。
3.1 预训练设置
为了与 BERT (Devlin et al., 2019) 进行公平比较,我们使用 BooksCorpus (Zhu et al., 2015) 和英语维基百科作为我们的预训练数据。我们使用 BERT 的不区分大小写的词片段标记器,该标记器具有 30k 的词汇量。我们使用与 BERTBase 和 BERTLarge 相同的架构训练 GLMBase 和 GLMLarge,分别包含 110M 和 340M 个参数。
对于多任务预训练,我们训练了两个大型模型,这些模型混合了空白填充目标和文档级或句子级目标,分别标记为 GLMDoc 和 GLMSent。
另外,我们还训练了两个更大的 GLM 模型,分别是 410M(30 层,隐藏层大小为 1024,16 个注意力头)和 515M(30 层,隐藏层大小为 1152,18 个注意力头)参数,这些模型使用了文档级的多任务预训练,分别标记为 GLM410M 和 GLM515M。
为了与最先进的模型进行比较,我们还训练了一个与 RoBERTa (Liu et al., 2019) 相同数据、标记化和超参数的大型模型,标记为 GLMRoBERTa。由于资源限制,我们只预训练了模型 250,000 个步骤,这是 RoBERTa 和 BART 训练步骤的一半,并且接近 T5 训练的 token 数量。更多关于实验的细节可以在附录 A 中找到。
3.2 SuperGLUE任务
为了评估我们的预训练 GLM 模型,我们在 SuperGLUE 基准测试(Wang et al., 2019)上进行了实验,并报告了标准指标。SuperGLUE 包括 8 个具有挑战性的自然语言理解(NLU)任务。我们遵循 PET (Schick and Schütze, 2020b) 的方法,将分类任务重新表述为使用人工设计的完形填空问题,即空白填充。然后我们按照第 2.3 节所述,在每个任务上微调预训练的 GLM 模型。完形填空问题和其他细节可以在附录 B 中找到。
为了与 GLMBase 和 GLMLarge 进行公平比较,我们选择了 BERTBase 和 BERTLarge 作为我们的基线,这些模型在相同的数据集上进行了预训练,并且预训练的时间长度相似。我们报告了标准微调(即在 [CLS] token 表示上进行分类)的性能。BERT 使用完形填空问题的性能报告在第 3.4 节。
为了与 GLMRoBERTa 进行比较,我们选择了 T5、BARTLarge 和 RoBERTaLarge 作为我们的基线。T5 在 BERTLarge 的参数数量上没有直接对应,因此我们展示了 T5Base(2.2 亿参数)和 T5Large(7.7 亿参数)的结果。所有其他基线都与 BERTLarge 大小相似。
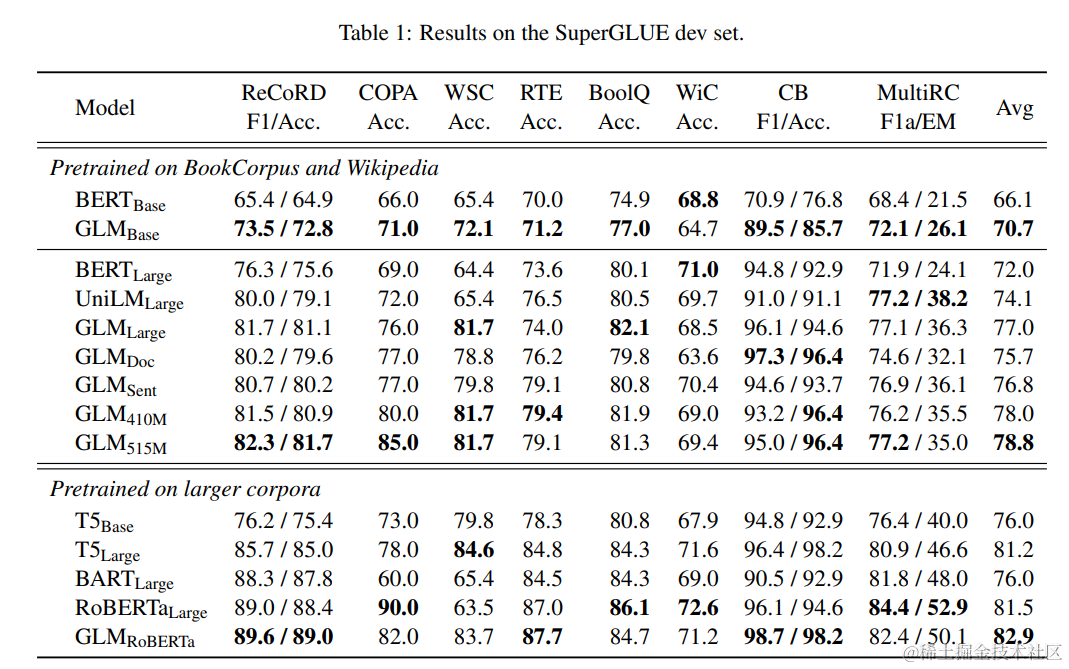
表 1 显示了结果。在相同数量的训练数据下,GLM 在大多数任务上,无论是基础架构还是大型架构,都一致地优于 BERT。唯一的例外是 WiC(词义消歧)。平均而言,GLMBase 的得分比 BERTBase 高出 4.6%,GLMLarge 的得分比 BERTLarge 高出 5.0%。这清楚地表明了我们在 NLU 任务上的方法的优势。
在 RoBERTaLarge 的设置下,GLMRoBERTa 仍然能够超过基线,但改进的幅度较小。具体来说,GLMRoBERTa 超过了 T5Large,但体积只有其一半。我们还发现,BART 在具有挑战性的 SuperGLUE 基准测试中表现不佳。我们推测这可能是由于编码器-解码器架构的低参数效率和去噪序列到序列的目标导致的。
3.3 Multi-Task Pretraining
然后我们评估了 GLM 在多任务设置中的性能(第 2.1 节)。在一个训练批次内,我们以相等的机会采样短片段和更长片段(文档级或句子级)。我们评估多任务模型在 NLU、seq2seq、空白填充和零样本语言建模方面的性能。
SuperGLUE. 对于 NLU 任务,我们在 SuperGLUE 基准测试上评估模型。结果也显示在表 1 中。我们观察到,进行多任务预训练后,GLMDoc 和 GLMSent 的表现略低于 GLMLarge,但仍优于 BERTLarge 和 UniLMLarge。在多任务模型中,GLMSent 平均比 GLMDoc 表现好 1.1%。将 GLMDoc 的参数增加到 410M(1.25×BERTLarge)可以比 GLMLarge 获得更好的性能。拥有 515M 个参数的 GLM(1.5×BERTLarge)可以表现得更好。
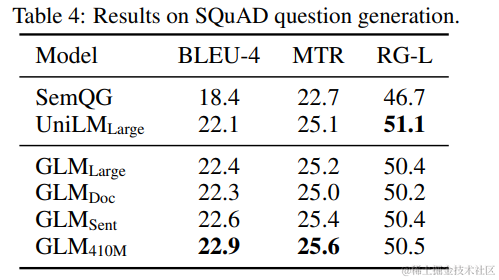
Sequence-to-Sequence. 考虑到可用的基线结果,我们使用 Gigaword 数据集(Rush et al., 2015)进行抽象摘要,使用 SQuAD 1.1 数据集(Rajpurkar et al., 2016)进行问题生成(Du et al., 2017)作为在 BookCorpus 和维基百科上预训练的模型的基准。此外,我们使用 CNN/DailyMail(See et al., 2017)和 XSum(Narayan et al., 2018)数据集进行抽象摘要,作为在更大语料库上预训练的模型的基准。
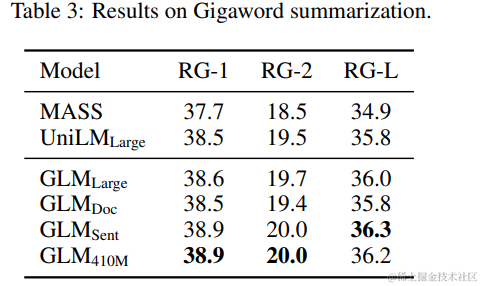
在 BookCorpus 和维基百科上训练的模型的结果在表 3 和表 4 中展示。我们观察到,GLMLarge 在这两个生成任务上的表现与其它预训练模型相当。GLMSent 能够比 GLMLarge 表现得更好,而 GLMDoc 的表现略差于 GLMLarge。这表明文档级目标,即教模型扩展给定上下文,对于条件生成任务(旨在从上下文中提取有用信息)的帮助较小。将 GLMDoc 的参数增加到 410M,使得在这两个任务上都取得了最佳表现。在更大语料库上训练的模型的结果在表 2 中展示。GLMRoBERTa 能够达到与 seq2seq BART 模型相匹配的性能,并且超过了 T5 和 UniLMv2。
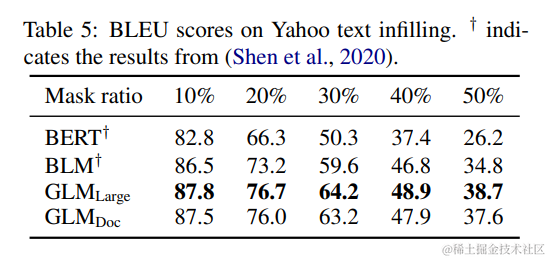
GLM 在 Yahoo Answers 数据集(Yang et al., 2017)上进行了评估,并与专门为文本填充设计的 Blank Language Model (BLM)(Shen et al., 2020)进行了比较。从表 5 的结果来看,GLM 在此数据集上取得了最先进的成果,并且显著优于之前的方法(1.3 到 3.9 BLEU 的提升)。我们注意到,GLMDoc 在此任务上的表现略低于 GLMLarge,这与我们在 seq2seq 实验中的观察是一致的。
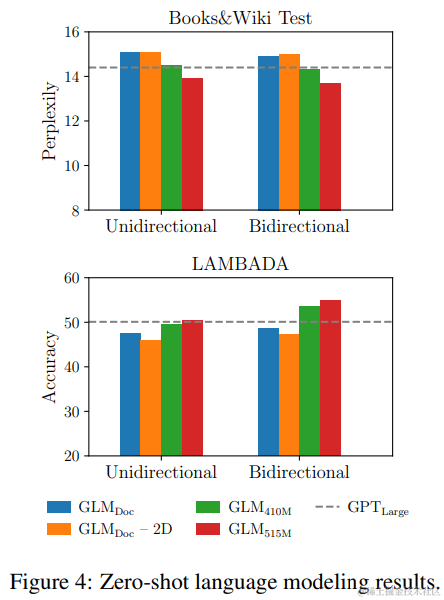
Language Modeling. 大多数语言建模数据集,如 WikiText103,都是从维基百科文档构建的,而这些文档已经包含在我们的预训练数据集中。因此,我们在包含约 20M 个 token 的预训练数据集的保留测试集上评估语言建模困惑度,该数据集被称为 BookWiki。我们还评估了 GLM 在 LAMBADA 数据集(Paperno et al., 2016)上的表现,该数据集测试了系统在文本中建模长距离依赖的能力。任务是预测一段文字的最后一个词。作为基线,我们使用与 GLMLarge 相同的数据和标记化训练了一个 GPTLarge 模型(Radford et al., 2018b; Brown et al., 2020)。
结果如图 4 所示。所有模型都在零样本设置下进行评估。由于 GLM 学习了双向注意力,我们还在上下文使用双向注意力的设置下评估 GLM。在没有生成目标的情况下进行预训练,GLMLarge 不能完成语言建模任务,困惑度大于 100。具有相同数量的参数,GLMDoc 的表现比 GPTLarge 差。这是预期的,因为 GLMDoc 也优化了空白填充目标。将模型参数增加到 410M(GPTLarge 的 1.25 倍)使得性能接近 GPTLarge。GLM515M(GPTLarge 的 1.5 倍)可以进一步超越 GPTLarge。具有相同数量的参数,使用双向注意力编码上下文可以提高语言建模的性能。在这种设置下,GLM410M 超过了 GPTLarge。这是 GLM 相对于单向 GPT 的优势。我们还研究了二维位置编码对长文本生成的贡献。我们发现,移除二维位置编码会导致语言建模的准确率降低,困惑度升高。
总结。 总的来说,我们得出结论,GLM 有效地在自然语言理解和生成任务之间共享模型参数,其性能优于单独的 BERT、编码器-解码器或 GPT 模型。
4 相关工作
预训练语言模型。 大规模预训练语言模型显著提高了下游任务的性能。目前有三种预训练模型。首先,自编码模型通过去噪目标学习一个双向上下文化的编码器,用于自然语言理解(Devlin et al., 2019; Joshi et al., 2020; Yang et al., 2019; Liu et al., 2019; Lan et al., 2020; Clark et al., 2020)。其次,自回归模型是通过从左到右的语言建模目标进行训练的(Radford et al., 2018a,b; Brown et al., 2020)。第三,编码器-解码器模型是为序列到序列任务进行预训练的(Song et al., 2019; Lewis et al., 2019; Bi et al., 2020; Zhang et al., 2020)。
在编码器-解码器模型中,BART(Lewis et al., 2019)通过将相同的输入喂入编码器和解码器,并使用解码器的最后隐状态来进行 NLU 任务。相反,T5(Raffel et al., 2020)将大多数语言任务公式化为文本到文本框架。然而,这两种模型都需要更多的参数才能超过自编码模型,如 RoBERTa(Liu et al., 2019)。UniLM(Dong et al., 2019; Bao et al., 2020)在一个遮蔽语言建模目标下统一了三种预训练模型,使用了不同的注意力掩码。
NLU as Generation. 以前,预训练语言模型使用线性分类器在学习的表示上完成 NLU 的分类任务。GPT-2(Radford et al., 2018b)和 GPT-3(Brown et al., 2020)表明,生成式语言模型可以完成 NLU 任务,如问答,只需直接预测正确的答案而不需要微调,给定任务指令或几个标注示例。然而,生成式模型需要更多的参数才能工作,这是由于单向注意力限制的结果。最近,PET(Schick and Schütze, 2020a,b)提出将输入示例重新表述为与预训练语料库相似的完形填空问题,在少样本设置中。与 GPT-3 相比,结合基于梯度的微调,PET 在少样本设置中可以取得更好的性能,而只需要其参数的 0.1%。类似地,Athiwaratkun 等人(2020)和 Paolini 等人(2020)将结构化预测任务,如序列标注和关系提取,转换为序列生成任务。
Blank Language Modeling. Donahue 等人(2020)和 Shen 等人(2020)也研究了空白填充模型。与他们的研究不同,我们使用空白填充目标预训练语言模型,并评估它们在下游 NLU 和生成任务中的表现。
5 Conclusions
GLM 是一个适用于自然语言理解和生成的通用预训练框架。我们表明,NLU 任务可以被表述为条件生成任务,因此可以通过自回归模型来解决。GLM 将不同任务的预训练目标统一为自回归空白填充,采用了混合注意力掩码和新的二维位置编码。实证结果显示,GLM 在 NLU 任务上优于之前的方法,并且可以有效地在不同任务之间共享参数。
三、关键技术点总结
1、 Autoregressive Blank Infilling 自回归 空格填充
GLM通过优化一个自回归空白填充目标来进行训练。给定一个输入文本 x = [x1, · · · , xn],会采样多个文本跨度 {s1, · · · , sm},其中每个跨度 si 对应于 x 中一系列连续的标记 [si_1, si_2, · · · , si_n]。
每个跨度被替换为一个单一的[MASK]标记,形成被破坏的文本 xcorrupt。模型以自回归的方式预测被破坏文本中跨度内缺失的标记,这意味着在预测一个跨度中缺失的标记时,模型可以访问到被破坏的文本以及之前已经预测出的跨度。为了充分捕捉不同跨度之间的相互依赖性,作者随机打乱跨度的顺序,类似于排列语言模型。
数学语言表达:
设 Zm 为长度为 m 的索引序列 [1, 2, · · · , m] 的所有可能排列的集合,且 sz<i 为 [sz1, · · · , szi-1],我们定义预训练目标为:
我们总是按照从左到右的顺序在每个空白处生成标记,即生成跨度 si 的概率被分解为:
1.1 具体实现方面:
输入 x 被分为两部分:A部分是被破坏的文本 xcorrupt,B部分由被mask的跨度组成。A部分的token是相互可见的,但不能看到B 部分中的任何token。B部分的token可以看到 A 部分和 B 部分中的先行词,但不能看到 B 部分中任何后续的token。
为了实现自回归生成,每个跨度都分别用特殊标记 [START] 和 [END] 进行填充,分别用于输入和输出。通过这种方式,我们的模型自动学习了一个双向编码器(用于 A 部分)和一个单向解码器(用于 B 部分),统一在一个模型中。GLM 的实现如图 2 所示。
(a),將输入文本的部分进行mask: x_3 和 [x_5, x_6]
(b),mask部分用[M]替代的原句作为Part A输入, mask部分重新打乱(保证充分考虑mask部分之间的信息关系,后见Attention部分)排序作为Part B预输入
©,将分开的AB两部分加上对应的2D位置编码作为模型输入,mask部分用S:start来表示mask部分的开始,输出部分以E:end来作为一个span预测结果的结束
(d),
Part A中的词彼此可见(保证充分提取corrupt text的信息)
Part B中的词单向可见(既防止了span内右侧信息的泄露,长也防止了span外右侧未预测信息的泄露
Part B可见PartA(空格填充的目标,根据corrupt text的信息补全文章)
Part B打乱顺序
上面的例子可以看到,作者mask了 比较短的span, 更像是bert的 MLM,更适用于自然语言理解任务(NLU), 同时,为了解决单一模型应对多种任务(自然语言生成)的问题,作者研究了一个多任务的预训练策略, 生成更长文本的第二个目标与空白填充目标一起被联合优化。
策略一: 在文档级别,作者采样一个单一的跨度,其长度是从原始长度的50%到100%的均匀分布中随机抽取的。这个目标旨在生成长文本。
策略二:在句子级别,限制被mask的跨度必须是完整的句子。会采样多个跨度(句子),以覆盖原始标记的15%。这个目标旨在针对那些预测通常是完整句子或段落的序列到序列(seq2seq)任务。
2、架构方面的优化点:
GLM使用一个单一的Transformer架构,并对其进行了几项修改:(1)重新排列了层归一化和残差连接的顺序,这已被证明对于避免大规模语言模型中的数值错误至关重要(2)使用单个线性层来预测输出token;(3)我们用GeLU激活函数替换了ReLU激活函数。
3、二维位置编码
自回归空白填充任务的一个挑战是如何编码位置信息。Transformer依赖于位置编码来注入标记的绝对位置和相对位置信息。
作者提出了二维位置编码来应对这一挑战。具体来说,每个标记都使用两个位置ID进行编码。第一个位置ID代表在被破坏的文本xcorrupt中的位置。
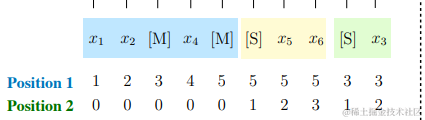
对Part A,position 1就是绝对位置,position 2就是0。
对Part B, position 1就是掩盖位置,position 2就是句内的相对位置(从1开始)
模型能够学习到span生成的长度,这样可以很好的处理下游任务生成文本的长度不确定的问题。
对于被mask的跨度,这两个位置ID通过可学习的嵌入表被投影成两个向量,这两个向量都会被加到输入token embedding 中。这与其他模型相比是一个重要的不同点。例如,XLNet编码原始位置,以便它可以感知缺失标记的数量,而SpanBERT用多个[MASK]标记替换跨度,并保持长度不变。我们的设计适应了下游任务,因为通常生成文本的长度是事先未知的。
在预训练过程中,作者从输入文本中随机抽取长度遵循泊松分布(参数λ设为3)的跨度。我们会重复这个抽取过程,直到至少有15%的原始标记被mask(即被替换为[MASK]标记)。根据经验,我们发现15%这个比例对于在下游自然语言理解(NLU)任务上取得良好性能是非常关键的。简而言之,这是一种确保预训练模型能够有效学习并适应后续任务的策略,通过控制掩盖标记的比例来优化模型的泛化能力和性能。
4、PET范式
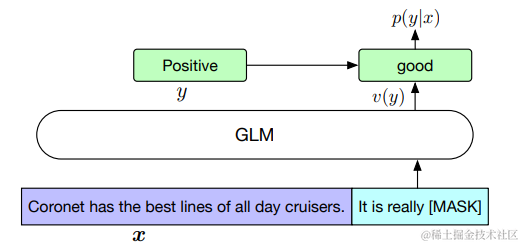
对于情感分析的句子,用统一模板“{SENTENCE}.lt’s really[MASK”进行输入,就巧妙转化为空格填充任务,使模型目标不变。
候选标签也会映射到一个verbalizer中,比如说判断出是positive的,就会在verbalizer中找到对应结果good.
总结
GLM 能够在自然语言理解和文本生成任务之间有效地共享参数,一个预训练好的 GLM 模型可以用于多种下游任务,从而提高模型的泛化能力和效率,是很值得学习的一个模型















 4139
4139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









