







这是清华团队基于GLM架构推出一款千亿级别参数量的大模型。GLM架构请见:论文浅读:GLM(General Language Model Pretraining)
摘要
GLM-130B是个双语(中文和英文)预训练语言模型,有1300亿的参数。作者尝试开源一个效果比GPT3好、千亿级别的大语言模型,并且揭示这个尺度的大模型是如何训练的。GLM-130B 在大量主流的英文领域评测集上的表现已经超过GPT3-175B,而大模型 OPT-175B 和 BLOOM-176B也没有优势。在中文领域,和ERNIE TITAN 3.0 260B(目前最大的中文语言模型)相比,GLM-130B的表现也更佳。通过利GLM-130B的缩放特性来实现int4量化,使它成为第一个千亿级别的模型。它可以在4张RTX 3090 (24G) 或者8张RTX 2080 Ti (11G) 进行推理。
GLM-130B开源地址:https://github.com/THUDM/GLM-130B
一、介绍
大语言模型(LLM)在zero-shot 和 few-shot的任务上有明显的优势,特别是模型参数量超过千亿级别(100B)的时候。像GPT3-175B千亿级别的大模型在各种评测集上的表现超过了全监督BERT-Large模型。但GPT3并未开源,所以和大家分享如何训练出如此大规模高质量的大模型是非常有价值的。
和百亿级别的模型相比,训练如此规模大小(100B)的大模型,会面临很多技术和工程上面的挑战,比如在预训练的效率、稳定性和收敛性方面。在训练 OPT-175B和BLOOM-176B 模型的时候也有这些方面的问题。
我们将从工程方面的努力、模型的设计和选择、高效稳定的训练策略和可负担推理接口的量化操作几方面来介绍GLM-130B。特别是训练时候的稳定性,这是决定训练一个千亿级别模型成功的关键。与在OPT-175B中手动调整学习率和在BLOOM-176B中使用嵌入范数来牺牲性能等做法不同,我们对各种选项进行了实验,发现嵌入梯度收缩策略可以明显提高GLM-130B训练时的稳定性。
和GPT系列的架构不同,GLM-130B使用的是GLM架构,它是利用了双向attention机制和自回归空白填充的优势。下图是GLM-130B和其他一些主流的LLM在是否开源、模型结构、训练、推理上的对比:
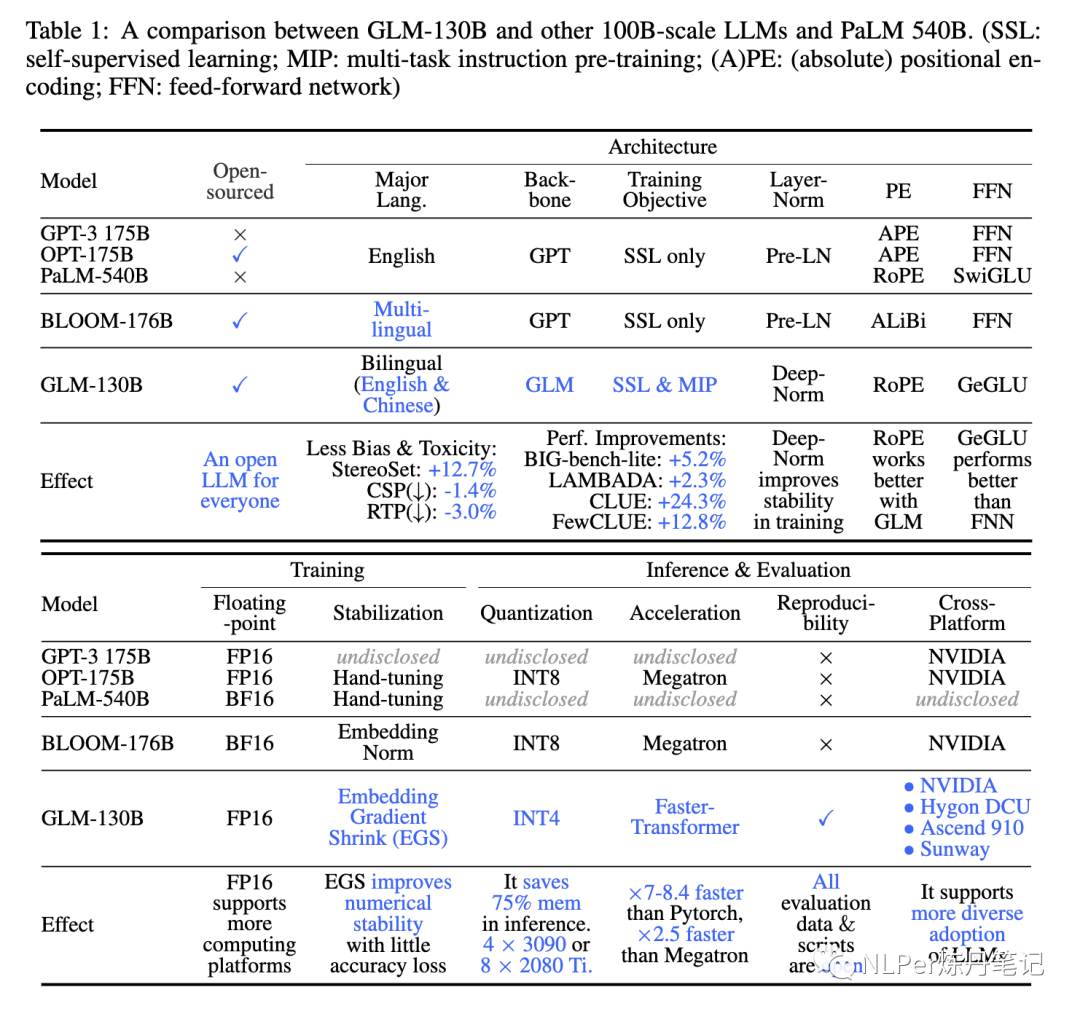
可以看到,GLM-130B是基于GLM的backbone,但是和原始的GLM相比,在模型结构上也做了些改进:
1)layer norm:使用 Deep-Norm 来提供模型训练的稳定性。
2)PE:使用RoPE(旋转位置编码)替换2D PE。
3)FFN:使用GeGLU 替换 GeLU 。
模型效果评估表现请见下图:
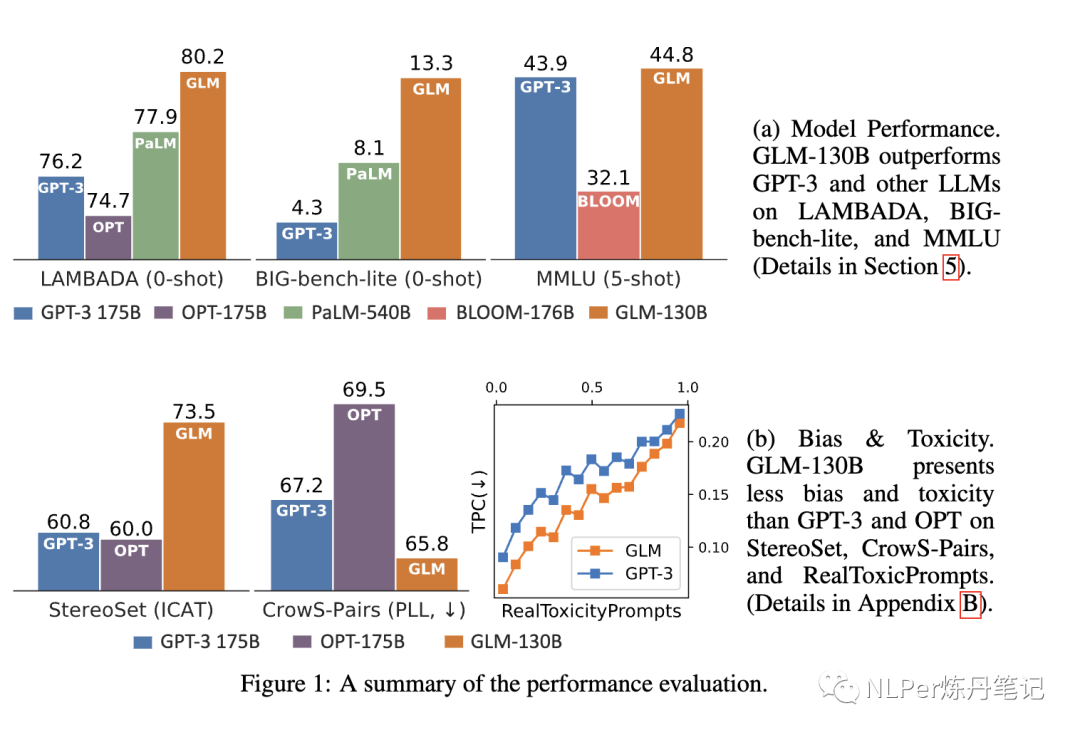
总结就是:效果好,偏见毒性少
GLM-130B使更多人可以对千亿规模的大模型进行研究原因有以下两点:
1)单个A100的卡可以对GLM-130B进行部署,而175B+的大模型(如OPT 、BLOOM)不行。
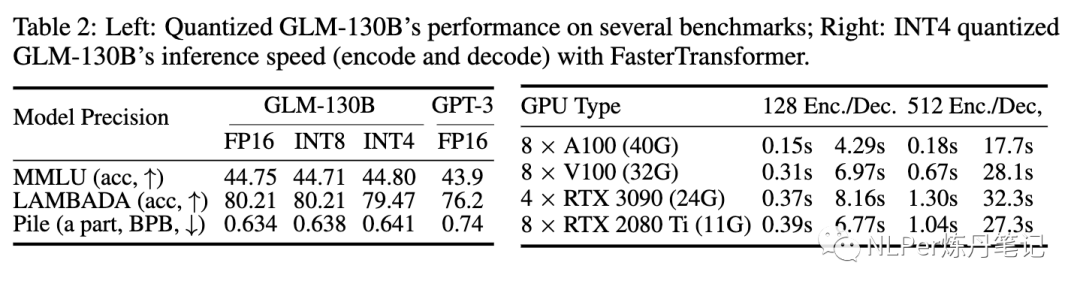
2)为了再降低GPU的要求,在对量化无感知无影响的情况下,对GLM-130B做了int4量化,而OPT 和 BLOOM只做了int8量化。GLM-130B int4压缩版在LAMBADA 评测集上效果只降低了0.74%,在MMLU上升至提高了+0.05% ,即使这样,它的效果仍然超过无压缩的GPT3。
二、GLM-130B的设计选择
1.模型架构
1)GLM作为Backbone:GLM输入是双向attention机制,输出是单向attention机制。通过不同的mask策略来使模型具有自编码和自回归的能力。具体GLM原理请参考:论文浅读:GLM(General Language Model Pretraining)。
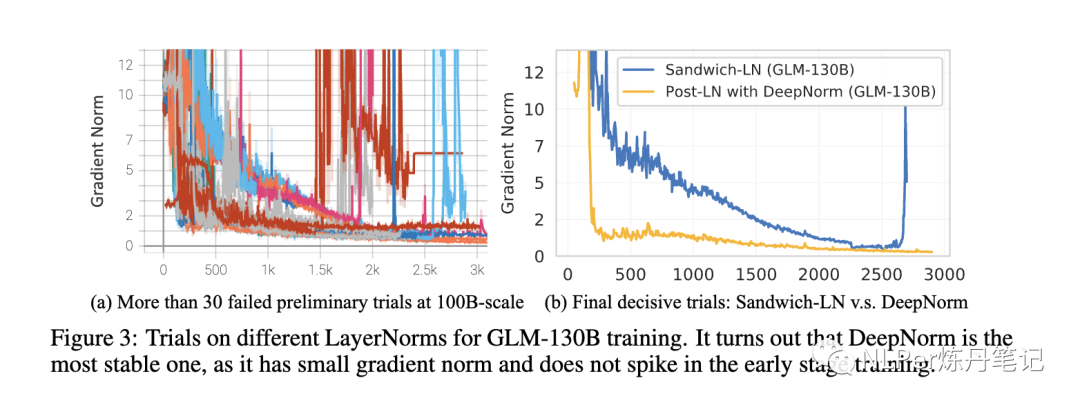
2)Layer Normalization:选用的是DeepNorm(一种Post LN方法)来提升模型训练时候的稳定性。
3)Positional Encoding:旋转位置编码(RoPE)
4)激活函数:GeGLU
2.GLM-130预训练配置
1)自监督空白填充(95% tokens):通过不同的Mask策略,来使模型获得自编码和自回归的能力,具体可参见GLM解读。
2)多任务指令预训练(MIP,5% tokens):T5和ExT5研究表明,预训练中的多任务学习比微调更有帮助。因此,GLM-130B在预训练中包含各项指令数据集,包含语意理解、生成和信息抽取。为了保证模型的其他生成能力不受影响,用于 MIP 训练的数据集只占了 5%。
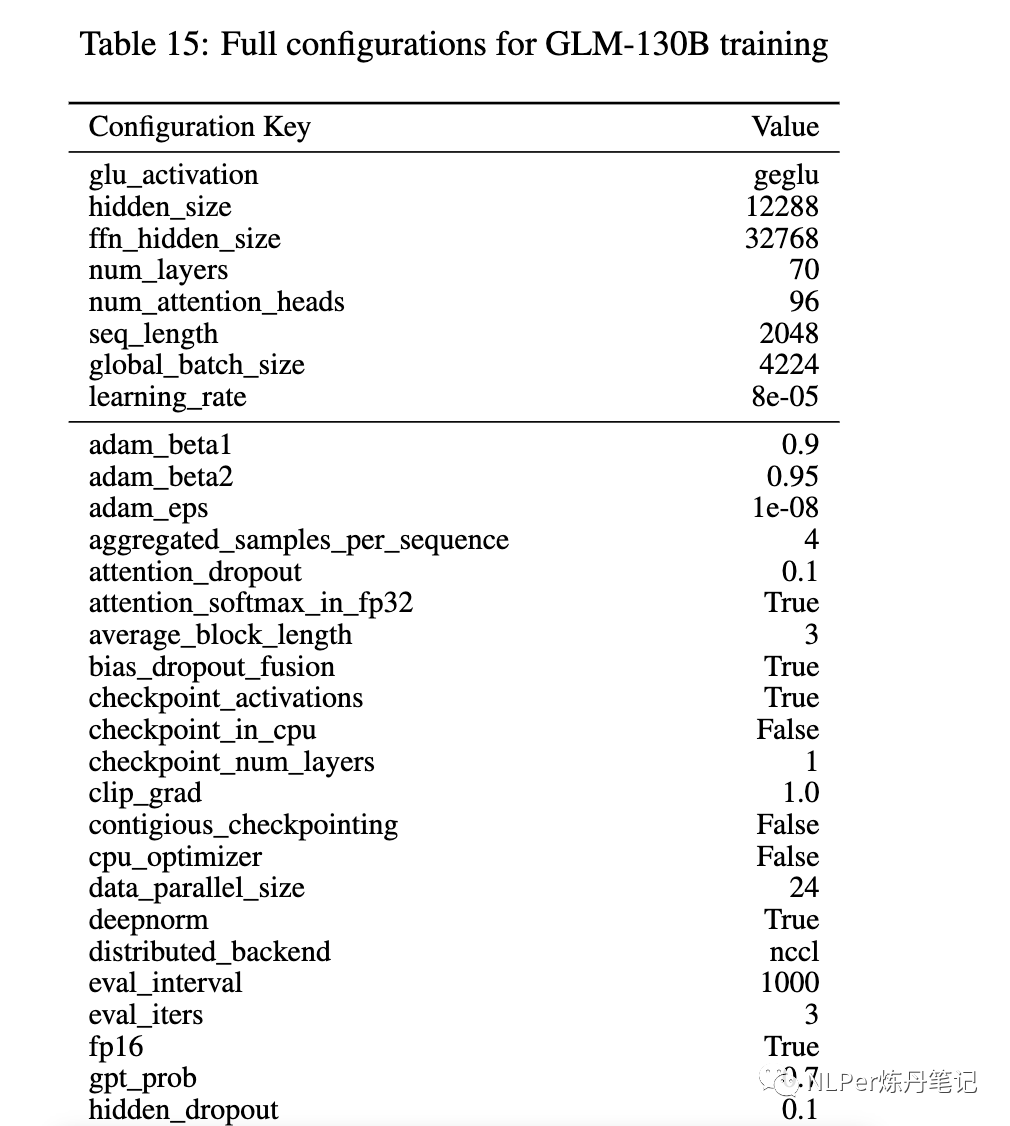
3.平台硬件并行策略和模型配置
1)3个维度上并行:数据并行、tensor 并行、节点并行。
2)GLM-130B配置:截图不全,详见原文
三、GLM-130B训练的稳定性
训练的稳定性是GLM-130B模型质量的决定性因素,这在很大程度上也受token的影响。因此,在计算使用的限制下,对于浮点精度选择,必须在效率和稳定性之间进行权衡:低精度(如FP16)格式会提高效率,但容易出现上溢和下溢的错误,导致训练崩溃。
采用混合精度,在前向传播和后向传播的时候使用FP16,在优化器状态和主权重使用FP32,从而减少GPU内存使用,进而提高训练效率。
嵌入层梯度收缩,根据经验,梯度范式可作为训练崩溃的一个指标。具体来说,训练崩溃通常是滞后于梯度范式的“尖峰”的几个训练步骤。通常这种“尖峰”出现在嵌入层(embedding layer),作者通过缩小嵌入层范式(α=0.1,缩小十倍)来减少“尖峰”的出现,从而提升模型的稳定性。
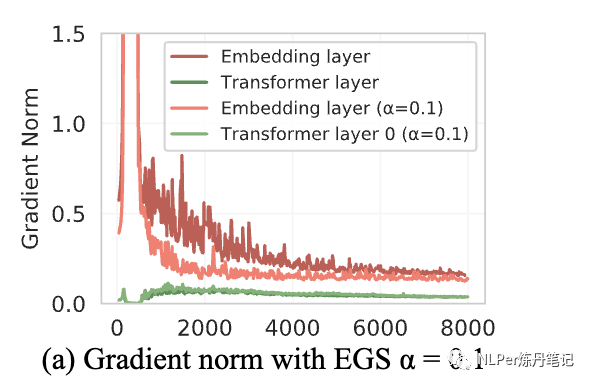
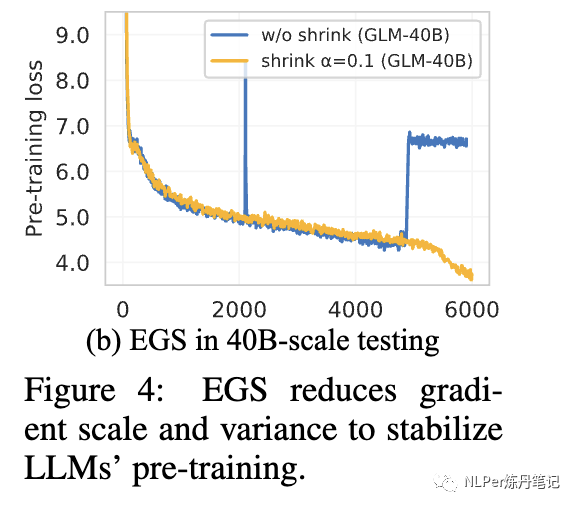
模型稳定性有了明显提高:
四、GLM-130B在RTX2080上的推理
为RTX 3090s/2080s进行INT4量化:下图是量化后的模型效果表现
GLM INT4权重量化规模规律:
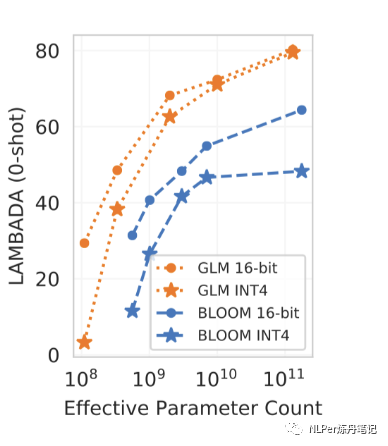
可以看到,随着模型参数量的增加,FP16精度和INT4精度的GLM模型效果相差越来越小,特别是到了千亿参数量的时候,二者之间的差异更小。说明 INT4 量化对模型表现效果的影响很小。
五、结果
在MMLU上面的表现
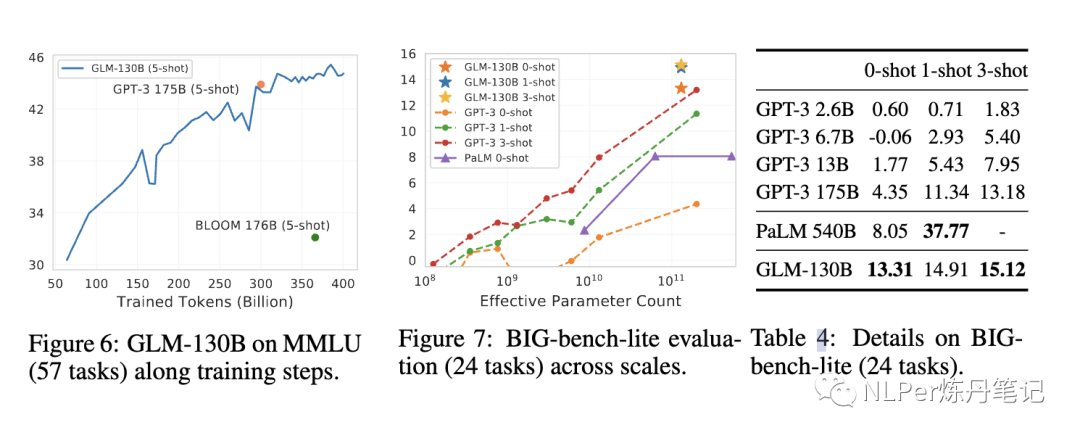
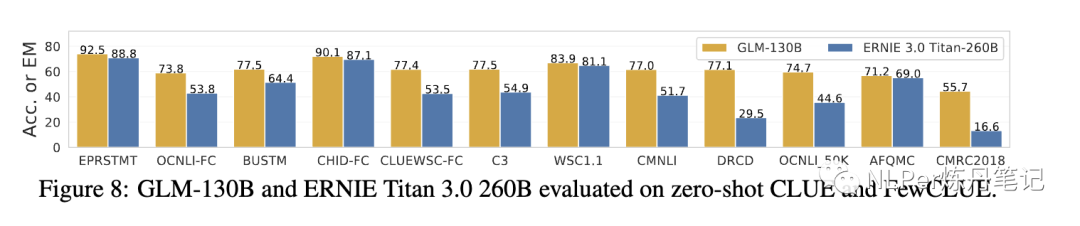
在CLUE(中文评测集)上面的表现:
六、个人总结
这篇论文主要的优化点都是从工程化角度下手,因为要训练千亿级别的模型,工程化能力非常重要,以下是我认为比较重要的一点:
-
通过引入嵌入层梯度收缩(Embedding Layer Gradient Shrink )来提高模型的稳定性。
其他的改进点(也是目前众多LLM的改进方向):模型结构、层标准化(LN)、激活函数、位置编码(PE)。

















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









