







langchain简介
我们可以从官网得到langchain的介绍可以得出langchain的简单介绍

LangChain 是一个用于构建大型语言模型(LLM)的可组合框架。LangGraph 是用于可控的智能体工作流的编排框架。
可以使用 LangGraph 平台大规模部署大语言模型应用程序,Langgraph支持流式编排,Langgraph基础设施专为智能体而构建。
不管有没有使用LangChain 框架,都可以在 LangSmith 中可以调试、协作、测试和监控LLM 应用程序。
而langchain主要产品有三个,分别是 langchain、langgraph和langsmith,可以认为分别映射到 build,run和manage大功能上
langchain架构简述
整个langchain架构图如下
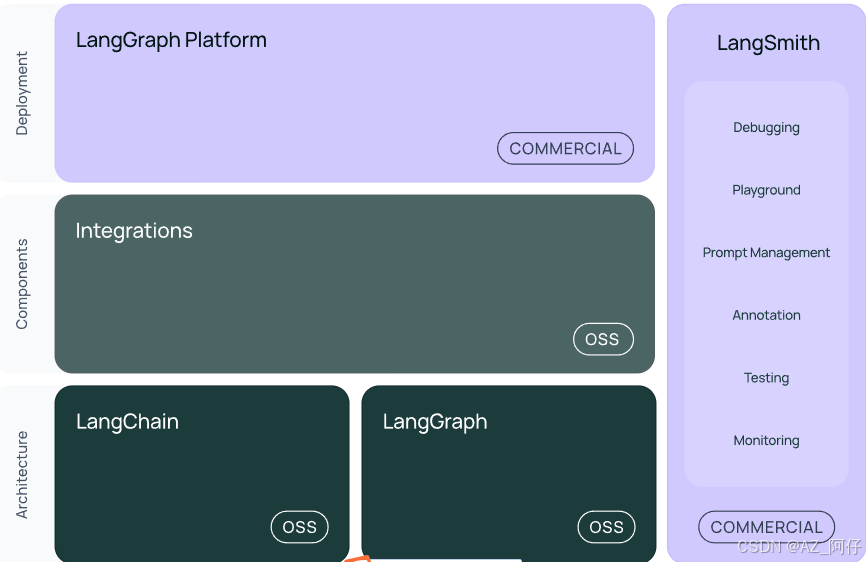
langchain-core
langchain包含不同组件的基本抽象,并且组织了这些基本抽象的组合方式。这里定义了聊天模型、矢量存储、工具等核心组件的接口。第三方集成不在这里定义。依赖关系非常轻量级。
langchain
主 langchain 包,包括构成应用程序认知架构的链和检索策略。不属于第三方集成。这里的所有chain、agent和检索策略被抽象出来。
Integration packages
主流的集成都有自己的包(例如 langchain-openai, langchain-anthropic),利用这种实现可以对包本身进行适当的版本控制和适当的轻量化。
langchain-community
由 LangChain 社区维护的第三方集成,关键的集成包被分离出来,社区包包含各种组件(聊天模型、向量存储、工具等)的集成。此包中的所有依赖项都是可选的,以保持包尽可能轻量化。
langgraph
Langgraph 是 langchain 的扩展,目的是通过将步骤建模为图中的边和节点来使用 LLM 构建健壮且有状态的多参与者应用程序。LangGraph 公开了用于创建常见类型agent的高级接口。
langserve
将应用发布为 RestAPI的组件
LangSmith
调试用
这里需要注意,langchain的接口升级并不是向前兼容的,这一点和以前的java框架有的比较大的区别,意味着每次升级之后,之前的接口可能会发生变化导致代码不可用
Langchain的核心组件
LangChain 的核心组件如下图所示
https://python.langchain.com/docs/integrations/chat/
我们选取其中几个点进行说明
-
模型 I/O 封装
- LLMs:大语言模型,写法变得更简单
- Chat Models:一般基于 LLMs,但按对话结构重新封装,不需要和以前一样写很多的代码
- PromptTemple:提示词模板
- OutputParser:解析输出
-
数据连接封装
我们知道RAG包括文档加载,对文档的操作,例如切割、过滤、向量化、向量存储、向量检索,这里不需要自己手工完成,可以通过下列langchain组建完成
- Document Loaders:各种格式文件的加载器
- Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:文本向量化表示,用于检索等操作(啥意思?别急,后面详细讲)
- Verctorstores: (面向检索的)向量的存储
- Retrievers: 向量的检索
-
对话历史管理
- 对话历史的存储、加载与剪裁
-
架构封装
我们如果要自行完成端对端的功能,经过多个模型调用,使用Chain会变得很简单
-
Chain:实现一个功能或者一系列顺序功能组合
-
Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
-
-
Callbacks
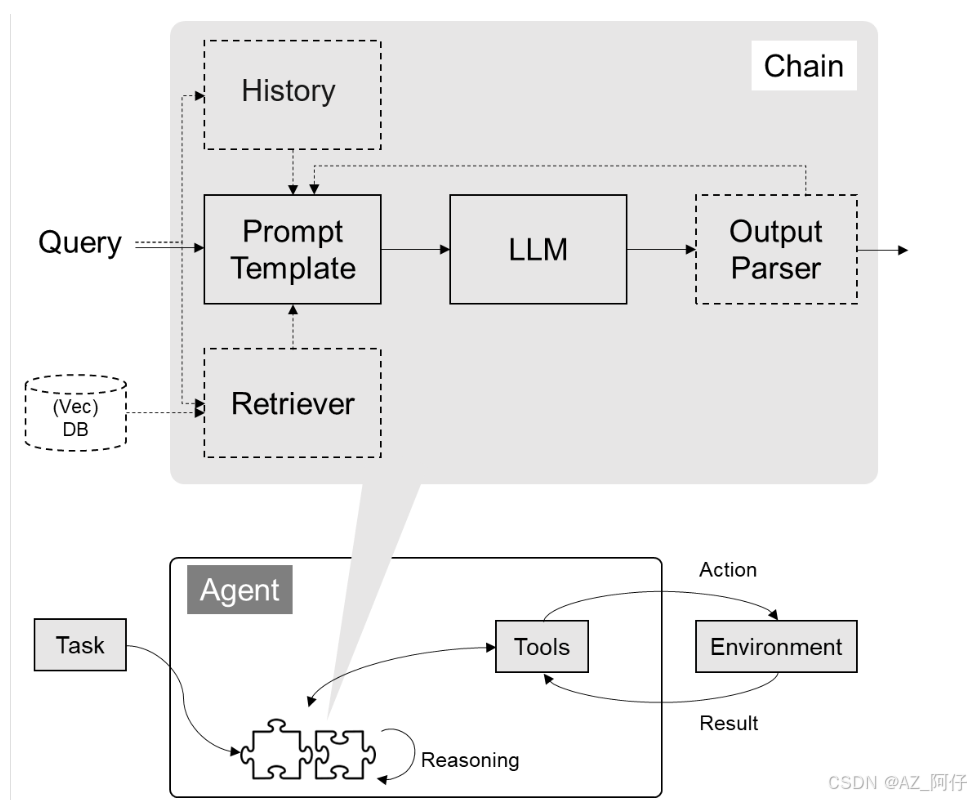
这里可以看到 提示词模版Promt Template 来源有3点,用户提问query,历史对话 History,向量数据数据库 vecdb,提示词模板准备好了之后灌入大模型,最终通过output parse进行结构化输出
组件使用
模型IO封装
OpenAI模型封装
我们可以已通过官网说明进行 chat model 的使用 https://python.langchain.com/docs/integrations/chat/openai/
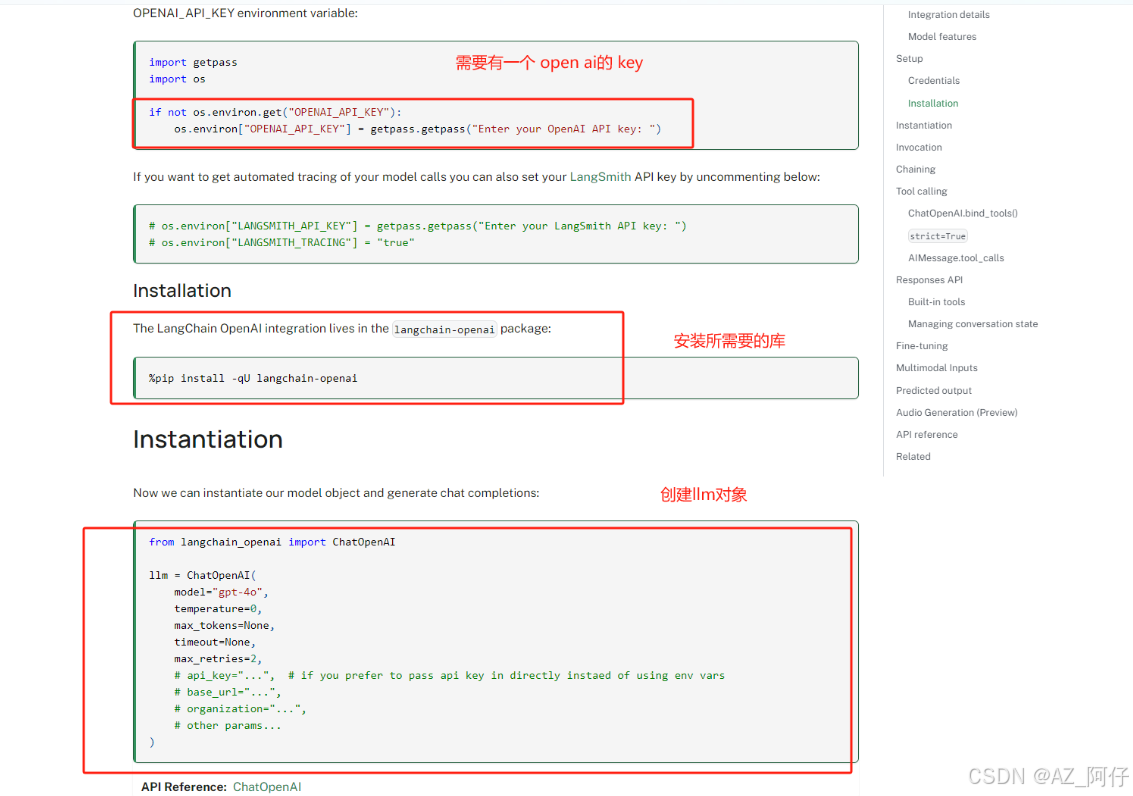
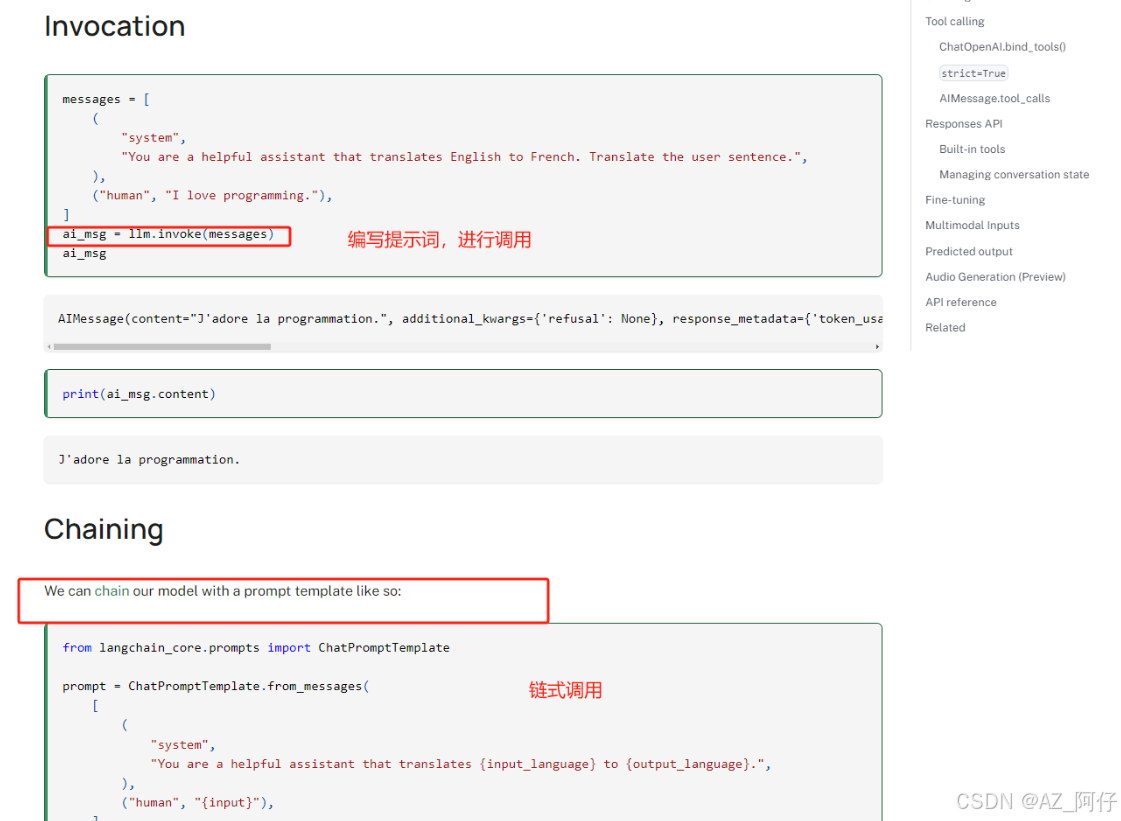
我们也可以自己写一个简单的例子
pip install --upgrade langchain
pip install --upgrade langchain-openai
pip install --upgrade langchain-community
from langchain_openai import ChatOpenAI
# 保证操作系统的环境变量里面配置好了OPENAI_API_KEY, OPENAI_BASE_URL
llm = ChatOpenAI(model="gpt-4o-mini") # 默认是gpt-3.5-turbo
response = llm.invoke("你是谁")
print(response.content)
D:\env\python\langchain_env\python.exe "D:/env/PyCharm 2024.2.1/plugins/python-ce/helpers/pydev/pydevd.py" --multiprocess --qt-support=auto --client 127.0.0.1 --port 60474 --file G:\lession\python_deep_learning\langchain\langchain\chatmodel_test01.py
已连接到 pydev 调试器(内部版本号 242.21829.153)我是一个人工智能助手,旨在回答问题和提供信息。有什么我可以帮助你的吗?
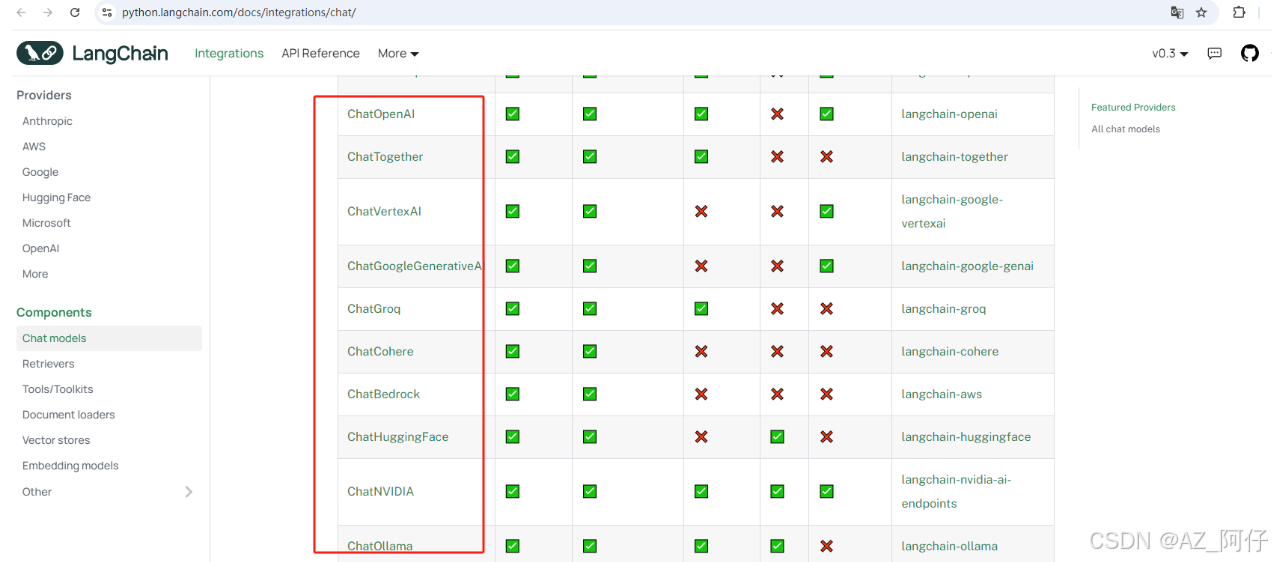
这里我们使用的是 ChatOpenAI中的gpt-4o,如果你要使用其他的模型,需要从模型列表中找到 支持的模型 https://python.langchain.com/docs/integrations/chat/
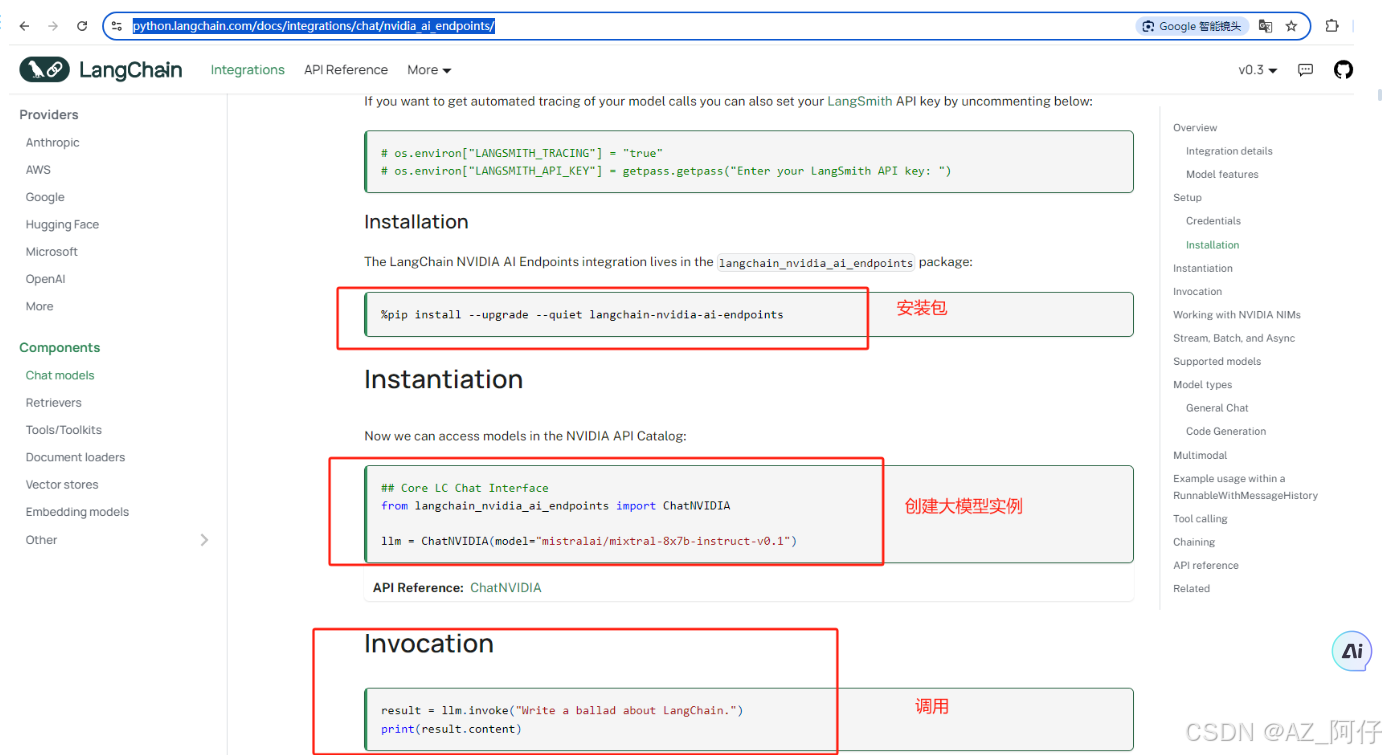
以NVIDIA的模型为例,点及ChatNVDIA,https://python.langchain.com/docs/integrations/chat/nvidia_ai_endpoints/ 看到具体 ChatNVDIA的使用方式
多轮对话session封装
from langchain_openai import ChatOpenAI
# 保证操作系统的环境变量里面配置好了OPENAI_API_KEY, OPENAI_BASE_URL
llm = ChatOpenAI(model="gpt-4o-mini") # 默认是gpt-3.5-turbo
from langchain.schema import (
AIMessage, # 等价于OpenAI接口中的assistant role
HumanMessage, # 等价于OpenAI接口中的user role
SystemMessage # 等价于OpenAI接口中的system role
)
messages = [
SystemMessage(content="你是土鳖桂电的计算机组成原理实验课老师。"), # 描述AI角色
HumanMessage(content="我是学员,我叫阿仔,我的学习能力超强。"), # 描述用户自己
AIMessage(content="欢迎!"),
HumanMessage(content="我可以不用上你的课吗") # 相当于用户输入
]
ret = llm.invoke(messages)
print(ret.content)
D:\env\python\langchain_env\python.exe "D:/env/PyCharm 2024.2.1/plugins/python-ce/helpers/pydev/pydevd.py" --multiprocess --qt-support=auto --client 127.0.0.1 --port 61725 --file G:\lession\python_deep_learning\langchain\langchain\chatmodel_test02.py
已连接到 pydev 调试器(内部版本号 242.21829.153)虽然你学习能力很强,但我的课程内容对理解计算机组成原理是很重要的。如果你有特别的情况或者希望通过其他方式学习,可以和我讨论一下,我们可以一起找到适合你的学习方式。
可以看到我们使用 langchain 定义的 SystemMessage HumanMessage AIMessage 进行提示词封装和提问,可以指定用户和AI的角色,得到更准确的答案
这里我定义用户是叫做阿仔,是一个学员,学习能力很强,而系统的描述是 土鳖桂电的计算机组成原理实验课老师
最终我问系统 我可以不用上你的课吗,得到的答案是 虽然你学习能力很强,但我的课程内容对理解计算机组成原理是很重要的。如果你有特别的情况或者希望通过其他方式学习,可以和我讨论一下,我们可以一起找到适合你的学习方式。
很符合学生问老师的回答。
这里通过大模型的封装,我们可以对使用的大模型进行轻松的替换
模型的输入与输出
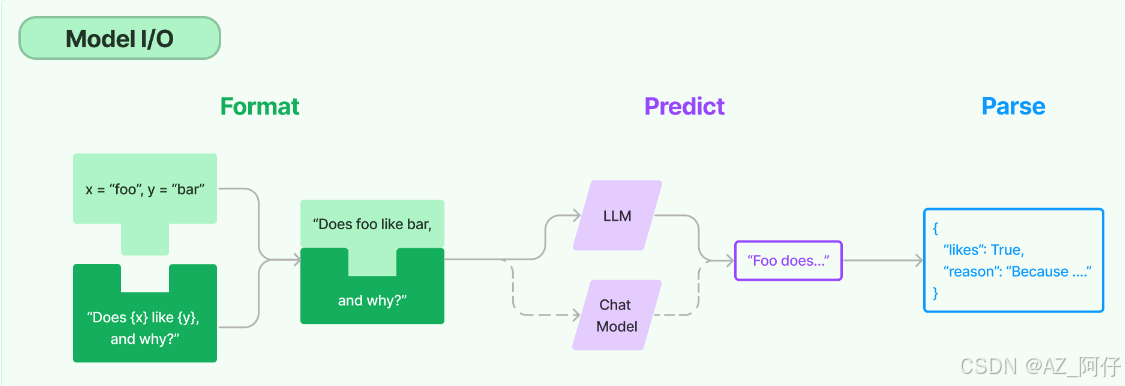
首先我们在 Format阶段给一个输入,可以对输入进行格式化,可以认为是 Predict的前置
Parse指的是对模型的输出进行格式化,也就是模型输出的定制化
和大模型对话的核心是prompt,那么如何对 prompt 进行定制
模版封装
from langchain_openai import ChatOpenAI
subject='阿仔和刘亦菲的爱情故事'
template = PromptTemplate.from_template("给我讲个关于{subject}的故事")
print("===Template===")
print(template)
print("===Prompt===")
print(template.format(subject=subject))
# 定义 LLM
llm = ChatOpenAI(model="gpt-4o-mini")
# 通过 Prompt 调用 LLM
ret = llm.invoke(template.format(subject=subject))
# 打印输出
print(ret.content)
调用结果
===Template===
input_variables=['subject'] input_types={} partial_variables={} template='给我讲个关于{subject}的故事'
===Prompt===
给我讲个关于阿仔和刘亦菲的爱情故事的故事
在一个阳光明媚的城市里,住着一个名叫阿仔的年轻人。他性格开朗,热爱生活,常常骑着单车在城市中悠闲地游荡。阿仔喜欢拍照,特别是那些能捕捉到生活中美好瞬间的照片。他常常到公园、咖啡馆、街市等地方,寻找灵感。
某一天,阿仔在一个小巷子里发现了一位优雅的女孩,她正静静地坐在长椅上,手里拿着一本书,阳光透过树叶洒在她的脸庞上,显得特别迷人。这个女孩竟然是著名演员刘亦菲,她在这里拍摄新电影的场景。虽然阿仔是个普通人,但他并没有被她的明星光环所触动,而是被她那种自然、恬静的气质深深吸引。
阿仔鼓起勇气走上前,轻声问道:“可以给您拍张照片吗?”刘亦菲抬头看了他一眼,微笑着点了点头。阿仔在她的身旁找了个角度,按下快门,记录下了这美丽的瞬间。拍完后,他将手机递给刘亦菲,让她看看效果。她看着照片,赞叹道:“真不错,你很有才华!”
在随后的日子里,阿仔和刘亦菲逐渐建立起了友谊。阿仔会时常带着她去探索城市的角落,品尝各种美食,甚至一起参加一些小型的文化活动。他们分享着彼此的梦想和生活中的点滴,感情也在不知不觉中不断升温。
然而,作为一名公众人物,刘亦菲面临着种种压力和挑战。阿仔有时会看到她眉头紧锁的样子,心中不禁担忧。他决定要做她的避风港,陪伴在她身边,给她支持和勇气。每当刘亦菲遇到困难时,阿仔总能用幽默和温暖的言语让她重新振作。
时光荏苒,阿仔终于鼓起勇气向刘亦菲表达了自己的感情。“我很喜欢你,不仅仅是因为你是明星,更因为你那颗善良的心。”刘亦菲听后,惊讶而又感动,在她的心中,阿仔的真诚早已埋下了爱的种子。
最终,他们两人相互坦白心迹,开始了一段美好的爱情。在彼此的陪伴下,他们经历了生活的酸甜苦辣,收获了幸福与成长。刘亦菲的事业蒸蒸日上,而阿仔则用心经营着自己的摄影事业,记录着他们的点滴生活。
经历了许多风风雨雨后,阿仔与刘亦菲明白,真正的爱情不仅在于浪漫的瞬间,更在于相互的理解与支持。他们携手走过了许多岁月,创造了属于自己的甜蜜故事。
对于openai的模型来说,输入和输出都是会占用token
ChatPromptTemplate 用模板表示的对话上下文
上边用的是 PromptTemplate,我们现在用一个更高级点的 类 ChatPromptTemplate 生成模板表示的对话上下文
我们可以仅仅使用 ChatPromptTemplate
from langchain_core.prompts import ChatPromptTemplate
template = ChatPromptTemplate([
("system", "你是阿仔AI实验室的助手. 你的名字是 {name}."),
("human", "你好,你在弄啥子?"),
("ai", "我很好,谢谢!"),
("human", "{user_input}"),
])
prompt_value = template.invoke(
{
"name": "菲菲",
"user_input": "你叫什么,你是干啥的"
}
)
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 定义 LLM
llm = ChatOpenAI(model="gpt-4o-mini")
# 通过 Prompt 调用 LLM
ret = llm.invoke(prompt_value)
# 打印输出
print(ret.content)
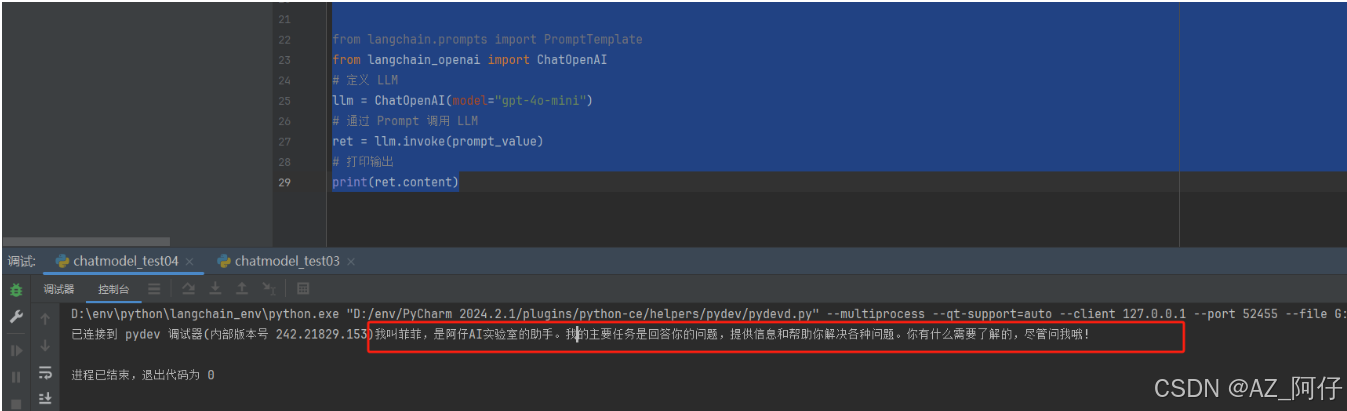
我们写一个简单例子,结合 ChatPromptTemplate HumanMessagePromptTemplate 和 SystemMessagePromptTemplate 完成提示词和大模型的调用
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain_openai import ChatOpenAI
template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是{product}的客服助手。你的名字叫{name}"),
HumanMessagePromptTemplate.from_template("{query}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini")
prompt = template.format_messages(
product="阿仔的AI实验室",
name="菲菲",
query="你是谁,你能干啥?"
)
print(prompt)
ret = llm.invoke(prompt)
print(ret.content)
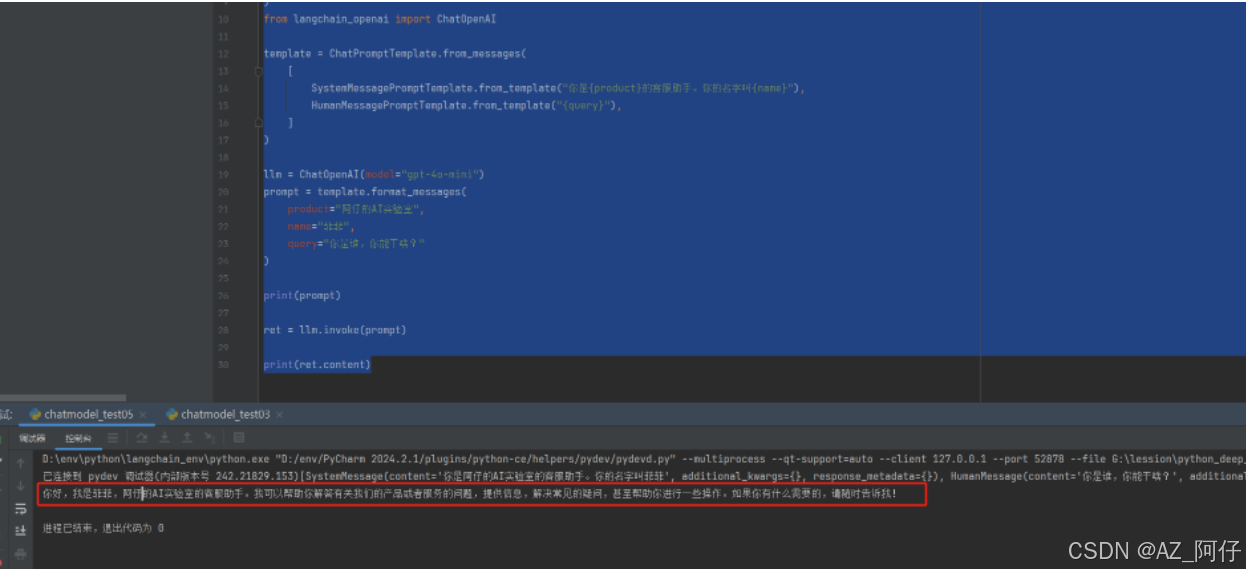
相比只使用 ChatPromptTemplate,同时使用 SystemMessagePromptTemplate 和 HumanMessagePromptTemplate 可以进行进一步抽象
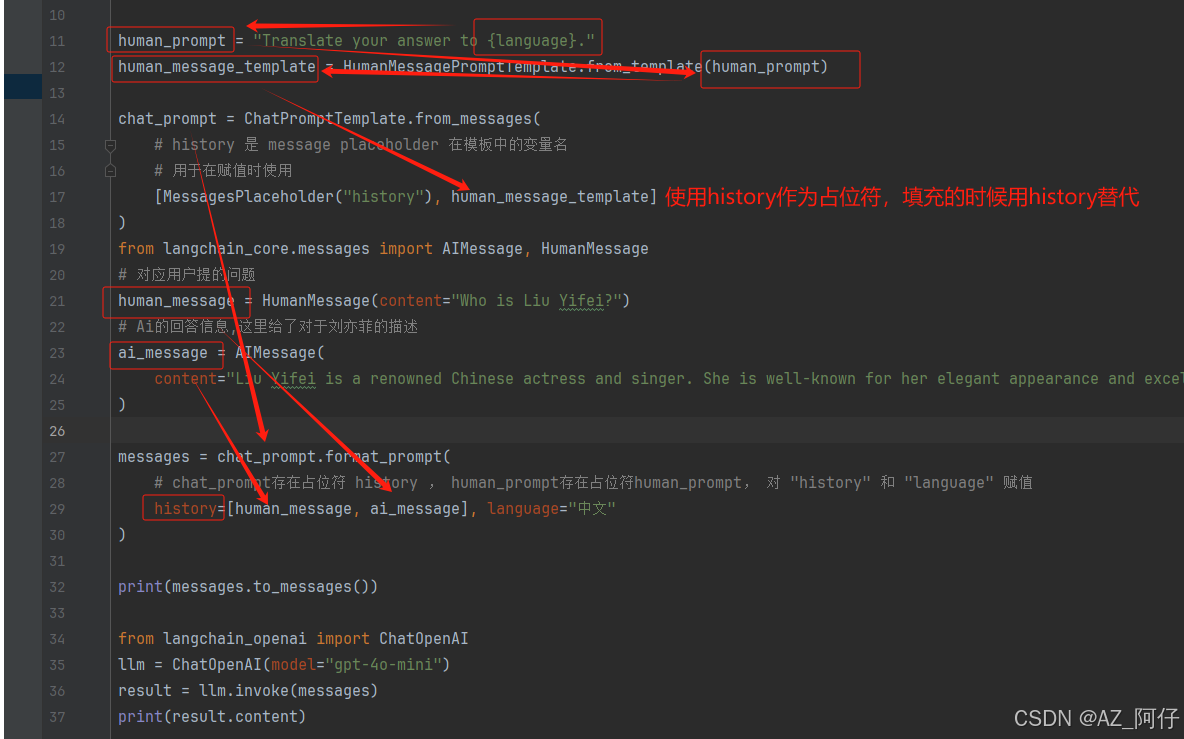
MessagesPlaceholder 把多轮对话变成模板
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
human_prompt = "Translate your answer to {language}."
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
chat_prompt = ChatPromptTemplate.from_messages(
# history 是 message placeholder 在模板中的变量名
# 用于在赋值时使用
[MessagesPlaceholder("history"), human_message_template]
)
from langchain_core.messages import AIMessage, HumanMessage
# 对应用户提的问题
human_message = HumanMessage(content="Who is Liu Yifei?")
# Ai的回答信息,这里给了对于刘亦菲的描述
ai_message = AIMessage(
content="Liu Yifei is a renowned Chinese actress and singer. She is well-known for her elegant appearance and excellent acting skills.She has starred in many popular works. In Chinese dramas, she gained widespread popularity through her roles in \"Chinese Paladin" and "The Return of the Condor Heroes,\" where she played the iconic character Xiao Longnu, leaving a deep impression on the audience. In addition, she has also made a mark in international films, such as playing the lead role in Disney's live-action film \"Mulan,\" which further increased her global influence. With her unique charm and talent, Liu Yifei has a large number of fans both at home and abroad."
)
messages = chat_prompt.format_prompt(
# chat_prompt存在占位符 history , human_prompt存在占位符human_prompt, 对 "history" 和 "language" 赋值
history=[human_message, ai_message], language="中文"
)
print(messages.to_messages())
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
result = llm.invoke(messages)
print(result.content)
输出结果
D:\env\python\langchain_env\python.exe "D:/env/PyCharm 2024.2.1/plugins/python-ce/helpers/pydev/pydevd.py" --multiprocess --qt-support=auto --client 127.0.0.1 --port 54798 --file G:\lession\python_deep_learning\langchain\langchain\chatmodel_test06.py
已连接到 pydev 调试器(内部版本号 242.21829.153)[HumanMessage(content='Who is Liu Yifei?', additional_kwargs={}, response_metadata={}), AIMessage(content='The Return of the Condor Heroes," where she played the iconic character Xiao Longnu, leaving a deep impression on the audience. In addition, she has also made a mark in international films, such as playing the lead role in Disney\'s live-action film "Mulan," which further increased her global influence. With her unique charm and talent, Liu Yifei has a large number of fans both at home and abroad.', additional_kwargs={}, response_metadata={}), HumanMessage(content='Translate your answer to 中文.', additional_kwargs={}, response_metadata={})]
刘亦菲是一位中国演员和歌手,也被称为"神仙姐姐"。她在2004年凭借电视剧《聊斋志异》中的角色入驻观众视野,随即在电视剧《神雕侠侣》中饰演经典角色小龙女,给观众留下了深刻印象。此外,她还在国际电影中崭露头角,如在迪士尼的真人版电影《花木兰》中担任主角,这进一步提升了她的全球影响力。凭借其独特的魅力和才华,刘亦菲在国内外都拥有大量的粉丝。
进程已结束,退出代码为 0
对于提示词模版来说,可以看成是带参数的方法
我们可以看到最终 messages 的结果是
[HumanMessage(content='Who is Liu Yifei?', additional_kwargs={}, response_metadata={}), AIMessage(content='The Return of the Condor Heroes," where she played the iconic character Xiao Longnu, leaving a deep impression on the audience. In addition, she has also made a mark in international films, such as playing the lead role in Disney\'s live-action film "Mulan," which further increased her global influence. With her unique charm and talent, Liu Yifei has a large number of fans both at home and abroad.', additional_kwargs={}, response_metadata={}), HumanMessage(content='Translate your answer to 中文.', additional_kwargs={}, response_metadata={})]
对应的 HumanMessage AIMessage HumanMessage 都填充了指定的 值,最终构成了 大模型需要的完整Prompt
从文件加载Prompt模板
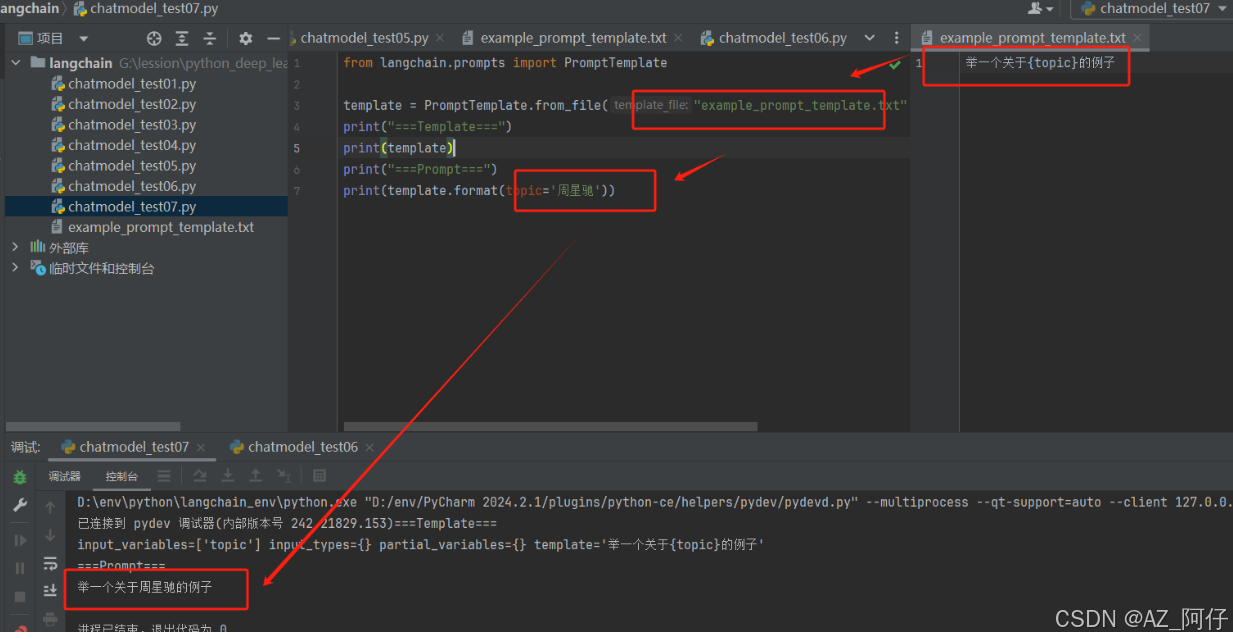
除了上文写死Prompt之外,还可以使用文件加载Prompt,进行到动态提示词替换,这里只是给了一个思路,也可通过远程调用从自定义接口获取,比较灵活
from langchain.prompts import PromptTemplate
template = PromptTemplate.from_file("example_prompt_template.txt", encoding='utf-8')
print("===Template===")
print(template)
print("===Prompt===")
print(template.format(topic='周星驰'))
至此,format部分告一段落
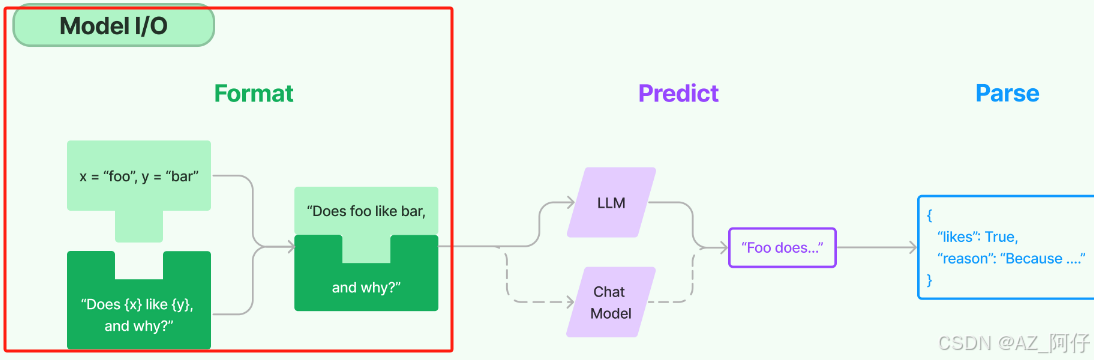
结构化输出
使用pydantic 的BaseModel定义输出对象
from pydantic import BaseModel, Field
# 定义你的输出对象
class Date(BaseModel):
year: int = Field(description="Year")
month: int = Field(description="Month")
day: int = Field(description="Day")
era: str = Field(description="BC or AD")
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
model_name = 'gpt-4o-mini'
temperature = 0
# 定义使用的模型为 gpt-4o-mini,定义文风值为0,即不进行任何随机性处理
llm = ChatOpenAI(model_name=model_name, temperature=temperature)
# 定义结构化输出的模型
structured_llm = llm.with_structured_output(Date)
# 定义提示词模板
template = """提取用户输入中的日期。
用户输入:
{query}"""
prompt = PromptTemplate(
template=template,
)
# 用户输入的日子
query = "我是阿仔,今天是 2025年三月25日天气晴..."
input_prompt = prompt.format_prompt(query=query)
result = structured_llm.invoke(input_prompt)
print(result)
关键代码 是 structured_llm = llm.with_structured_output(Date) ,这句代码制定了llm的输出结构为 Date 所 定义的year、month、day、era
输出结果
year=2025 month=3 day=25 era='AD'
除了定义 类进行格式化,也可以通过指定输出格式的JSON来完成
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
model_name = 'gpt-4o-mini'
temperature = 0
# 定义使用的模型为 gpt-4o-mini,定义文风值为0,即不进行任何随机性处理
llm = ChatOpenAI(model_name=model_name, temperature=temperature)
json_schema = {
"title": "Date",
"description": "Formated date expression",
"type": "object",
"properties": {
"year": {
"type": "integer",
"description": "year, YYYY",
},
"month": {
"type": "integer",
"description": "month, MM",
},
"day": {
"type": "integer",
"description": "day, DD",
},
"era": {
"type": "string",
"description": "BC or AD",
},
},
}
structured_llm = llm.with_structured_output(json_schema)
# 定义提示词模板
template = """提取用户输入中的日期。
用户输入:
{query}"""
prompt = PromptTemplate(
template=template,
)
# 用户输入的日子
query = "我是阿仔,今天是 2025年三月25日天气晴..."
input_prompt = prompt.format_prompt(query=query)
result = structured_llm.invoke(input_prompt)
print(result)
输出结果
{'year': 2025, 'month': 3, 'day': 25, 'era': 'AD'}
我们可以很容易的对比出来,变化的只有格式的指定,其余的代码基本没有任何变化
我们也可以使用 OutputParser指定 输出格式 https://python.langchain.com/v0.2/docs/concepts/#output-parsers
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
model_name = 'gpt-4o-mini'
temperature = 0
# 定义使用的模型为 gpt-4o-mini,定义文风值为0,即不进行任何随机性处理
llm = ChatOpenAI(model_name=model_name, temperature=temperature)
from pydantic import BaseModel, Field
# 定义你的输出对象
class Date(BaseModel):
year: int = Field(description="Year")
month: int = Field(description="Month")
day: int = Field(description="Day")
era: str = Field(description="BC or AD")
parser = JsonOutputParser(pydantic_object=Date)
prompt = PromptTemplate(
template="提取用户输入中的日期。\n用户输入:{query}\n{format_instructions}",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 定义提示词模板
template = """提取用户输入中的日期。
用户输入:
{query}"""
# 用户输入的日子
query = "我是阿仔,今天是 2025年三月25日天气晴..."
input_prompt = prompt.format_prompt(query=query)
result = llm.invoke(input_prompt)
print("原始输出: " + result.content)
print("\n解析后:")
print(parser.invoke(result))
输出结果
原始输出:
```json
{"year": 2025, "month": 3, "day": 25, "era": "AD"}
```
解析后:
{'year': 2025, 'month': 3, 'day': 25, 'era': 'AD'}
funtion call
我们定义两个方法 add,和multiply,将这两个方法使用@tool修饰
from langchain_core.tools import tool
@tool
def add(a: int, b: int) -> int:
"""Add two integers.
Args:
a: First integer
b: Second integer
"""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two integers.
Args:
a: First integer
b: Second integer
"""
return a * b
import json
# 将两个tool绑定到大模型llm上,用于增加llm的能力
llm_with_tools = llm.bind_tools([add, multiply])
query = "3的4倍是多少?"
# 生成一个输入提示词
messages = [HumanMessage(query)]
# 调用提示词
output = llm_with_tools.invoke(messages)
# 打印输出
print(json.dumps(output.tool_calls, indent=4))
输出结果
[
{
# llm理解了语义后应该调用 multiply
"name": "multiply",
# 入参
"args": {
"a": 7,
"b": 8
},
"id": "call_DWAQ12mKKLQWtCeW7HeVrHtq",
# 类型是 tool_call 的调用
"type": "tool_call"
}
]
如果需要将目前公司现有的业务结合起来,可以@tool 封装一个调用外部接口的方法,然后将这个封装的回调方法给到大模型。
在此基础上打印function call, 并以function call的message作为调用大模型的入参
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
model_name = 'gpt-4o-mini'
temperature = 0
# 定义使用的模型为 gpt-4o-mini,定义文风值为0,即不进行任何随机性处理
llm = ChatOpenAI(model_name=model_name, temperature=temperature)
@tool
def add(a: int, b: int) -> int:
"""Add two integers.
Args:
a: First integer
b: Second integer
"""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two integers.
Args:
a: First integer
b: Second integer
"""
return a * b
import json
# 将两个tool绑定到大模型llm上,用于增加llm的能力
llm_with_tools = llm.bind_tools([add, multiply])
query = "7的8倍是多少?"
# 生成一个输入提示词
messages = [HumanMessage(query)]
# 调用提示词
output = llm_with_tools.invoke(messages)
# 打印输出
print(json.dumps(output.tool_calls, indent=4))
# 回传 Funtion Call 的结果
messages.append(output)
available_tools = {"add": add, "multiply": multiply}
# 将 output的tool_calls 转换为消息,并添加到messages中
for tool_call in output.tool_calls:
selected_tool = available_tools[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call)
messages.append(tool_msg)
print(messages)
# 以message作为输入,调用llm_with_tools
new_output = llm_with_tools.invoke(messages)
for message in messages:
print(json.dumps(message.dict(), indent=4, ensure_ascii=False))
print(new_output.content)
调试结果如下
[
{
"name": "multiply",
"args": {
"a": 7,
"b": 8
},
"id": "call_NVtq1fBKkkddAvtl1P2lL3ct",
"type": "tool_call"
}
]
[HumanMessage(content='7的8倍是多少?', additional_kwargs={}, response_metadata={}), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_NVtq1fBKkkddAvtl1P2lL3ct', 'function': {'arguments': '{"a":7,"b":8}', 'name': 'multiply'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 97, 'total_tokens': 115, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_b8bc95a0ac', 'id': 'chatcmpl-BEyfJ2Bx7z8B2SBEIQOlfj0aNgWIo', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-130b2ba0-57b7-4de4-a86f-6f0ce1ffbc52-0', tool_calls=[{'name': 'multiply', 'args': {'a': 7, 'b': 8}, 'id': 'call_NVtq1fBKkkddAvtl1P2lL3ct', 'type': 'tool_call'}], usage_metadata={'input_tokens': 97, 'output_tokens': 18, 'total_tokens': 115, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), ToolMessage(content='56', name='multiply', tool_call_id='call_NVtq1fBKkkddAvtl1P2lL3ct')]
G:\lession\python_deep_learning\langchain\langchain\chatmodel_test10.py:65: PydanticDeprecatedSince20:
The `dict` method is deprecated; use `model_dump` instead. Deprecated in Pydantic V2.0 to be removed in V3.0. See Pydantic V2 Migration Guide at https://errors.pydantic.dev/2.10/migration/
{
"content": "7的8倍是多少?",
"additional_kwargs": {},
"response_metadata": {},
"type": "human",
"name": null,
"id": null,
"example": false
}
{
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"id": "call_NVtq1fBKkkddAvtl1P2lL3ct",
"function": {
"arguments": "{\"a\":7,\"b\":8}",
"name": "multiply"
},
"type": "function"
}
],
"refusal": null
},
"response_metadata": {
"token_usage": {
"completion_tokens": 18,
"prompt_tokens": 97,
"total_tokens": 115,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": 0,
"reasoning_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
},
"model_name": "gpt-4o-mini-2024-07-18",
"system_fingerprint": "fp_b8bc95a0ac",
"id": "chatcmpl-BEyfJ2Bx7z8B2SBEIQOlfj0aNgWIo",
"finish_reason": "tool_calls",
"logprobs": null
},
"type": "ai",
"name": null,
"id": "run-130b2ba0-57b7-4de4-a86f-6f0ce1ffbc52-0",
"example": false,
"tool_calls": [
{
"name": "multiply",
"args": {
"a": 7,
"b": 8
},
"id": "call_NVtq1fBKkkddAvtl1P2lL3ct",
"type": "tool_call"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 97,
"output_tokens": 18,
"total_tokens": 115,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 0
}
}
}
{
"content": "56",
"additional_kwargs": {},
"response_metadata": {},
"type": "tool",
"name": "multiply",
"id": null,
"tool_call_id": "call_NVtq1fBKkkddAvtl1P2lL3ct",
"artifact": null,
"status": "success"
}
7的8倍是56。
我们得到的结果 7的8倍是56。 还是比较精准
function call 是大语言模型(LLM)的函数调用原理是在语言模型(这里是python)的基础上,通过特定的机制使模型能够理解并执行外部函数的调用请求,以扩展其功能和应用场景。
本质上是违背大模型端对端的模式,但是企业内并不能完全通过数据投喂到大模型,所以通过function call 反向调用的方式调用外部接口增强大模型能力。
LLM bindtools的基本原理如下:
- 1. LLM 首先需要对输入的自然语言进行理解和解析,识别出其中可能包含的函数调用意图。例如,当用户输入 “7的8倍是多少? 时,模型需要理解这是算数请求,并能够提取出关键信息,如计算方式是乘法,乘数与被乘数为 8和7。
- 2. 模型通过预训练和微调,学习到不同自然语言表述与特定函数调用之间的映射关系。它会将识别出的意图与内部的函数目录或知识库进行匹配,确定需要调用的具体函数。在上述例子中,模型会将 “7的8倍是多少” 的意图映射到multiply函数。
- 3. 一旦确定了要调用的函数,LLM 会从输入文本中提取出函数所需的参数,并将其格式化为函数能够接受的形式。对于 multiply ,需要将 7的8倍转化为 7X8。
- 4.LLM 通过特定的接口或中间件与外部的函数执行系统进行通信。它将格式化后的函数调用请求发送给外部系统,等待外部系统执行函数并返回结果。例如以7和8作为入参调用 multiply,并等待 multiply 返回的结果。
- 5. 当 LLM 接收到外部系统返回的函数执行结果后,它需要对结果进行解析和整合。如果返回的是原始的值56,模型需要将其转换为自然语言描述,以便用户能够理解。
- 6. LLM 根据结果和上下文信息,生成一个完整的、自然流畅的回复,回答用户的问题。回复不仅要包含函数执行的结果,还可以根据需要提供一些额外的信息或解释,以满足用户的需求。所以随后的答案是 7的8倍是56。
小结
- LangChain 统一封装了各种模型的调用接口,包括补全型和对话型两种
- LangChain 提供了 PromptTemplate 类,可以自定义带变量的模板
- LangChain 提供了一些列输出解析器,用于将大模型的输出解析成结构化对象
- LangChain 提供了 Function Calling 的封装
- 上述模型属于 LangChain 中较为实用的部分
关于数据连接封装
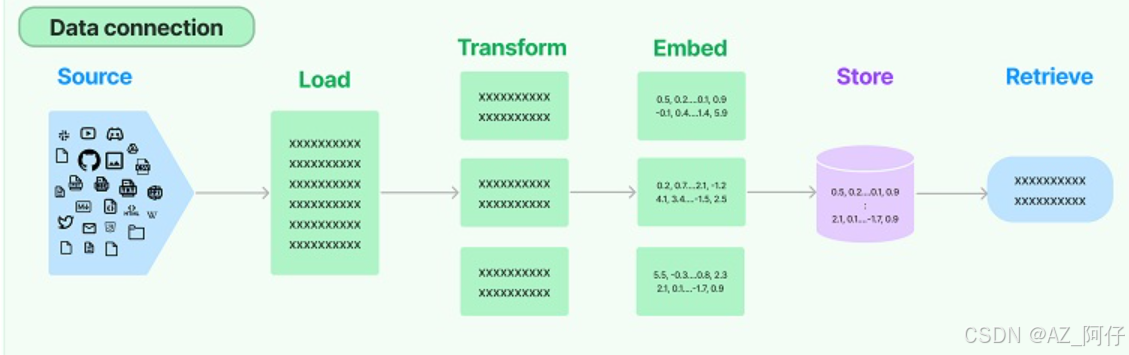
实际上,这是对于rag做的解析
rag原始语料 加载(load)到内存,然后做转换(transform)和词向量编码(embed),然后存储(store)到数据库,最后让数据被检索(retrieve)
从加载文档开始
文档加载
# 读取pdf
pip install pymupdf
# 文档切割用
pip install --upgrade langchain-text-splitters
# 安装向量数据库 faiss 的 cpu版本 其他的向量存储可以参考 https://python.langchain.com/v0.3/docs/integrations/vectorstores/
conda install -c pytorch faiss-cpu
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载文档
loader = PyMuPDFLoader("llama2.pdf")
# 加载分割
pages = loader.load_and_split()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
# pages 前4页
texts = text_splitter.create_documents(
[page.page_content for page in pages[:4]]
)
# 灌库 默认使用的也是 text-embedding-ada-002
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(texts, embeddings)
# 检索 top-3 结果
retriever = db.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke("llama2有多少参数")
for doc in docs:
print(doc.page_content)
print("----")
运行结果如下
but are not releasing.§
2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release
variants of this model with 7B, 13B, and 70B parameters as well.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs,
----
Llama 2-Chat, at scales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested,
Llama 2-Chat models generally perform better than existing open-source models. They also appear to
----
large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.
Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our
models outperform open-source chat models on most benchmarks we tested, and based on
当前的方案有一些问题,只能识别简单的PDF文本,并切割,如果有图片和表格,暂时不支持
历史管理
历史记录的裁剪
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
trim_messages,
)
from langchain_openai import ChatOpenAI
messages = [
SystemMessage("you're a good assistant, you always respond with a joke."),
HumanMessage("i wonder why it's called langchain"),
AIMessage(
'Well, I guess they thought "WordRope" and "SentenceString" just didn\'t have the same ring to it!'
),
HumanMessage("and who is harrison chasing anyways"),
AIMessage(
"Hmmm let me think.\n\nWhy, he's probably chasing after the last cup of coffee in the office!"
),
HumanMessage("what do you call a speechless parrot"),
]
trim_messages(
messages,
max_tokens=45,
strategy="last",
token_counter=ChatOpenAI(model="gpt-4o-mini"),
)
运行结果如下
[AIMessage(content="Hmmm let me think.\n\nWhy, he's probably chasing after the last cup of coffee in the office!", additional_kwargs={}, response_metadata={}),
HumanMessage(content='what do you call a speechless parrot', additional_kwargs={}, response_metadata={})]
保留systemPrompt
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
trim_messages,
)
from langchain_openai import ChatOpenAI
messages = [
SystemMessage("you're a good assistant, you always respond with a joke."),
HumanMessage("i wonder why it's called langchain"),
AIMessage(
'Well, I guess they thought "WordRope" and "SentenceString" just didn\'t have the same ring to it!'
),
HumanMessage("and who is harrison chasing anyways"),
AIMessage(
"Hmmm let me think.\n\nWhy, he's probably chasing after the last cup of coffee in the office!"
),
HumanMessage("what do you call a speechless parrot"),
]
# 保留 system prompt
trim_messages(
messages,
max_tokens=45,
strategy="last",
token_counter=ChatOpenAI(model="gpt-4o-mini"),
include_system=True,
allow_partial=True,
)
运行结果
[SystemMessage(content="you're a good assistant, you always respond with a joke.", additional_kwargs={}, response_metadata={}),
HumanMessage(content='what do you call a speechless parrot', additional_kwargs={}, response_metadata={})]
过滤带标识的历史记录
过滤,Prompt,剩下 带 消息类型为 human的 Prompt
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
filter_messages,
)
messages = [
SystemMessage("you are a good assistant", id="1"),
HumanMessage("example input", id="2", name="example_user"),
AIMessage("example output", id="3", name="example_assistant"),
HumanMessage("real input", id="4", name="bob"),
AIMessage("real output", id="5", name="alice"),
]
# 过滤,Prompt,剩下 带 消息类型为 human的 Prompt
filter_messages(messages, include_types="human")
运行结果
[HumanMessage(content='example input', additional_kwargs={}, response_metadata={}, name='example_user', id='2'),
HumanMessage(content='real input', additional_kwargs={}, response_metadata={}, name='bob', id='4')]
过滤,Prompt,剩下 带 name 为 example_user 和 的 example_assistant Prompt
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
filter_messages,
)
messages = [
SystemMessage("you are a good assistant", id="1"),
HumanMessage("example input", id="2", name="example_user"),
AIMessage("example output", id="3", name="example_assistant"),
HumanMessage("real input", id="4", name="bob"),
AIMessage("real output", id="5", name="alice"),
]
# 过滤,Prompt,剩下 带 name 为 example_user 和 的 example_assistant Prompt
filter_messages(messages, exclude_names=["example_user", "example_assistant"])
运行结果
[SystemMessage(content='you are a good assistant', additional_kwargs={}, response_metadata={}, id='1'),
HumanMessage(content='real input', additional_kwargs={}, response_metadata={}, name='bob', id='4'),
AIMessage(content='real output', additional_kwargs={}, response_metadata={}, name='alice', id='5')]
过滤 Prompt,剩下 类型为 HumanMessage, AIMessage,并且 不要 id为3的
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
filter_messages,
)
messages = [
SystemMessage("you are a good assistant", id="1"),
HumanMessage("example input", id="2", name="example_user"),
AIMessage("example output", id="3", name="example_assistant"),
HumanMessage("real input", id="4", name="bob"),
AIMessage("real output", id="5", name="alice"),
]
# 过滤,Prompt,剩下 带 name 为 example_user 和 的 example_assistant Prompt
filter_messages(messages, include_types=[HumanMessage, AIMessage], exclude_ids=["3"])
运行
[HumanMessage(content='example input', additional_kwargs={}, response_metadata={}, name='example_user', id='2'),
HumanMessage(content='real input', additional_kwargs={}, response_metadata={}, name='bob', id='4'),
AIMessage(content='real output', additional_kwargs={}, response_metadata={}, name='alice', id='5')]
Chain 和 LangChain Expression Language (LCEL)
什么是LCEL
LangChain Expression Language(LCEL)是一种声明式语言,可轻松组合不同的调用顺序构成 Chain。LCEL 自创立之初就被设计为能够支持将原型投入生产环境,无需代码更改,从最简单的“提示+LLM”链到最复杂的链(已有用户成功在生产环境中运行包含数百个步骤的 LCEL Chain)。
- LCEL 的核心特点是能够将多个简单的操作组合成复杂的任务, 例如,可以将文本生成、问答、文本分类等不同的语言模型操作通过 LCEL 表达式组合在一起,实现更高级的功能。
- 它提供了丰富的操作符和函数,允许开发者根据具体需求灵活地构建表达式。开发者可以根据输入文本的内容、模型的输出结果以及各种条件来动态地调整任务的执行流程。
- LCEL 表达式具有一定的可读性,使得开发者能够清晰地理解任务的逻辑结构。同时,它也便于代码的维护和修改,当需要对任务进行调整或扩展时,可以方便地在表达式中进行修改。
LCEL应用场景
- 在开发自然语言处理应用时,经常需要将多个语言模型操作组合起来完成复杂的任务。例如,先对输入文本进行分类,然后根据分类结果调用不同的模型进行进一步的处理,LCEL 可以方便地实现这种复杂的任务流程。
- 根据用户输入或其他外部条件动态地调整任务的执行方式。例如,根据用户输入的关键词选择不同的提示模板,或者根据模型的输出结果决定是否进行进一步的细化处理,LCEL 能够灵活地实现这些动态调整。
- LCEL 可以与 LangChain 中的其他组件以及其他相关的自然语言处理框架进行集成,从而更好地发挥其作用。例如,与 LangChain 的提示模板、模型接口等组件结合,实现更高效的语言模型应用开发。
LCEL特点
-
流支持:使用 LCEL 构建 Chain 时,你可以获得最佳的首个令牌时间(即从输出开始到首批输出生成的时间)。对于某些 Chain,这意味着可以直接从 LLM 流式传输令牌到流输出解析器,从而以与 LLM 提供商输出原始令牌相同的速率获得解析后的、增量的输出。
-
异步支持:任何使用 LCEL 构建的链条都可以通过同步 API(例如,在 Jupyter 笔记本中进行原型设计时)和异步 API(例如,在 LangServe 服务器中)调用。这使得相同的代码可用于原型设计和生产环境,具有出色的性能,并能够在同一服务器中处理多个并发请求。
-
优化的并行执行:当你的 LCEL 链条有可以并行执行的步骤时(例如,从多个检索器中获取文档),我们会自动执行,无论是在同步还是异步接口中,以实现最小的延迟。
-
重试和回退:为 LCEL 链的任何部分配置重试和回退。这是使链在规模上更可靠的绝佳方式。目前我们正在添加重试/回退的流媒体支持,因此你可以在不增加任何延迟成本的情况下获得增加的可靠性。
-
访问中间结果:对于更复杂的链条,访问在最终输出产生之前的中间步骤的结果通常非常有用。这可以用于让最终用户知道正在发生一些事情,甚至仅用于调试链条。你可以流式传输中间结果,并且在每个 LangServe 服务器上都可用。
-
输入和输出模式:输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和 JSONSchema 模式。这可以用于输入和输出的验证,是 LangServe 的一个组成部分。
-
无缝 LangSmith 跟踪集成:随着链条变得越来越复杂,理解每一步发生了什么变得越来越重要。通过 LCEL,所有步骤都自动记录到 LangSmith,以实现最大的可观察性和可调试性。
-
无缝 LangServe 部署集成:任何使用 LCEL 创建的链都可以轻松地使用 LangServe 进行部署。
pipeline 式调用 PromptTemplate, LLM 和 OutputParser
写一个简单的例子,使用 pipeline调用方式
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from pydantic import BaseModel, Field, validator
from typing import List, Dict, Optional
from enum import Enum
import json
# 输出结构
class SortEnum(str, Enum):
data = 'data'
price = 'price'
class OrderingEnum(str, Enum):
ascend = 'ascend'
descend = 'descend'
class Semantics(BaseModel):
name: Optional[str] = Field(description="流量包名称", default=None)
price_lower: Optional[int] = Field(description="价格下限", default=None)
price_upper: Optional[int] = Field(description="价格上限", default=None)
data_lower: Optional[int] = Field(description="流量下限", default=None)
data_upper: Optional[int] = Field(description="流量上限", default=None)
sort_by: Optional[SortEnum] = Field(description="按价格或流量排序", default=None)
ordering: Optional[OrderingEnum] = Field(description="升序或降序排列", default=None)
# Prompt 模板
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个语义解析器。你的任务是将用户的输入解析成JSON表示。不要回答用户的问题。"),
("human", "{text}"),
]
)
# 模型
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm = llm.with_structured_output(Semantics)
# LCEL 表达式
runnable = (
{"text": RunnablePassthrough()} | prompt | structured_llm
)
# 直接运行
ret = runnable.invoke("不超过100元的流量大的套餐有哪些")
print(
json.dumps(
ret.dict(),
indent = 4,
ensure_ascii=False
)
)
输出结果
{
"name": null,
"price_lower": null,
"price_upper": 100,
"data_lower": null,
"data_upper": null,
"sort_by": "data",
"ordering": "descend"
}
这里我们关注
# LCEL 表达式
runnable = (
{"text": RunnablePassthrough()} | prompt | structured_llm
)
我们将 提示词模板 prompt 的 text 字段复制 为 RunnablePassthrough() 得到的输出作为 prompt 的 输入
那么 prompt 即
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个语义解析器。你的任务是将用户的输入解析成JSON表示。不要回答用户的问题。"),
("human", RunnablePassthrough()),
]
)
再将 prompt 的结果 作为 structured_llm 的输入,最终通过如下代码运行 pipeline
# 直接运行
ret = runnable.invoke("不超过100元的流量大的套餐有哪些")
得到结果如下
{
"name": null,
"price_lower": null,
"price_upper": 100,
"data_lower": null,
"data_upper": null,
"sort_by": "data",
"ordering": "descend"
}
代码实现非常优雅,如果需要的功能又是 structured_llm 的 输出,那么可以继续使用pipeline的方式接下去,例如outputparser,我们以stream流式输出为例
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from pydantic import BaseModel, Field, validator
from typing import List, Dict, Optional
from enum import Enum
import json
prompt = PromptTemplate.from_template("讲个关于{topic}的故事")
runnable = (
{"topic": RunnablePassthrough()} | prompt | llm | StrOutputParser()
)
# 流式输出
for s in runnable.stream("海尔兄弟"):
print(s, end="", flush=True)
用 LCEL 实现 RAG
加载文档->文档切分->词向量编码->数据入库->检索
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.document_loaders import PyMuPDFLoader
# 加载文档
loader = PyMuPDFLoader("llama2.pdf")
pages = loader.load_and_split()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents(
[page.page_content for page in pages[:4]]
)
# 灌库
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(texts, embeddings)
# 检索 top-2 结果
retriever = db.as_retriever(search_kwargs={"k": 2})
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
# Prompt模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# Chain
rag_chain = (
{"question": RunnablePassthrough(), "context": retriever}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("Llama 2有多少参数")
运行结果
'根据提供的上下文,Llama 2 有 7B(70亿)、13B(130亿)和 70B(700亿)参数的不同版本。'
从这里看出,通过lcel进行rag,代码量少,且代码优雅,通过pipeline也非常容易控制功能
用 LCEL 实现工厂模式
有如下需求,在流程不变的情况下需要测试不同的模型表现,有三个模型可选 Qianfan、gpt 和qwen ,这里通过LCEL工厂模式实现
from langchain_core.runnables.utils import ConfigurableField
from langchain_openai import ChatOpenAI
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_community.chat_models import ChatQwen
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import HumanMessage
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import os
# 模型1:百度千帆 ERNIE 模型
ernie_model = QianfanChatEndpoint(
qianfan_ak=os.getenv('ERNIE_CLIENT_ID'),
qianfan_sk=os.getenv('ERNIE_CLIENT_SECRET')
)
# 模型2:OpenAI GPT 模型
gpt_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 模型3:Qwen1.5 - 1.8B 模型
qwen_model = ChatQwen(
endpoint_url=os.getenv('QWEN_ENDPOINT_URL'),
access_key_id=os.getenv('QWEN_ACCESS_KEY_ID'),
access_key_secret=os.getenv('QWEN_ACCESS_KEY_SECRET'),
model_name="qwen-1.5-1.8b"
)
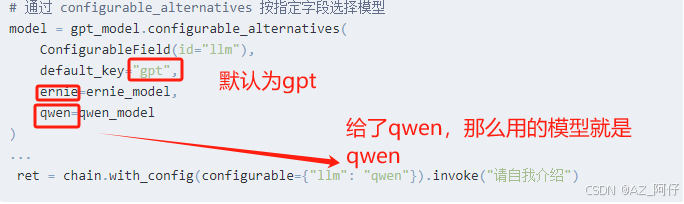
# 通过 configurable_alternatives 按指定字段选择模型
model = gpt_model.configurable_alternatives(
ConfigurableField(id="llm"),
default_key="gpt",
ernie=ernie_model,
qwen=qwen_model
)
# Prompt 模板
prompt = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate.from_template("{query}"),
]
)
# LCEL
chain = (
{"query": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# 运行时指定模型 "gpt" or "ernie" or "qwen"
try:
ret = chain.with_config(configurable={"llm": "qwen"}).invoke("请自我介绍")
print(ret)
except Exception as e:
print(f"运行时出错: {e}")
重点关注
# 通过 configurable_alternatives 按指定字段选择模型
model = gpt_model.configurable_alternatives(
ConfigurableField(id="llm"),
default_key="gpt",
ernie=ernie_model,
qwen=qwen_model
)
...
ret = chain.with_config(configurable={"llm": "qwen"}).invoke("请自我介绍")
这里 configurable_alternatives 的key 指的就是
实际上,这是对于rag做的解析
rag原始语料 加载(load)到内存,然后做转换(transform)和词向量编码(embed),然后存储(store)到数据库,最后让数据被检索(retrieve)
从加载文档开始
文档加载
# 读取pdf
pip install pymupdf
# 文档切割用
pip install --upgrade langchain-text-splitters
# 安装向量数据库 faiss 的 cpu版本 其他的向量存储可以参考 https://python.langchain.com/v0.3/docs/integrations/vectorstores/
conda install -c pytorch faiss-cpu
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载文档
loader = PyMuPDFLoader("llama2.pdf")
# 加载分割
pages = loader.load_and_split()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
# pages 前4页
texts = text_splitter.create_documents(
[page.page_content for page in pages[:4]]
)
# 灌库 默认使用的也是 text-embedding-ada-002
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(texts, embeddings)
# 检索 top-3 结果
retriever = db.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke("llama2有多少参数")
for doc in docs:
print(doc.page_content)
print("----")
运行结果如下
but are not releasing.§
2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release
variants of this model with 7B, 13B, and 70B parameters as well.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs,
----
Llama 2-Chat, at scales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested,
Llama 2-Chat models generally perform better than existing open-source models. They also appear to
----
large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.
Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our
models outperform open-source chat models on most benchmarks we tested, and based on
当前的方案有一些问题,只能识别简单的PDF文本,并切割,如果有图片和表格,暂时不支持
历史管理
历史记录的裁剪
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
trim_messages,
)
from langchain_openai import ChatOpenAI
messages = [
SystemMessage("you're a good assistant, you always respond with a joke."),
HumanMessage("i wonder why it's called langchain"),
AIMessage(
'Well, I guess they thought "WordRope" and "SentenceString" just didn\'t have the same ring to it!'
),
HumanMessage("and who is harrison chasing anyways"),
AIMessage(
"Hmmm let me think.\n\nWhy, he's probably chasing after the last cup of coffee in the office!"
),
HumanMessage("what do you call a speechless parrot"),
]
trim_messages(
messages,
max_tokens=45,
strategy="last",
token_counter=ChatOpenAI(model="gpt-4o-mini"),
)
运行结果如下
[AIMessage(content="Hmmm let me think.\n\nWhy, he's probably chasing after the last cup of coffee in the office!", additional_kwargs={}, response_metadata={}),
HumanMessage(content='what do you call a speechless parrot', additional_kwargs={}, response_metadata={})]
保留systemPrompt
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
trim_messages,
)
from langchain_openai import ChatOpenAI
messages = [
SystemMessage("you're a good assistant, you always respond with a joke."),
HumanMessage("i wonder why it's called langchain"),
AIMessage(
'Well, I guess they thought "WordRope" and "SentenceString" just didn\'t have the same ring to it!'
),
HumanMessage("and who is harrison chasing anyways"),
AIMessage(
"Hmmm let me think.\n\nWhy, he's probably chasing after the last cup of coffee in the office!"
),
HumanMessage("what do you call a speechless parrot"),
]
# 保留 system prompt
trim_messages(
messages,
max_tokens=45,
strategy="last",
token_counter=ChatOpenAI(model="gpt-4o-mini"),
include_system=True,
allow_partial=True,
)
运行结果
[SystemMessage(content="you're a good assistant, you always respond with a joke.", additional_kwargs={}, response_metadata={}),
HumanMessage(content='what do you call a speechless parrot', additional_kwargs={}, response_metadata={})]
过滤带标识的历史记录
过滤,Prompt,剩下 带 消息类型为 human的 Prompt
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
filter_messages,
)
messages = [
SystemMessage("you are a good assistant", id="1"),
HumanMessage("example input", id="2", name="example_user"),
AIMessage("example output", id="3", name="example_assistant"),
HumanMessage("real input", id="4", name="bob"),
AIMessage("real output", id="5", name="alice"),
]
# 过滤,Prompt,剩下 带 消息类型为 human的 Prompt
filter_messages(messages, include_types="human")
运行结果
[HumanMessage(content='example input', additional_kwargs={}, response_metadata={}, name='example_user', id='2'),
HumanMessage(content='real input', additional_kwargs={}, response_metadata={}, name='bob', id='4')]
过滤,Prompt,剩下 带 name 为 example_user 和 的 example_assistant Prompt
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
filter_messages,
)
messages = [
SystemMessage("you are a good assistant", id="1"),
HumanMessage("example input", id="2", name="example_user"),
AIMessage("example output", id="3", name="example_assistant"),
HumanMessage("real input", id="4", name="bob"),
AIMessage("real output", id="5", name="alice"),
]
# 过滤,Prompt,剩下 带 name 为 example_user 和 的 example_assistant Prompt
filter_messages(messages, exclude_names=["example_user", "example_assistant"])
运行结果
[SystemMessage(content='you are a good assistant', additional_kwargs={}, response_metadata={}, id='1'),
HumanMessage(content='real input', additional_kwargs={}, response_metadata={}, name='bob', id='4'),
AIMessage(content='real output', additional_kwargs={}, response_metadata={}, name='alice', id='5')]
过滤 Prompt,剩下 类型为 HumanMessage, AIMessage,并且 不要 id为3的
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
filter_messages,
)
messages = [
SystemMessage("you are a good assistant", id="1"),
HumanMessage("example input", id="2", name="example_user"),
AIMessage("example output", id="3", name="example_assistant"),
HumanMessage("real input", id="4", name="bob"),
AIMessage("real output", id="5", name="alice"),
]
# 过滤,Prompt,剩下 带 name 为 example_user 和 的 example_assistant Prompt
filter_messages(messages, include_types=[HumanMessage, AIMessage], exclude_ids=["3"])
运行
[HumanMessage(content='example input', additional_kwargs={}, response_metadata={}, name='example_user', id='2'),
HumanMessage(content='real input', additional_kwargs={}, response_metadata={}, name='bob', id='4'),
AIMessage(content='real output', additional_kwargs={}, response_metadata={}, name='alice', id='5')]
Chain 和 LangChain Expression Language (LCEL)
什么是LCEL
LangChain Expression Language(LCEL)是一种声明式语言,可轻松组合不同的调用顺序构成 Chain。LCEL 自创立之初就被设计为能够支持将原型投入生产环境,无需代码更改,从最简单的“提示+LLM”链到最复杂的链(已有用户成功在生产环境中运行包含数百个步骤的 LCEL Chain)。
- LCEL 的核心特点是能够将多个简单的操作组合成复杂的任务, 例如,可以将文本生成、问答、文本分类等不同的语言模型操作通过 LCEL 表达式组合在一起,实现更高级的功能。
- 它提供了丰富的操作符和函数,允许开发者根据具体需求灵活地构建表达式。开发者可以根据输入文本的内容、模型的输出结果以及各种条件来动态地调整任务的执行流程。
- LCEL 表达式具有一定的可读性,使得开发者能够清晰地理解任务的逻辑结构。同时,它也便于代码的维护和修改,当需要对任务进行调整或扩展时,可以方便地在表达式中进行修改。
LCEL应用场景
- 在开发自然语言处理应用时,经常需要将多个语言模型操作组合起来完成复杂的任务。例如,先对输入文本进行分类,然后根据分类结果调用不同的模型进行进一步的处理,LCEL 可以方便地实现这种复杂的任务流程。
- 根据用户输入或其他外部条件动态地调整任务的执行方式。例如,根据用户输入的关键词选择不同的提示模板,或者根据模型的输出结果决定是否进行进一步的细化处理,LCEL 能够灵活地实现这些动态调整。
- LCEL 可以与 LangChain 中的其他组件以及其他相关的自然语言处理框架进行集成,从而更好地发挥其作用。例如,与 LangChain 的提示模板、模型接口等组件结合,实现更高效的语言模型应用开发。
LCEL特点
-
流支持:使用 LCEL 构建 Chain 时,你可以获得最佳的首个令牌时间(即从输出开始到首批输出生成的时间)。对于某些 Chain,这意味着可以直接从 LLM 流式传输令牌到流输出解析器,从而以与 LLM 提供商输出原始令牌相同的速率获得解析后的、增量的输出。
-
异步支持:任何使用 LCEL 构建的链条都可以通过同步 API(例如,在 Jupyter 笔记本中进行原型设计时)和异步 API(例如,在 LangServe 服务器中)调用。这使得相同的代码可用于原型设计和生产环境,具有出色的性能,并能够在同一服务器中处理多个并发请求。
-
优化的并行执行:当你的 LCEL 链条有可以并行执行的步骤时(例如,从多个检索器中获取文档),我们会自动执行,无论是在同步还是异步接口中,以实现最小的延迟。
-
重试和回退:为 LCEL 链的任何部分配置重试和回退。这是使链在规模上更可靠的绝佳方式。目前我们正在添加重试/回退的流媒体支持,因此你可以在不增加任何延迟成本的情况下获得增加的可靠性。
-
访问中间结果:对于更复杂的链条,访问在最终输出产生之前的中间步骤的结果通常非常有用。这可以用于让最终用户知道正在发生一些事情,甚至仅用于调试链条。你可以流式传输中间结果,并且在每个 LangServe 服务器上都可用。
-
输入和输出模式:输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和 JSONSchema 模式。这可以用于输入和输出的验证,是 LangServe 的一个组成部分。
-
无缝 LangSmith 跟踪集成:随着链条变得越来越复杂,理解每一步发生了什么变得越来越重要。通过 LCEL,所有步骤都自动记录到 LangSmith,以实现最大的可观察性和可调试性。
-
无缝 LangServe 部署集成:任何使用 LCEL 创建的链都可以轻松地使用 LangServe 进行部署。
pipeline 式调用 PromptTemplate, LLM 和 OutputParser
写一个简单的例子,使用 pipeline调用方式
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from pydantic import BaseModel, Field, validator
from typing import List, Dict, Optional
from enum import Enum
import json
# 输出结构
class SortEnum(str, Enum):
data = 'data'
price = 'price'
class OrderingEnum(str, Enum):
ascend = 'ascend'
descend = 'descend'
class Semantics(BaseModel):
name: Optional[str] = Field(description="流量包名称", default=None)
price_lower: Optional[int] = Field(description="价格下限", default=None)
price_upper: Optional[int] = Field(description="价格上限", default=None)
data_lower: Optional[int] = Field(description="流量下限", default=None)
data_upper: Optional[int] = Field(description="流量上限", default=None)
sort_by: Optional[SortEnum] = Field(description="按价格或流量排序", default=None)
ordering: Optional[OrderingEnum] = Field(description="升序或降序排列", default=None)
# Prompt 模板
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个语义解析器。你的任务是将用户的输入解析成JSON表示。不要回答用户的问题。"),
("human", "{text}"),
]
)
# 模型
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm = llm.with_structured_output(Semantics)
# LCEL 表达式
runnable = (
{"text": RunnablePassthrough()} | prompt | structured_llm
)
# 直接运行
ret = runnable.invoke("不超过100元的流量大的套餐有哪些")
print(
json.dumps(
ret.dict(),
indent = 4,
ensure_ascii=False
)
)
输出结果
{
"name": null,
"price_lower": null,
"price_upper": 100,
"data_lower": null,
"data_upper": null,
"sort_by": "data",
"ordering": "descend"
}
这里我们关注
# LCEL 表达式
runnable = (
{"text": RunnablePassthrough()} | prompt | structured_llm
)
我们将 提示词模板 prompt 的 text 字段复制 为 RunnablePassthrough() 得到的输出作为 prompt 的 输入
那么 prompt 即
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个语义解析器。你的任务是将用户的输入解析成JSON表示。不要回答用户的问题。"),
("human", RunnablePassthrough()),
]
)
再将 prompt 的结果 作为 structured_llm 的输入,最终通过如下代码运行 pipeline
# 直接运行
ret = runnable.invoke("不超过100元的流量大的套餐有哪些")
得到结果如下
{
"name": null,
"price_lower": null,
"price_upper": 100,
"data_lower": null,
"data_upper": null,
"sort_by": "data",
"ordering": "descend"
}
代码实现非常优雅,如果需要的功能又是 structured_llm 的 输出,那么可以继续使用pipeline的方式接下去,例如outputparser,我们以stream流式输出为例
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from pydantic import BaseModel, Field, validator
from typing import List, Dict, Optional
from enum import Enum
import json
prompt = PromptTemplate.from_template("讲个关于{topic}的故事")
runnable = (
{"topic": RunnablePassthrough()} | prompt | llm | StrOutputParser()
)
# 流式输出
for s in runnable.stream("海尔兄弟"):
print(s, end="", flush=True)
用 LCEL 实现 RAG
加载文档->文档切分->词向量编码->数据入库->检索
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.document_loaders import PyMuPDFLoader
# 加载文档
loader = PyMuPDFLoader("llama2.pdf")
pages = loader.load_and_split()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents(
[page.page_content for page in pages[:4]]
)
# 灌库
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(texts, embeddings)
# 检索 top-2 结果
retriever = db.as_retriever(search_kwargs={"k": 2})
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
# Prompt模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# Chain
rag_chain = (
{"question": RunnablePassthrough(), "context": retriever}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("Llama 2有多少参数")
运行结果
'根据提供的上下文,Llama 2 有 7B(70亿)、13B(130亿)和 70B(700亿)参数的不同版本。'
从这里看出,通过lcel进行rag,代码量少,且代码优雅,通过pipeline也非常容易控制功能
用 LCEL 实现工厂模式
有如下需求,在流程不变的情况下需要测试不同的模型表现,有三个模型可选 Qianfan、gpt 和qwen ,这里通过LCEL工厂模式实现
from langchain_core.runnables.utils import ConfigurableField
from langchain_openai import ChatOpenAI
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_community.chat_models import ChatQwen
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import HumanMessage
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import os
# 模型1:百度千帆 ERNIE 模型
ernie_model = QianfanChatEndpoint(
qianfan_ak=os.getenv('ERNIE_CLIENT_ID'),
qianfan_sk=os.getenv('ERNIE_CLIENT_SECRET')
)
# 模型2:OpenAI GPT 模型
gpt_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 模型3:Qwen1.5 - 1.8B 模型
qwen_model = ChatQwen(
endpoint_url=os.getenv('QWEN_ENDPOINT_URL'),
access_key_id=os.getenv('QWEN_ACCESS_KEY_ID'),
access_key_secret=os.getenv('QWEN_ACCESS_KEY_SECRET'),
model_name="qwen-1.5-1.8b"
)
# 通过 configurable_alternatives 按指定字段选择模型
model = gpt_model.configurable_alternatives(
ConfigurableField(id="llm"),
default_key="gpt",
ernie=ernie_model,
qwen=qwen_model
)
# Prompt 模板
prompt = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate.from_template("{query}"),
]
)
# LCEL
chain = (
{"query": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# 运行时指定模型 "gpt" or "ernie" or "qwen"
try:
ret = chain.with_config(configurable={"llm": "qwen"}).invoke("请自我介绍")
print(ret)
except Exception as e:
print(f"运行时出错: {e}")
重点关注
# 通过 configurable_alternatives 按指定字段选择模型
model = gpt_model.configurable_alternatives(
ConfigurableField(id="llm"),
default_key="gpt",
ernie=ernie_model,
qwen=qwen_model
)
...
ret = chain.with_config(configurable={"llm": "qwen"}).invoke("请自我介绍")
这里 configurable_alternatives 的key 指的就是

存储与管理对话历史
我们可以通过session_id与对话历史绑定,并且通过SQLChatMessageHistory 抽象接口轻松完成 对话历史的存储和管理
from langchain_community.chat_message_histories import SQLChatMessageHistory
def get_session_history(session_id):
# 通过 session_id 区分对话历史,并存储在 sqlite 数据库中
return SQLChatMessageHistory(session_id, "sqlite:///memory.db")
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
runnable = model | StrOutputParser()
runnable_with_history = RunnableWithMessageHistory(
runnable, # 指定 runnable
get_session_history, # 指定自定义的历史管理方法
)
runnable_with_history.invoke(
[HumanMessage(content="你好,我叫阿仔")],
config={"configurable": {"session_id": "dana"}},
)
runnable_with_history.invoke(
[HumanMessage(content="你知道我叫什么名字")],
config={"configurable": {"session_id": "dana"}},
)
runnable_with_history.invoke(
[HumanMessage(content="你知道我叫什么名字")],
config={"configurable": {"session_id": "test"}},
)
运行结果
'你好,大拿!很高兴再次见到你。有任何问题或想聊的话题吗?'
'是的,你叫阿仔。有什么我可以为你做的呢?'
'抱歉,我不知您的名字。如果您愿意,可以告诉我您的名字。'
def get_session_history(session_id):
# 通过 session_id 区分对话历史,并存储在 sqlite 数据库中
return SQLChatMessageHistory(session_id, "sqlite:///memory.db")
这段代码可以将数据存储到sql,也可以存储到redis
from langchain.memory.chat_message_histories import RedisChatMessageHistory
def get_session_history(session_id):
# 通过 session_id 区分对话历史,并存储在 Redis 中
return RedisChatMessageHistory(
session_id=session_id,
url="redis://localhost:6379" # 这里假设 Redis 运行在本地,端口为 6379,根据实际情况修改
)

















 4143
4143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









