







线性回归:线性关系描述输入输出的关系。
方程:y=ax1+bx2+cx3+d 参数:m=[a,b,c,d]
数据为矩阵:(x1,1; x2,1; x3,1) , (x1,2; x2,2; x3,2)......
目标:使预测值尽可能的接近真实值。
优化方法:梯度下降法求线性回归的最优解
当前初始状态:m0 = [a0, b0, c0, d0] 每一步为△m
目标:寻找最地点。
步长:设置 learning rate的值。
梯度计算:loss = ax1,t + bx2,t+ cx3,t + d - y
参数更新:△m
梯度下降法:初始化参数,开始循环,带入数据求出结果值(模拟估计值);
与真实值比较计算loss=y-y' ;
对各个变量求导得到△m;
更新变量m;如果loss足够小或者循环结束,停止计算。
note:可以多目标学习,需要多个参数,计算多个loss。
从线性到非线性:非线性激励(函数)
激励函数评价标准:正向对激励的调整,反向梯度损失。反向就是training过程,正向是测试过程。
非线性激励函数:
sigmoid: 一般最后一层用

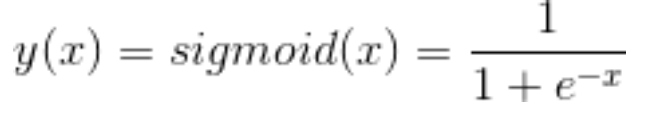
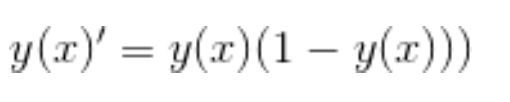
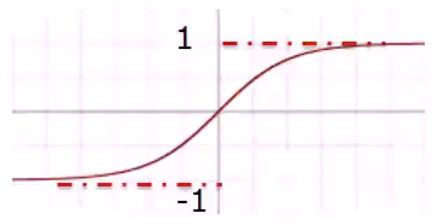
tanh:

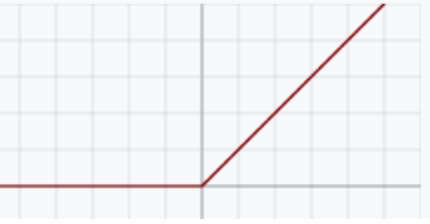
ReLU(Rectified linear unit): 最好的,深度学习一般都用relu。
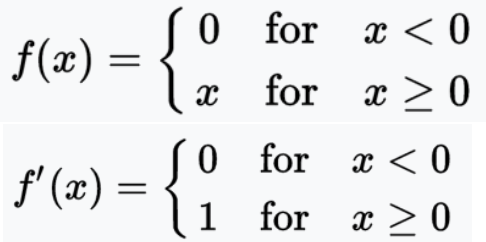
神经元的并联/串联:并联影响宽度,串联影响层数。
从第一层到最后输出层,每一个神经元的数值由前一层神经元数值,激励函数,参数W,b共同决定。
第n+1层第k个神经元的方程表示:

m表示第n层神经网络的宽度,n表示当前神经网络的深度。
神经网络的配件:
损失函数loss:影响深度学习的性能的重要因素。合适的损失函数确保模型收敛。
Softmax:

对应关系,损失函数LOSS影响:
[1,2,3,4,1,2] ----------->[0.024,0.064,0.175, 0.475, 0.024, 0.064] 增大了参数之间的间距。区别更明显。
优点:分类问题的预测结果更明显。
Cross entropy:
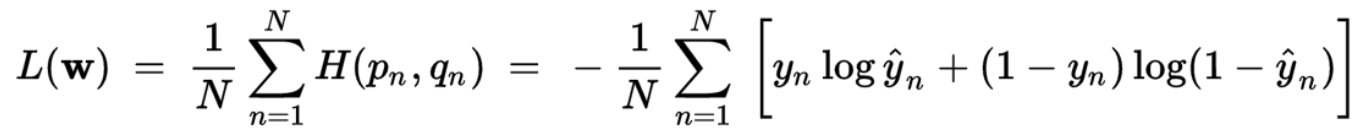
损失函数:
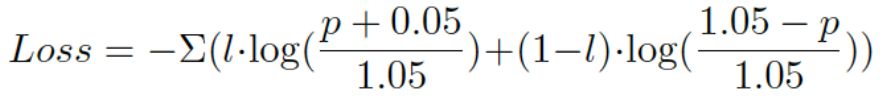
用途:目标为[0,1]区间的回归问题,以及生成问题。
很多时候我们需要自定义一个损失函数,当看中某一个属性的时候,可以单独将某一些预测值取出或赋予不同大小的参数。
合并多个loss:多目标训练,设置合理的loss结合方式(各种运算)。
神经网络的融合:不同的神经网络loss结合,共同loss对网络进行训练指导。
学习率:Learning rate
设置值大时,收敛的速度快。
设置值小时,精度高,收敛的慢。
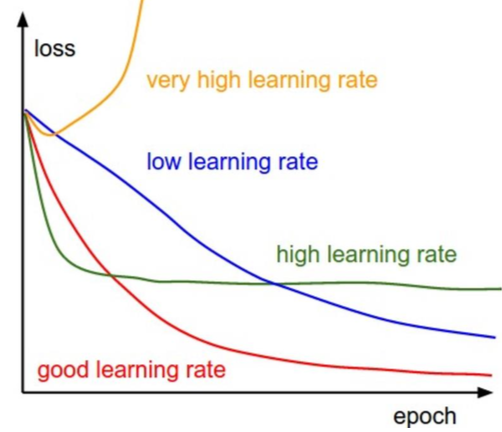
如何设置合适的Learning rate?
1. 给个Fixed值。2. 根据step来设置,每一阶段的epoch给定一个learningrate。3. Adagrad 4. RMSprop
动量:沿着已经得到的优化方向前进,不用重新找方向,只需要微调。
用动量和直接调大学习率有什么区别?
动量相当于是矢量相加的结果。重新考虑方向微调和步长。动量的推动效果更好一些。
Nesterov 动量:新的梯度更新是在动量投射的基础上。
过拟合 Overfitting:生成的模型仅适用于本次数据,通用性不佳。
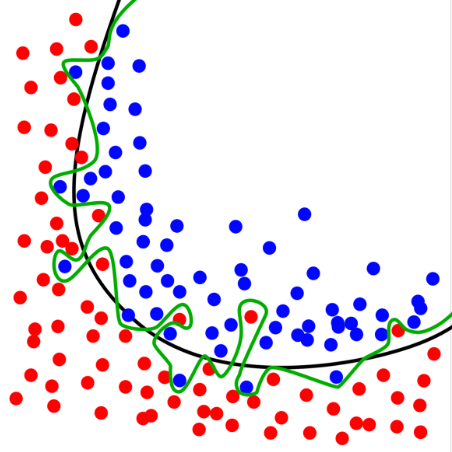
如果更多的参数参与决策,会对输入有更高的适应性。
解决方法:
1. Regularization:在loss里添加额外的变量
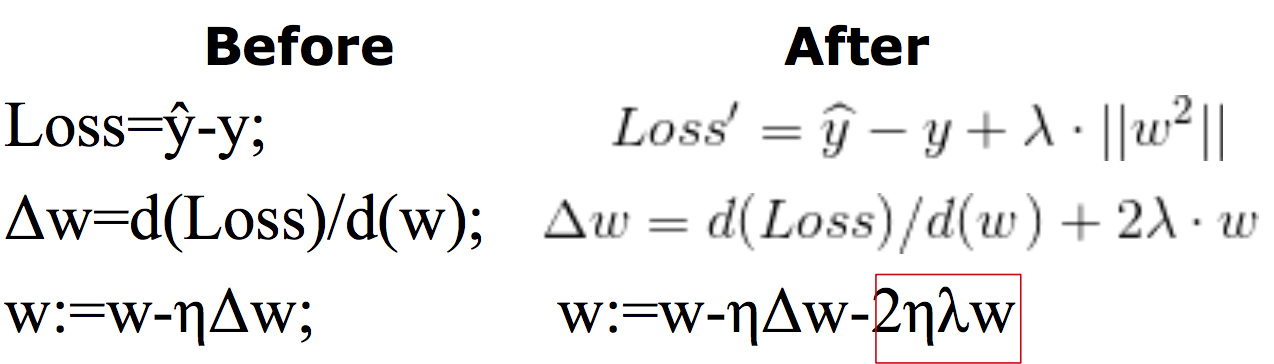
w的值比较一致的时候,得到的平方值最小。
w大部分的值参与计算,减小过拟合的影响。
Regularization对参数w有什么影响?
为了使loss’ 最小,w平方要尽可能的小,要求w的值要尽可能的平衡。Regularization和loss共同影响w的变化。
2. Dropout:随机的选择一些神经元,置0. 一般选择50%的神经元,效果最好。
tips:Dropout,pooling的区别?
pooling的本质是降维;
Dropout的本质是Regularization。因为最终目的是让参数分布更均衡。
3. Fine-tuning/Data Augmentation
本质:用已经训练好的model接着训练,大部分参数不用更新,实际的参数大量的减少。















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









