







📚 一、整篇论文的总结 📚
1️⃣ 引言 🎬
- 本文提出了一种新的深度学习框架——残差网络(ResNet),有效地解决了深度神经网络中的退化问题。作者通过引入“短路连接”来构建深度残差网络,使得网络可以直接将输入特征传递到后面的层。
2️⃣ 深度残差学习框架 🧩
- 作者提出了一个新的残差学习框架,以解决深度网络的退化问题。在这个框架中,每一层的输出是由该层的输入和该层所学习的残差函数的和得到的。这种设计使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数。
3️⃣ 实验 🧪
- 作者在ImageNet数据集上进行了实验,证明了深度残差网络在图像分类任务上的有效性。此外,作者还将深度残差网络应用于PASCAL VOC和MS COCO对象检测任务,取得了显著的性能提升。
4️⃣ 分析 📊
- 作者对深度残差网络进行了详细的分析,包括层响应的分析、超过1000层的网络的探索、以及在PASCAL VOC和MS COCO上的对象检测结果的分析。
5️⃣ 结论 🎯
- 本文提出的深度残差网络成功地解决了深度神经网络中的退化问题,显著提高了图像分类和对象检测任务的性能。这种网络结构的设计,使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数。这一发现对深度学习领域的发展具有重要的启示意义。
二、常见面试题
1️⃣ 步骤1:ResNet的什么、为什么、怎么做
-
什么:ResNet,即残差网络,是一种深度学习模型。它的主要特点是通过引入“短路连接”(shortcut connection)来构建深度残差网络,使得网络可以直接将输入特征传递到后面的层。
-
为什么:深度神经网络在增加层数后会出现性能退化的问题,即网络的准确率开始饱和并迅速下降。ResNet通过引入“短路连接”,使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数,有效地解决了这个问题。
-
怎么做:在ResNet中,每个残差块由两个或三个卷积层和一个“短路连接”组成。在前向传播过程中,每个残差块的输入不仅被送入卷积层进行处理,还会与卷积层的输出相加,这就是“短路连接”。这种设计使得网络可以直接将输入特征传递到后面的层。
2️⃣ 步骤2:快捷连接的什么、为什么、怎么做
-
什么:快捷连接(shortcut connection)是ResNet中的一个重要组成部分,它直接将输入特征传递到后面的层。
-
为什么:快捷连接的引入使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数。这有效地解决了深度神经网络中的退化问题。
-
怎么做:在ResNet中,快捷连接可以通过两种方式实现:(A) 当输入和输出的维度一致时,快捷连接直接执行恒等映射;(B) 当输入和输出的维度不一致时,可以通过1x1的卷积来改变输入的维度,使其与输出的维度匹配,这被称为投影快捷连接。
3️⃣ 步骤3:Maxout的什么、为什么、怎么做
-
什么:Maxout是一种激活函数,它的输出是其输入的最大值。
-
为什么:Maxout激活函数能够自动学习输入的最优表示,而不需要预设一个固定的非线性函数(如ReLU或Sigmoid)。这使得模型能够更好地适应数据,提高模型的表达能力。
-
怎么做:Maxout激活函数的计算过程非常简单,就是在所有输入中选择最大的一个作为输出。具体来说,如果一个Maxout神经元接收到n个输入,那么它的输出就是这n个输入中的最大值。
4️⃣ 步骤4:批量归一化的什么、为什么、怎么做
-
什么:批量归一化(Batch Normalization)是一种在深度神经网络中常用的技术,它在每一层的激活函数之前,对每一批输入进行归一化处理,使得结果的均值为0,方差为1。
-
为什么:批量归一化可以加速深度神经网络的训练,防止梯度消失或梯度爆炸,使得网络能够使用更高的学习率,同时还具有一定的正则化效果,可以防止过拟合。
-
怎么做:在实现批量归一化时,首先计算出每一批数据的均值和方差,然后用每个数据减去均值,再除以标准差,这样就完成了归一化。为了防止归一化后的数据失去原有的表达能力,批量归一化还引入了两个可学习的参数,分别是缩放因子和偏移因子,通过这两个参数,可以恢复数据的原有表达能力。
三、实现深度残差网络的步骤 & 代码
-
导入必要的库:首先,需要导入一些必要的Python库,如NumPy,TensorFlow或PyTorch。
-
定义基本的残差块:在ResNet中,最基本的构建模块是残差块。每个残差块包含两个或三个卷积层,以及一个跳过连接,该连接将输入直接添加到卷积层的输出。
-
构建网络:使用残差块,可以构建整个ResNet。ResNet-34由一个7x7的卷积层,然后是3个大小为64,128,256的残差块序列,每个序列包含3,4,6,3个残差块,最后是全局平均池化层和全连接层。
-
初始化权重:在训练网络之前,需要初始化网络的权重。这通常可以通过随机初始化或预训练模型来完成。
-
训练网络:使用适当的损失函数和优化器来训练网络。在每个训练周期中,需要前向传播,计算损失,反向传播和更新权重。
-
评估网络:在训练网络后,需要在验证集或测试集上评估网络的性能。
# 导入必要的库
import torch
import torch.nn as nn
# 定义基本的残差块
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = torch.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = torch.relu(out)
return out
# 构建网络
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = torch.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = torch.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# 定义ResNet-34
def ResNet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
# 初始化网络
net = ResNet34()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
# 训练网络
for epoch in range(100):
for i, (inputs, labels) in enumerate(trainloader):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = net(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 评估网络
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))
四、十个问题 & 回答
1️⃣ Q1 论文试图解决什么问题?
这篇论文试图解决深度神经网络中的退化问题。当网络深度增加时,准确率会饱和甚至下降,这并不是由过拟合引起的,而是由网络深度增加引起的。这被称为网络退化问题。
2️⃣ Q2 这是否是一个新的问题?
不,这不是一个新问题。深度神经网络的退化问题在深度学习领域已经被广泛认识到。然而,这篇论文提出了一种新的方法来解决这个问题。
3️⃣ Q3 这篇文章要验证一个什么科学假设?
这篇文章的科学假设是:通过引入“短路连接”,可以构建深度残差网络,使得网络可以直接将输入特征传递到后面的层。这种设计使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数。
4️⃣ Q4 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关的研究主要集中在深度学习和神经网络的设计和优化上。例如,VGGNet和Inception网络都是试图通过增加网络深度来提高性能的研究。这篇论文的作者Kaiming He是深度学习领域的知名研究员,他的研究主要集中在计算机视觉和机器学习领域,特别是在深度学习的设计和优化上。
5️⃣ Q5 论文中提到的解决方案之关键是什么?
论文中提到的解决方案的关键是引入了“短路连接”来构建深度残差网络。这种设计使得网络可以直接将输入特征传递到后面的层,使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数。
6️⃣ Q6 论文中的实验是如何设计的?
论文中的实验主要分为两部分:一部分是在ImageNet数据集上进行图像分类任务,另一部分是在PASCAL VOC和MS COCO数据集上进行对象检测任务。在实验中,作者比较了不同深度的ResNet和其他深度学习模型的性能。
7️⃣ Q7 用于定量评估的数据集是什么?代码有没有开源?
用于定量评估的数据集包括ImageNet,PASCAL VOC和MS COCO。至于代码,论文并没有明确提到是否开源。但是,由于ResNet的影响力,现在有许多开源的ResNet实现可供参考。
8️⃣ Q8 论文中的实验及结果有没有很好地支持需要验证的科学假设?
是的,论文中的实验结果很好地支持了需要验证的科学假设。实验结果显示,深度残差网络在图像分类和对象检测任务上都取得了显著的性能提升,这证明了通过引入“短路连接”构建深度残差网络的有效性。
9️⃣ Q9 这篇论文到底有什么贡献?
这篇论文的主要贡献是提出了一种新的深度学习框架——深度残差网络(ResNet),有效地解决了深度神经网络中的退化问题。这种网络结构的设计,使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数。这一发现对深度学习领域的发展具有重要的启示意义。
🔟 Q10 下一步呢?有什么工作可以继续深入?
下一步的工作可以在多个方向进行深入。首先,可以进一步探索深度残差网络的理论性质,例如,为什么“短路连接”可以有效地解决退化问题。其次,可以尝试将深度残差网络应用于其他类型的任务,例如语音识别或自然语言处理。最后,可以尝试设计新的网络结构,以进一步提高深度残差网络的性能。
五、每页摘要
📄 第1页摘要 📄
🔍 主要观点 🔍
-
深度残差学习:这篇论文提出了一种深度残差学习框架,以便于训练比以前使用的网络更深的网络。这些残差网络更易于优化,并且可以从显著增加的深度中获得准确性。
-
实验结果:在ImageNet数据集上,作者评估了最深达152层的残差网络,这比VGG网络深8倍,但复杂性更低。这些残差网络的集成在ImageNet测试集上达到了3.57%的错误率,这个结果赢得了ILSVRC 2015分类任务的第一名。
-
深度重要性:表示的深度对于许多视觉识别任务至关重要。仅仅由于我们的深度表示,我们在COCO对象检测数据集上获得了28%的相对改进。
-
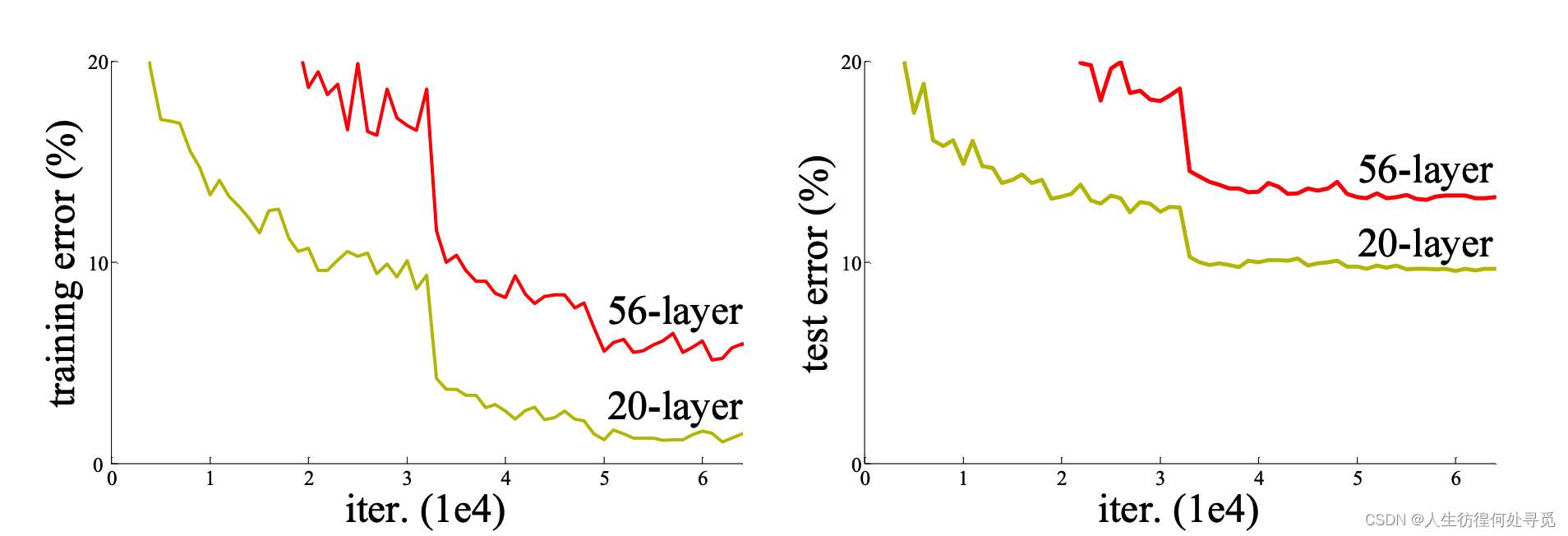
深度网络的挑战:尽管深度网络在图像分类等任务上取得了突破,但随着网络深度的增加,准确性会饱和,然后迅速下降。这种退化并非由过拟合引起,而是由于更深的模型导致的更高的训练误差。
📄 第2页摘要 📄
🔍 主要观点 🔍
-
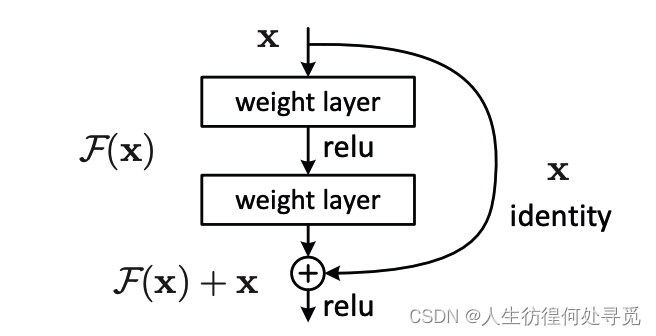
深度残差学习框架:论文通过引入深度残差学习框架来解决退化问题。作者让堆叠的非线性层拟合另一个映射 F ( x ) : = H ( x ) − x F(x) :=H(x)-x F(x):=H(x)−x,原始映射被重塑为 F ( x ) + x F(x)+x F(x)+x。作者假设优化残差映射比优化原始的、无参考的映射更容易。
-
快捷连接:通过使用“快捷连接”,可以实现 F ( x ) + x F(x)+x F(x)+x的公式。在这种情况下,快捷连接简单地执行恒等映射,它们的输出被添加到堆叠层的输出。
-
实验结果:作者在ImageNet上进行了全面的实验,显示了退化问题并评估了他们的方法。他们的深度残差网络易于优化,但是当深度增加时,对应的“平凡”网络(只是堆叠层的网络)会显示出更高的训练误差。
接下来,我将继续提取第3页的内容。
📄 第3页摘要 📄
🔍 主要观点 🔍
-
残差学习:作者让堆叠的非线性层拟合另一个映射 F ( x ) : = H ( x ) − x F(x) :=H(x)-x F(x):=H(x)−x,原始映射被重塑为 F ( x ) + x F(x)+x F(x)+x。这种方法使得优化残差映射比优化原始的、无参考的映射更容易。
-
快捷连接:作者在每几个堆叠层中采用残差学习。他们定义了一个构建块,形式为 y = F ( x ; W i ) + x y=F(x; {W_i}) + x y=F(x;Wi)+x。这里,x和y是被考虑的层的输入和输出向量。函数 F ( x ; W i ) F(x; {W_i}) F(x;Wi)表示要学习的残差映射。
-
网络架构:作者测试了各种平凡/残差网络,并观察到一致的现象。他们描述了两个用于ImageNet的模型,包括平凡网络和残差网络。作者提供了ImageNet的网络架构示例,包括VGG-19模型、34层的平凡网络和34层的残差网络。对于残差网络,作者插入了快捷连接,将网络转变为其对应的残差版本。
-
快捷连接:当输入和输出的维度相同时,可以直接使用恒等映射的快捷连接。当维度增加时,作者考虑了两种选项:
- (A)快捷连接仍然执行恒等映射,对增加的维度进行零填充;
- (B)使用投影快捷连接来匹配维度,通过1x1的卷积完成。
-
实现细节:作者的实现遵循了[21, 41]的实践。他们使用了批量归一化(BN)[16],在每次卷积之后和激活之前进行。所有的平凡/残差网络都是从头开始训练的。在测试时,作者采用了标准的10-crop测试[21]。为了获得最好的结果,他们采用了[41, 13]中的全卷积形式,并在多个尺度上平均得分。
📄 第4页摘要 📄
🔍 主要观点 🔍
-
网络架构:作者提供了ImageNet的网络架构示例,包括18层、34层、50层、101层和152层的网络。他们使用了不同的构建块,并在某些层中进行了下采样。
-
平凡网络:作者展示了不同网络的训练结果。他们发现,34层的平凡网络在整个训练过程中都有较高的训练误差,尽管18层网络的解决空间是34层网络的子空间。
-
残差网络:作者评估了18层和34层的残差网络。他们发现,34层的残差网络比18层的残差网络更好,而且34层的残差网络在训练误差和验证数据上都表现得更好。这表明,退化问题在这种设置中得到了很好的解决,作者成功地从增加深度中获得了准确性的提升。
📄 第5页摘要 📄
🔍 主要观点 🔍
-
训练结果:作者展示了不同网络的训练结果。他们发现,34层的残差网络比18层的残差网络更好,而且34层的残差网络在训练误差和验证数据上都表现得更好。这表明,退化问题在这种设置中得到了很好的解决,作者成功地从增加深度中获得了准确性的提升。
-
快捷连接:作者研究了投影快捷连接。他们比较了三种选项:
- (A) 零填充快捷连接用于增加维度,所有快捷连接都是参数自由的
- (B) 投影快捷连接用于增加维度,其他快捷连接是恒等的;
- © 所有快捷连接都是投影的。
-
深度瓶颈架构:作者描述了他们的更深的ImageNet网络。由于对他们能够承受的训练时间的考虑,他们将构建块修改为瓶颈设计。对于每个残差函数F,他们使用3层的堆叠而不是2层。这三层是1x1、3x3和1x1的卷积,其中1x1的层负责减少然后增加(恢复)维度,使3x3的层成为具有较小输入/输出维度的瓶颈。
📄 第6页摘要 📄
🔍 主要观点 🔍
-
深度瓶颈架构:作者描述了他们的更深的ImageNet网络。由于对他们能够承受的训练时间的考虑,他们将构建块修改为瓶颈设计。对于每个残差函数F,他们使用3层的堆叠而不是2层。这三层是1x1、3x3和1x1的卷积,其中1x1的层负责减少然后增加(恢复)维度,使3x3的层成为具有较小输入/输出维度的瓶颈。
-
训练结果:作者展示了不同网络的训练结果。他们发现,50/101/152层的残差网络比34层的残差网络更好,而且这些深度的残差网络在训练误差和验证数据上都表现得更好。这表明,退化问题在这种设置中得到了很好的解决,作者成功地从增加深度中获得了准确性的提升。
-
与最先进方法的比较:作者与之前最好的单模型结果进行了比较。他们的基线34层残差网络已经达到了非常有竞争力的准确性。他们的152层残差网络在单模型的top-5验证错误率为4.49%。这个单模型的结果超过了所有之前的集成结果。他们将不同深度的六个模型组合成一个集成(只有两个152层的模型在提交时),这导致了测试集上的3.57%的top-5错误率。这个条目在ILSVRC 2015中获得了第一名。
📄 第7页摘要 📄
🔍 主要观点 🔍
-
层响应的分析:作者展示了层响应的标准偏差。响应是每个3x3层的输出,经过BN并在其他非线性(ReLU/加法)之前。对于ResNets,这种分析揭示了残差函数的响应强度。作者发现,ResNets的响应通常比他们的普通对应项小。这些结果支持了他们的基本动机,即残差函数可能通常比非残差函数更接近零。
-
探索超过1000层:作者探索了一个超过1000层的极深模型。他们设定n=200,这导致了一个1202层的网络,该网络按照上述方式进行训练。他们的方法没有优化困难,这个1202层的网络能够达到小于0.1%的训练误差。然而,这个1202层网络的测试结果比他们的110层网络差,尽管两者的训练误差相似。作者认为这是由于过拟合。对于这个小数据集,1202层网络可能过大。
-
在PASCAL和MS COCO上的对象检测:他们的方法在其他识别任务上具有良好的泛化性能。作者展示了在PASCAL VOC 2007和2012以及COCO上的对象检测基线结果。他们采用了Faster R-CNN作为检测方法。他们对比了使用VGG-16和ResNet-101的结果。在COCO数据集上,他们获得了6.0%的增加,在COCO的标准度量(mAP@[.5, .95])上,这是28%的相对改进。这个增益完全归因于更好的网络。
📄 第10页摘要 📄
-
对象检测基线:作者介绍了基于Faster R-CNN系统的检测方法。模型首先通过ImageNet分类模型进行初始化,然后在对象检测数据上进行微调。作者在ILSVRC和COCO 2015检测竞赛时使用了ResNet-50/101。
-
PASCAL VOC:作者按照[7, 32]的方法,使用VOC 2007的5k trainval图像和VOC 2012的16k trainval图像进行训练。结果显示,ResNet-101的mAP比VGG-16提高了超过3%,这个提升完全归因于ResNet学习到的改进特征。
-
MS COCO:作者在MS COCO数据集上进行了评估,该数据集包含80个对象类别。作者使用80k的训练图像进行训练,并在40k的验证图像上进行评估。在MS COCO验证集上的结果显示,ResNet-101的mAP@[.5, .95]比VGG-16提高了6%,这是一个28%的相对改进,完全归因于更好的网络学习到的特征。
-
对象检测改进:作者报告了为竞赛所做的改进。这些改进基于深度特征,因此应该从残差学习中受益。
-
MS COCO:作者使用了框架精炼和全局上下文两种改进方法。框架精炼遵循[6]中的迭代定位。全局上下文在Fast R-CNN步骤中被结合使用。通过全局空间金字塔池化(SPP)[12]对全图像conv特征图进行池化,可以获得全局上下文特征。这个全局特征与原始的每个区域特征进行连接,然后通过兄弟分类和框回归层。这个新结构进行端到端的训练。全局上下文使mAP@.5提高了大约1个百分点。
-
多尺度测试:在上述所有结果中,都是通过单尺度训练/测试获得的,其中图像的短边为600像素。多尺度训练/测试已经在[12, 7]中通过从特征金字塔中选择一个尺度进行开发,在[33]中通过使用maxout层进行开发。在当前的实现中,作者已经按照[33]进行了多尺度测试;由于时间有限,还没有进行多尺度训练。此外,只对Fast R-CNN步骤进行了多尺度测试(但尚未对RPN步骤进行)。
📄 第11页摘要 📄
-
对象检测改进:作者在MS COCO数据集上使用Faster R-CNN和ResNet-101进行了对象检测改进。他们使用了框架精炼、全局上下文和多尺度测试等技术,这些技术都在表9中有所体现。
-
PASCAL VOC结果:作者在PASCAL VOC 2007和2012测试集上展示了检测结果。他们的Faster R-CNN系统作为基线,他们的“baseline+++”系统包括了表9中的框架精炼、上下文和多尺度测试。
-
MS COCO结果:作者在PASCAL VOC 2012测试集上展示了检测结果。他们的Faster R-CNN系统作为基线,他们的“baseline+++”系统包括了表9中的框架精炼、上下文和多尺度测试。
-
多尺度测试:作者使用了两个相邻的尺度进行多尺度测试。他们在特征金字塔中选择了一个尺度进行RoI池化和后续层的操作,这些操作通过maxout进行合并。多尺度测试使mAP提高了超过2个百分点。
-
使用验证数据:作者使用了80k+40k的训练验证集进行训练,使用20k的测试开发集进行评估。在这种设置下,结果是mAP@.5为55.7%,mAP@[.5, .95]为34.9%。这是他们的单模型结果。
-
集成:在Faster R-CNN中,作者使用了两个相邻的尺度进行多尺度测试。他们在特征金字塔中选择了一个尺度进行RoI池化和后续层的操作,这些操作通过maxout进行合并。多尺度测试使mAP提高了超过2个百分点。
-
使用验证数据:作者使用了80k+40k的训练验证集进行训练,使用20k的测试开发集进行评估。在这种设置下,结果是mAP@.5为55.7%,mAP@[.5, .95]为34.9%。这是他们的单模型结果。
📄 第12页摘要 📄
- ImageNet定位:ImageNet定位任务要求对对象进行分类和定位。作者假设首先采用图像级分类器来预测图像的类标签,然后定位算法只负责基于预测的类别预测边界框。作者采用了“每类回归”(PCR)策略,为每个类学习一个边界框回归器。他们预先训练网络进行ImageNet分类,然后微调它们进行定位。他们在提供的1000类ImageNet训练集上训练网络。
- 定位算法:他们的定位算法基于RPN框架,但进行了一些修改。与[32]中的类别不可知的方式不同,他们的RPN定位设计为每类形式。这个RPN以两个兄弟1x1卷积层结束,用于二元分类(cls)和框回归(reg),如[32]所示。cls和reg层都是每类形式,与[32]形成对比。具体来说,cls层有一个1000-d输出,每个维度是二元逻辑回归,用于预测是否是一个对象类;reg层有一个1000x4-d输出,包括1000个类的框回归器。与[32]一样,他们的边界框回归参考了每个位置的多个平移不变的“锚”框。
- 定位结果:作者首先进行了“预测”测试,使用地面真实类作为分类预测。VGG的论文[41]使用地面真实类报告了33.1%的中心裁剪误差。在同样的设置下,他们使用ResNet-101网络的RPN方法将中心裁剪误差显著降低到13.3%。这个比较展示了他们框架的优秀性能。通过密集(全卷积)和多尺度测试,他们的ResNet-101在使用地面真实类时达到了10.1%的中心裁剪误差。
🎉 总结 🎉
本文提出了一种新的深度学习框架——残差网络(ResNet),有效地解决了深度神经网络中的退化问题。作者通过引入“短路连接”来构建深度残差网络,使得网络可以直接将输入特征传递到后面的层。这种设计使得网络可以通过学习残差函数来提升性能,而不是直接学习原始的未参考输入的函数。作者在ImageNet数据集上进行了实验,证明了深度残差网络在图像分类任务上的有效性。此外,作者还将深度残差网络应用于PASCAL VOC和MS COCO对象检测任务,取得了显著的性能提升。














 9122
9122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









