







一、整体摘要 📝🔍🎯
1️⃣ 引言:这篇论文介绍了一种深度卷积神经网络(CNN)的设计和实现,该网络在ImageNet LSVRC-2010比赛中的图像分类任务上取得了显著的成果。这个网络包含6000万个参数和650,000个神经元,由五层卷积,一些最大池化层,和三个全连接层组成。这个网络也是第一个在ImageNet数据集上训练的大规模CNN。这个网络的设计和实现,以及其在ImageNet比赛中的成功,标志着深度学习在计算机视觉领域的重要突破。
2️⃣ CNN的优势和挑战:尽管CNN具有吸引人的特性,并且其局部架构相对高效,但是将其大规模应用于高分辨率图像仍然过于昂贵。然而,当前的GPU,配合高度优化的2D卷积实现,足够强大,可以促进训练足够大的CNN。这使得CNN能够处理大规模的高分辨率图像,从而在图像分类任务上取得更好的性能。
3️⃣ 网络设计:该网络包含一些新颖和不寻常的特性,这些特性提高了其性能并减少了其训练时间。这些特性包括ReLU非线性,多GPU训练,局部响应归一化,重叠池化等。ReLU非线性使得网络的训练速度比使用传统的饱和非线性(如tanh或sigmoid)快很多。多GPU训练使得网络能够处理更大的模型和更大的数据集。局部响应归一化和重叠池化则提高了网络的泛化能力。
4️⃣ 减少过拟合:由于网络的大规模性,过拟合成为一个重要问题。为了对抗过拟合,作者使用了数据增强和Dropout技术。数据增强包括图像平移、水平反射和RGB通道强度的改变,这些都能有效地扩大训练数据集,从而减少过拟合。Dropout是一种在训练过程中随机关闭一部分神经元的技术,它可以防止神经元的复杂共适应,从而提高模型的泛化能力。
5️⃣ 训练细节:网络使用随机梯度下降进行训练,批量大小为128个样本,动量为0.9,权重衰减为0.0005。
6️⃣ 结果:该网络在ILSVRC-2010和ILSVRC-2012比赛中取得了显著的成果,大大超过了以前的最佳结果。
7️⃣ 定性评估:作者通过计算网络在八个测试图像上的前五个预测,定性地评估网络学到了什么。
这篇论文的主要贡献在于,它证明了深度学习,特别是深度卷积神经网络,可以在大规模图像分类任务上取得显著的成果。这为深度学习在计算机视觉领域的广泛应用奠定了基础。
二、常见面试题
Step1: Dropout 📝🔍🎯
-
什么是Dropout?
Dropout是一种在神经网络训练过程中用于防止过拟合的技术。具体来说,它在每次训练迭代中随机关闭网络中的一部分神经元(即设置为0),这样可以防止网络过于依赖任何一个神经元,从而提高其泛化能力。 -
为什么使用Dropout?
使用Dropout的主要原因是防止过拟合。过拟合是指模型在训练数据上表现良好,但在未见过的测试数据上表现较差。Dropout通过随机关闭一部分神经元,使得网络不能过度依赖任何一个神经元,从而提高其泛化能力。 -
如何使用Dropout?
在PyTorch等深度学习框架中,Dropout通常作为一个层添加到网络中。例如,可以在两个全连接层之间添加一个Dropout层。在训练过程中,Dropout层会随机关闭一部分神经元;在测试过程中,所有神经元都会被使用,但其输出会被缩放,以平衡在训练过程中关闭神经元的影响。
Step2: ReLU 📝🔍🎯
-
什么是ReLU?
ReLU(Rectified Linear Unit)是一种非线性激活函数,其公式为f(x) = max(0, x)。也就是说,如果输入大于0,那么输出就是输入本身;如果输入小于或等于0,那么输出就是0。 -
为什么使用ReLU?
ReLU激活函数的主要优点是它能够缓解梯度消失问题,这是因为其正区间的梯度为1,而负区间的梯度为0。此外,ReLU函数的计算效率非常高,只需要判断输入是否大于0即可。 -
如何使用ReLU?
在深度学习框架中,ReLU通常作为一个层添加到网络中,或者作为其他层(如全连接层或卷积层)的激活函数。例如,可以在一个全连接层之后添加一个ReLU层,使得该层的输出通过ReLU函数进行非线性变换。
Step3: 局部响应归一化(Local Response Normalization, LRN) 📝🔍🎯
-
什么是局部响应归一化?
局部响应归一化是一种在神经网络中常见的归一化技术,主要用于卷积神经网络中。它对局部输入值进行归一化,使得神经元的响应在一定范围内保持相对稳定。 -
为什么使用局部响应归一化?
局部响应归一化可以帮助提高神经网络的泛化能力。它实现了一种形式的侧抑制,即在不同核的神经元输出之间创建竞争,这种竞争对于大的活动具有抑制作用。这种机制受到了真实神经元中发现的类型的启发。 -
如何使用局部响应归一化?
局部响应归一化通常作为一个层添加到神经网络中。在这篇论文中,作者在应用ReLU非线性的某些层之后应用了这种归一化。具体来说,对于由应用核i在位置(x, y)计算的神经元的活动ai(x, y),其响应归一化的活动bi(x, y)由以下公式给出:
b i x , y = a i x , y ( k + α ∑ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) ( a j x , y ) 2 ) β bi_{x,y} = \frac{ai_{x,y}}{(k + \alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)} (aj_{x,y})^2)^\beta} bix,y=(k+α∑j=max(0,i−n/2)min(N−1,i+n/2)(ajx,y)2)βaix,y
其中,求和是在相同空间位置的“相邻”核映射上进行的,N是层中核的总数。这里的k、n、α和β都是超参数,其值通过验证集确定。
Step4: 重叠池化(Overlapping Pooling) 📝🔍🎯
-
什么是重叠池化?
池化是卷积神经网络中常用的一种操作,它对邻近的神经元输出进行总结。传统的池化层中,相邻的池化单元总结的邻域是不重叠的。如果我们设置s < z,我们就得到了重叠池化。在这篇论文中,作者在整个网络中使用了s=2和z=3的重叠池化。 -
为什么使用重叠池化?
使用重叠池化可以进一步提高模型的性能。作者发现,与非重叠的池化方案相比,重叠池化方案可以将top-1和top-5的错误率分别降低0.4%和0.3%。 -
如何使用重叠池化?
在深度学习框架中,可以通过设置池化层的参数来实现重叠池化。例如,在PyTorch中,可以通过设置nn.MaxPool2d的kernel_size和stride参数来实现重叠池化。
三、实现深度卷积神经网络的步骤 & 代码 📝🔍🎯
1️⃣ 数据预处理:使用ImageNet数据集,这是一个包含超过1500万张标记的高分辨率图像的数据集,这些图像大约属于22000个类别。对图像进行预处理,包括缩放、裁剪和像素值中心化。
2️⃣ 定义网络结构:定义一个深度卷积神经网络,包含五个卷积层和三个全连接层。使用ReLU作为激活函数。
3️⃣ 初始化参数:初始化网络的权重和偏置参数。权重从零均值的高斯分布中初始化,偏置初始化为常数。
4️⃣ 训练网络:使用随机梯度下降和反向传播算法训练网络。设置批量大小为128,动量为0.9,权重衰减为0.0005。
5️⃣ 防止过拟合:使用数据增强和Dropout技术防止过拟合。
6️⃣ 测试网络:在测试集上评估网络的性能,计算分类错误率。
# 导入所需的库
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 数据预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载ImageNet数据集
train_dataset = datasets.ImageNet(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.ImageNet(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=False)
# 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2)
self.relu = nn.ReLU(inplace=True)
# ... 定义其他层 ...
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
# ... 定义前向传播过程 ...
return x
# 初始化网络
model = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005)
# 训练网络
for epoch in range(10): # 迭代10次
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999: # 每2000个批次打印一次
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 测试网络
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))
四、十个问题 & 回答 📝🔍🎯
1️⃣ Q1 论文试图解决什么问题?
这篇论文试图解决的问题是如何使用深度学习,特别是深度卷积神经网络(CNN),来提高大规模图像分类任务的性能。
2️⃣ Q2 这是否是一个新的问题?
这并不是一个新的问题。图像分类一直是计算机视觉领域的一个重要问题。然而,这篇论文是第一次在大规模数据集(如ImageNet)上使用深度卷积神经网络进行图像分类。
3️⃣ Q3 这篇文章要验证一个什么科学假设?
这篇文章的科学假设是深度卷积神经网络可以在大规模图像分类任务上取得显著的成果。
4️⃣ Q4 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关的研究主要集中在深度学习和计算机视觉领域,特别是使用深度学习方法进行图像分类的研究。这些研究可以归类为深度学习在计算机视觉应用的研究。值得关注的研究员包括Yann LeCun,Geoffrey Hinton和Andrew Ng等。
5️⃣ Q5 论文中提到的解决方案之关键是什么?
论文中提到的解决方案的关键是设计和实现一个深度卷积神经网络,并在大规模数据集上进行训练。这个网络包含一些新颖和不寻常的特性,如ReLU非线性,多GPU训练,局部响应归一化,重叠池化等,这些都有助于提高其性能并减少训练时间。
6️⃣ Q6 论文中的实验是如何设计的?
论文中的实验主要包括在ImageNet数据集上训练深度卷积神经网络,并在测试集上评估其性能。作者还在ILSVRC-2010和ILSVRC-2012比赛中提交了他们的模型,并取得了显著的成果。
7️⃣ Q7 用于定量评估的数据集是什么?代码有没有开源?
用于定量评估的数据集是ImageNet,这是一个包含超过1500万张标记的高分辨率图像的数据集,这些图像大约属于22000个类别。论文中没有明确提到代码是否开源,但他们提到了他们编写了一个高度优化的GPU实现的2D卷积和训练卷积神经网络的所有其他操作的代码。
8️⃣ Q8 论文中的实验及结果有没有很好地支持需要验证的科学假设?
是的,论文中的实验和结果很好地支持了需要验证的科学假设。他们的深度卷积神经网络在ImageNet LSVRC-2010比赛中的图像分类任务上取得了显著的成果,其top-5测试错误率为15.3%,相比第二名的26.2%有显著的提升。
9️⃣ Q9 这篇论文到底有什么贡献?
这篇论文的贡献主要包括:
- 在ImageNet的子集上训练了迄今为止最大的一个卷积神经网络,并在ILSVRC-2010和ILSVRC-2012比赛中取得了迄今为止报告的最好结果。
- 作者编写了一个高度优化的GPU实现的2D卷积和训练卷积神经网络的所有其他操作的代码。
- 他们的网络包含一些新颖和不寻常的特性,这些特性提高了其性能并减少了其训练时间。
🔟 Q10 下一步呢?有什么工作可以继续深入?
下一步的工作可能包括进一步优化网络结构和训练策略,以提高分类性能。例如,可以尝试使用更复杂的数据增强技术,或者尝试使用新的正则化方法来防止过拟合。此外,还可以尝试将这个深度卷积神经网络应用到其他类型的视觉任务中,如物体检测和语义分割。
五、每页摘要
第一页摘要 📝🔍🎯
1️⃣ 本文的主题是使用深度卷积神经网络对ImageNet进行分类。作者训练了一个大型的深度卷积神经网络,用于将ImageNet LSVRC-2010比赛中的120万高分辨率图像分类到1000个不同的类别中。在测试数据上,他们实现了37.5%的top-1错误率和17.0%的top-5错误率,这比以前的最先进水平要好得多。神经网络有6000万个参数和650,000个神经元,包括五个卷积层(其中一些后面跟着最大池化层)和三个全连接层,最后是一个1000路的softmax。
2️⃣ 为了加快训练速度,他们使用了非饱和神经元和卷积运算的高效GPU实现。为了减少全连接层的过拟合,他们采用了一种名为“dropout”的最近开发的正则化方法,这证明是非常有效的。他们还将这个模型的一个变体输入到ILSVRC-2012比赛中,并实现了15.3%的获胜top-5测试错误率,相比之下,第二名的错误率为26.2%。
3️⃣ 对象识别的当前方法主要使用机器学习方法。为了提高性能,我们可以收集更大的数据集,学习更强大的模型,并使用更好的防止过拟合的技术。直到最近,标记图像的数据集相对较小,大约有几万张图像。简单的识别任务可以用这种大小的数据集很好地解决,特别是如果它们被标签保留的转换增强。例如,MNIST数字识别任务的当前最佳错误率(<0.3%)接近人类的表现。
4️⃣ 但是,在现实环境中的对象表现出相当大的变化,所以要学习识别它们,就需要使用更大的训练集。实际上,小图像数据集的不足已经被广泛认识到,但是直到最近,才有可能收集到带有数百万图像的标记数据集。新的更大的数据集包括LabelMe,它包括数十万张完全分割的图像,以及ImageNet,它包括超过1500万张标记的高分辨率图像,分布在超过22,000个类别中。
第二页摘要 📝🔍🎯
1️⃣ 尽管卷积神经网络(CNN)具有吸引人的特性,并且其局部架构相对高效,但是将其大规模应用于高分辨率图像仍然过于昂贵。幸运的是,当前的GPU,配合高度优化的2D卷积实现,足够强大,可以促进训练足够大的CNN,而像ImageNet这样的最近的数据集包含足够的标记示例,可以训练这样的模型,而不会严重过拟合。
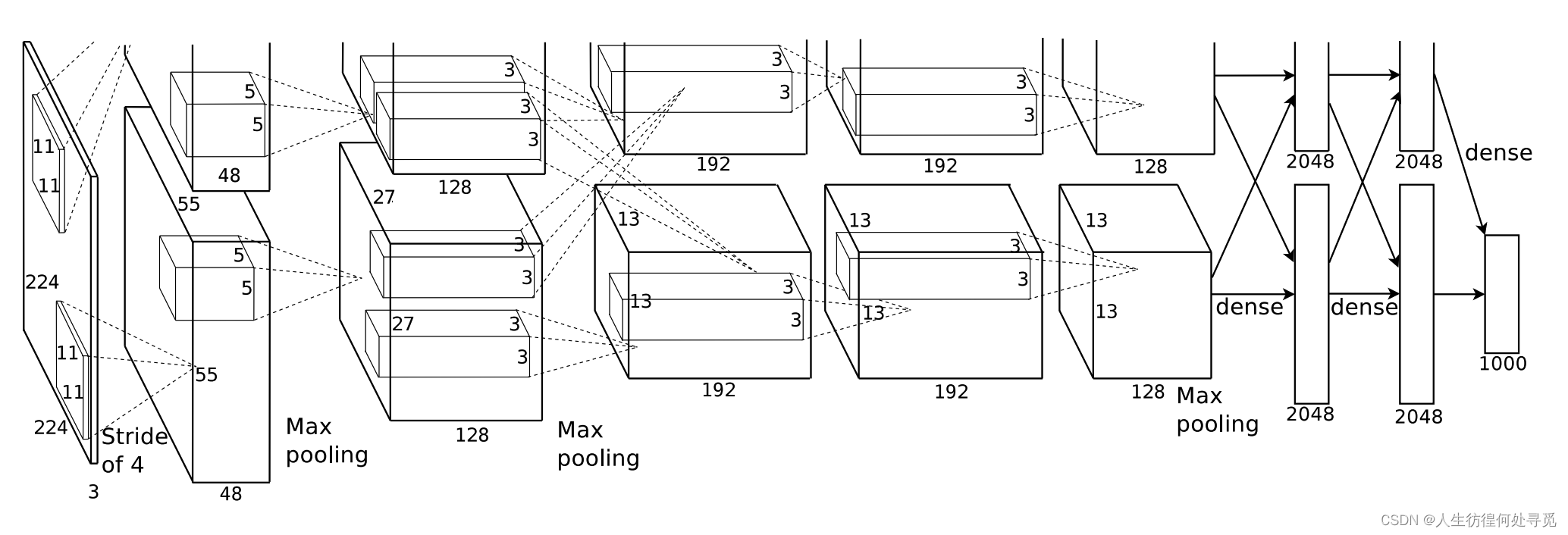
2️⃣ 本文的具体贡献如下:我们在ImageNet的子集上训练了迄今为止最大的卷积神经网络之一,这些子集用于ILSVRC-2010和ILSVRC-2012比赛,并在这些数据集上取得了迄今为止最好的结果。我们编写了一个高度优化的GPU实现2D卷积和训练卷积神经网络中所有其他操作的程序,我们将其公开提供。我们的网络包含一些新颖和不寻常的特性,这些特性提高了其性能并减少了其训练时间,这些将在第3节中详细介绍。我们的网络的大小使过拟合成为一个重要问题,即使有120万个标记的训练示例,所以我们使用了几种有效的防止过拟合的技术,这些将在第4节中描述。我们的最终网络包含五个卷积层和三个全连接层,这种深度似乎很重要:我们发现,去掉任何卷积层(每个卷积层包含的模型参数不超过1%)都会导致性能下降。
3️⃣ 最后,网络的大小主要受到当前GPU可用内存量和我们愿意容忍的训练时间的限制。我们的网络在两个GTX 580 3GB GPU上训练需要五到六天。我们所有的实验都表明,我们的结果可以通过等待更快的GPU和更大的数据集变得可用来改进。
4️⃣ ImageNet是一个包含超过1500万张标记的高分辨率图像的数据集,大约属于22,000个类别。这些图像是从网络上收集的,并由使用Amazon的Mechanical Turk众包工具的人类标签者进行标记。从2010年开始,作为Pascal视觉对象挑战的一部分,每年都会举办一个名为ImageNet大规模视觉识别挑战(ILSVRC)的比赛。
第三页摘要 📝🔍🎯
1️⃣ ReLU非线性:神经元的输出通常以 f ( x ) = t a n h ( x ) f(x) = tanh(x) f(x)=tanh(x)或 f ( x ) = ( 1 + e − x ) − 1 f(x) = (1 + e^{-x})^{-1} f(x)=(1+e−x)−1的形式建模。在使用梯度下降进行训练时,这些饱和非线性比非饱和非线性 f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x)慢得多。我们将这种非线性的神经元称为修正线性单元(ReLU)。具有ReLU的深度卷积神经网络训练速度比具有tanh单元的网络快几倍。这在图1中得到了证明,该图显示了一个特定的四层卷积网络在CIFAR-10数据集上达到25%训练错误率所需的迭代次数。这个图表明,如果我们使用传统的饱和神经元模型,我们将无法对这样大的神经网络进行实验。
2️⃣ 在多个GPU上训练:单个GTX 580 GPU只有3GB的内存,这限制了可以在其上训练的网络的最大大小。事实证明,120万个训练示例足以训练过大以至于无法适应一个GPU的网络。因此,我们将网络分布在两个GPU上。当前的GPU特别适合跨GPU并行化,因为它们能够直接读取和写入彼此的内存,而无需通过主机机器内存。我们采用的并行化方案基本上将一半的内核(或神经元)放在每个GPU上,还有一个额外的技巧:GPU只在某些层中通信。这意味着,例如,第3层的内核从第2层的所有内核映射中获取输入。然而,第4层的内核只从那些位于同一GPU上的第3层内核映射中获取输入。选择连接模式是交叉验证的问题,但这允许我们精确调整通信量,直到它是可接受的计算量的一部分。这种结果的架构在某种程度上类似于Cireșan等人使用的“柱状”CNN,只是我们的柱状体不是独立的。这种方案将我们的top-1和top-5错误率分别降低了1.7%和1.2%,与在一个GPU上训练的具有每个卷积层一半内核的网络相比。两个GPU的网络训练时间稍微短于一个GPU的网络。
第四页摘要 📝🔍🎯
1️⃣ 局部响应归一化:ReLU具有一个可取的特性,即它们不需要输入归一化来防止它们饱和。如果至少有一些训练样本对ReLU产生正输入,那么在该神经元中就会发生学习。然而,我们仍然发现以下的局部归一化方案有助于泛化。通过应用在位置
(
x
,
y
)
(x, y)
(x,y)的核
i
i
i,然后应用ReLU非线性计算出神经元的活动
a
i
x
,
y
ai_{x,y}
aix,y,响应归一化的活动
b
i
x
,
y
bi_{x,y}
bix,y由下式给出:
b
i
x
,
y
=
a
i
x
,
y
(
k
+
∑
j
=
max
(
0
,
i
−
n
/
2
)
min
(
N
−
1
,
i
+
n
/
2
)
(
a
j
x
,
y
)
2
)
β
bi_{x,y} = \frac{ai_{x,y}}{(k + \sum_{j=\max(0,i-n/2)}^{\min(N-1,i+n/2)} (aj_{x,y})^2)^{\beta}}
bix,y=(k+∑j=max(0,i−n/2)min(N−1,i+n/2)(ajx,y)2)βaix,y
其中,求和运行在同一空间位置的
n
n
n个“相邻”核映射上,
N
N
N是层中的总核数。这种响应归一化实现了一种形式的侧抑制,受到真实神经元中发现的类型的启发,在使用不同核计算的神经元输出之间创建竞争。
2️⃣ 重叠池化:CNN中的池化层总结了同一核映射中相邻神经元组的输出。传统上,相邻池化单元总结的邻域不重叠。更准确地说,池化层可以被认为是由间隔 s s s像素的池化单元的网格组成,每个池化单元总结了以池化单元位置为中心的 z × z z \times z z×z邻域。如果我们设置 s = z s=z s=z,我们得到CNN中常用的传统局部池化。如果我们设置 s < z s < z s<z,我们得到重叠池化。这就是我们在整个网络中使用的,其中 s = 2 s=2 s=2, z = 3 z=3 z=3。这种方案将我们的top-1和top-5错误率分别降低了0.4%和0.3%,与产生等效维度输出的非重叠方案 s = 2 s=2 s=2, z = 2 z=2 z=2相比。我们通常在训练过程中观察到,具有重叠池化的模型发现过拟合稍微困难一些。
3️⃣ 整体架构:现在我们准备描述我们的CNN的整体架构。如图2所示,网络包含有权重的八层;前五层是卷积层,剩下的三层是全连接层。最后一个全连接层的输出被送入一个1000路的softmax,它产生了对1000个类标签的分类。
第五页摘要 📝🔍🎯
1️⃣ 整体架构(续):第二个卷积层接收第一个卷积层的(响应归一化和池化)输出,并用256个5x5x48的核进行滤波。第三、四、五个卷积层彼此连接,中间没有任何池化或归一化层。第三个卷积层有384个3x3x256的核,连接到第二个卷积层的(归一化、池化)输出。第四个卷积层有384个3x3x192的核,第五个卷积层有256个3x3x192的核。全连接层每层有4096个神经元。
2️⃣ 减少过拟合:我们的神经网络架构有6000万个参数。尽管ILSVRC的1000个类使每个训练样例对从图像到标签的映射施加了10位的约束,但这证明不足以学习如此多的参数而不会出现相当大的过拟合。下面,我们描述了我们如何对抗过拟合的两种主要方式。
3️⃣ 数据增强:减少图像数据过拟合的最简单和最常见的方法是使用保留标签的变换来人工扩大数据集(例如,[25, 4, 5])。我们采用两种不同形式的数据增强,这两种形式都允许从原始图像生成变换后的图像,计算量非常小,因此变换后的图像不需要存储在磁盘上。在我们的实现中,变换后的图像在CPU上的Python代码中生成,而GPU正在对上一批图像进行训练。所以这些数据增强方案实际上是计算上免费的。
4️⃣ 数据增强的第一种形式包括生成图像的平移和水平反射。我们通过从256x256的图像中提取随机的224x224的块(及其水平反射),并在这些提取的块上训练我们的网络。这使我们的训练集的大小增加了2048倍,尽管结果的训练样例当然是高度相关的。没有这个方案,我们的网络会遭受严重的过拟合,这将迫使我们使用更小的网络。在测试时,网络通过提取五个224x224的块(四个角块和中心块)以及它们的水平反射(因此总共有十个块),并对网络的softmax层对这十个块做出的预测进行平均,来进行预
第六页摘要 📝🔍🎯
1️⃣ 数据增强(续):数据增强的第二种形式包括改变训练图像中RGB通道的强度。具体来说,我们对ImageNet训练集中的RGB像素值进行主成分分析(PCA)。对于每个训练图像,我们添加主成分的倍数,倍数与相应的特征值成正比,乘以一个从均值为零,标准差为0.1的高斯分布中抽取的随机变量。因此,对于每个RGB图像像素
I
x
y
=
[
I
R
x
y
,
I
G
x
y
,
I
B
x
y
]
T
I_{xy} = [I_{Rxy}, I_{Gxy}, I_{Bxy}]^T
Ixy=[IRxy,IGxy,IBxy]T,我们添加以下数量:
[
p
1
,
p
2
,
p
3
]
[
α
1
λ
1
,
α
2
λ
2
,
α
3
λ
3
]
T
[p_1, p_2, p_3][\alpha_1 \lambda_1, \alpha_2 \lambda_2, \alpha_3 \lambda_3]^T
[p1,p2,p3][α1λ1,α2λ2,α3λ3]T
其中,
p
i
p_i
pi和
λ
i
\lambda_i
λi分别是RGB像素值的3x3协方差矩阵的第
i
i
i个特征向量和特征值,
α
i
\alpha_i
αi是前述随机变量。每个
α
i
\alpha_i
αi只为特定训练图像的所有像素绘制一次,直到该图像再次用于训练,此时将重新绘制。这种方案大致捕获了自然图像的一个重要属性,即物体身份对照明的强度和颜色的变化是不变的。这种方案将top-1错误率降低了超过1%。
2️⃣ Dropout:结合许多不同模型的预测是减少测试错误的一种非常成功的方法,但对于已经需要几天时间进行训练的大型神经网络来说,这似乎太昂贵了。然而,有一种非常高效的模型组合版本,训练时的成本只有大约两倍。这种最近引入的技术,称为“dropout”,包括以0.5的概率将每个隐藏神经元的输出设置为零。以这种方式“丢弃”的神经元在前向传播中不做贡献,也不参与反向传播。所以每次输入被呈现时,神经网络都会采样一个不同的架构,但所有这些架构都共享权重。这种技术减少了神经元的复杂共适应,因为一个神经元不能依赖于特定其他神经元的存在。因此,它被迫学习更强大的特征,这些特征与其他神经元的许多不同随机子集一起使用是有用的。在测试时,我们使用所有的神经元
第七页摘要 📝🔍🎯
1️⃣ 训练细节:我们使用随机梯度下降进行模型训练,批量大小为128个样本,动量为0.9,权重衰减为0.0005。我们发现这小量的权重衰减对模型学习是重要的。换句话说,权重衰减在这里不仅仅是一个正则化器:它减少了模型的训练误差。权重
w
w
w的更新规则为:
v
i
+
1
:
=
0.9
×
v
i
−
0.0005
×
η
×
w
i
−
η
×
∂
L
∂
w
∣
w
i
v_{i+1} := 0.9 \times v_i - 0.0005 \times \eta \times w_i - \eta \times \frac{\partial L}{\partial w}\Bigg|_{w_i}
vi+1:=0.9×vi−0.0005×η×wi−η×∂w∂L
wi
w
i
+
1
:
=
w
i
+
v
i
+
1
w_{i+1} := w_i + v_{i+1}
wi+1:=wi+vi+1
其中,
i
i
i是迭代索引,
v
v
v是动量变量,
η
\eta
η是学习率,
∂
L
∂
w
∣
w
i
\frac{\partial L}{\partial w}\Bigg|_{w_i}
∂w∂L
wi是在
w
i
w_i
wi处对目标函数关于
w
w
w的导数的平均值。我们将每一层的权重从零均值高斯分布中初始化,标准差为0.01。我们将第二、四、五个卷积层以及全连接隐藏层的神经元偏置初始化为常数1。这种初始化加速了学习的早期阶段,为ReLU提供了正输入。我们将其余层的神经元偏置初始化为常数0。
2️⃣ 结果:我们在ILSVRC-2010上的结果总结在表1中。我们的网络在测试集上的top-1和top-5错误率分别为37.5%和17.0%。在ILSVRC-2010比赛中,最好的性能是47.1%和28.2%,使用的方法是平均六个稀疏编码模型的预测,这些模型在不同的特征上进行训练。此后,最好的公布结果是45.7%和25.7%,使用的方法是平均两个分类器的预测,这两个分类器在两种类型的密集采样特征上计算的Fisher向量(FVs)上进行训练。
3️⃣ 我们还将我们的模型输入到ILSVRC-2012比赛中,并在表2中报告我们的结果。由于ILSVRC-2012测试集的标签不是公开可用的,我们不能报告所有我们尝试的模型的测试错误率。在本段的其余部分,我们将验证和测试错误率互换使用,因为在我们的经验中,它们的差异不超过0.1%(见表2)。本文描述的CNN的top-5错误率为18.2%。














 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









