









 文章介绍了LlamaIndex,一种利用RAG技术处理私人或特定领域数据的数据框架,帮助AI应用改进对非公开信息的理解。文章详细讲解了LlamaIndex的原理、使用场景以及其提供的服务,包括数据连接、索引、引擎和应用集成等组件。
文章介绍了LlamaIndex,一种利用RAG技术处理私人或特定领域数据的数据框架,帮助AI应用改进对非公开信息的理解。文章详细讲解了LlamaIndex的原理、使用场景以及其提供的服务,包括数据连接、索引、引擎和应用集成等组件。
认识并使用LlamaIndex
一、认识LlamaIndex
1、是什么
- Llama Index是一个数据框架,辅助基于LLM的应用,去消化理解、结构化、获取私人或特定领域数据。【本质是RAG的一个落地产物。】官方文档
2、为什么要搞Llama Index?
- 一句话:AI应用单纯靠LLM,在一些特定问题上,表现不佳。
例如,我们在电商领域沉淀了很多领域知识,但这些信息并没有被LLM训练过,这使得LLM在回答电商领域的特定问题时,表现不佳。
(1)LLM学习过的信息:大量公开数据,如维基百科、邮件列表、教科书、源代码等。
(2)LLM大概率没有学习过的信息:私人或特定领域数据。
- 因此,为了解决这个问题,我们需要一个数据框架,能够去消化理解、结构化、获取私人或特定领域数据。
3、怎么搞Llama Index?
3.1 方案1:用你的数据对LLM进行微调(fine-tune)
- 缺点:
- LLM的训练费用高。
- 由于训练成本,难以用最新信息更新LLM。
- 可解释性差。当咱向LLM提问时,它如何得出答案并不明显。
3.2 方案2:检索增强生成(RAG)技术
- 思想:
- (1)首先从你的数据源中检索信息
- (2)然后把它添加到你的问题作为上下文 【prompt】
- (3)最后让LLM基于丰富的prompt来回答
- RAG克服了微调方法的所有三个弱点:
- (1)无需训练,所以成本低。【其实成本并不低,因为需要优质的数据源,这都是要靠人力堆起来的】
- (2)可以不断提供新数据,供信息检索。
- (3)LlamaIndex可以向你展示检索到的文档,所以更可信。 【依靠可解释性的工程链路】
4、Llama Index这套数据处理框架能提供什么服务?
4.1 数据连接器(Data connectors)
- 作用:从原始数据源和格式中获取你的现有数据。这些可能是API、PDF、SQL等等。
4.2 数据索引(Data Indexes)
- 作用:将你的数据结构化成中间表达,以便LLM易于消化和高效使用。
4.3 引擎(Engines)
- 作用:为你的数据提供自然语言访问。
- 例如:
- 查询引擎是强大的检索界面,用于知识增强输出。
- 聊天引擎是交谈式界面,用于与你的数据进行多消息的“来回”交互。
- 例如:
4.4 数据代理(Data agents)
- 作用:LLM驱动的知识工作者,通过工具进行增强,从简单的辅助函数到API集成等等。
4.5 应用集成(Application integrations)
- 作用:将LlamaIndex与你的其他生态系统绑定。这可以是LangChain,Flask,Docker,ChatGPT,或者…任何其他东西!
二、使用LlamaIndex
1、通过poetry管理依赖
- macOS,在终端执行:brew install poetry
poetry可以帮助你管理包依赖。
- 对poetry的认知:
当你在项目的根目录下执行 poetry shell命令时,Poetry会在这个目录中寻找一个名为pyproject.toml的文件,这个文件是Poetry用来管理项目配置和依赖的。如果Poetry在当前目录中找到了pyproject.toml文件,它就会知道需要为这个目录下的项目激活虚拟环境。如果没有找到,Poetry通常会报错,提示没有找到Poetry项目。你可以通过输入exit命令或关闭终端来退出虚拟环境。
(1)在Python开发中,通常推荐为每个项目创建一个独立的虚拟环境,这样能够保证每个项目的依赖库之间不会互相干扰。
(2)在虚拟环境被激活的状态下,你使用python或pip命令安装的库都会被安装到这个虚拟环境中,不会影响到其他项目或全局Python环境。
(3)poetry很像java的maven。pyproject.toml类似于maven的pom.xml
2、创建python项目
- 我在目录/Users/…/code/Python3Code/learnAiEngineering/下新建目录:
learn_demo_llama_index - 执行:poetry init
一路回车,生成
pyproject.toml文件后,对文件进行修改。
- 修改
pyproject.toml文件:
[tool.poetry]
name = "learn-demo-llama-index"
version = "0.1.0"
description = ""
authors = ["..."]
[tool.poetry.dependencies]
python = "^3.12"
[[tool.poetry.source]]
name = "aliyun"
url = "https://mirrors.aliyun.com/pypi/simple/"
priority = "default"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
我做了2处修改:
(1)删除readme = "README.md"
(2)换源
3、创建并激活虚拟环境,引入所需的依赖
- 创建并激活虚拟环境:peotry shell
- 引入所需的依赖:
(1)poetry add llama_index
(2)poetry add ‘httpx[socks]’
4、用PyCharm打开项目
-
项目结构
-
Add Python Interpreter
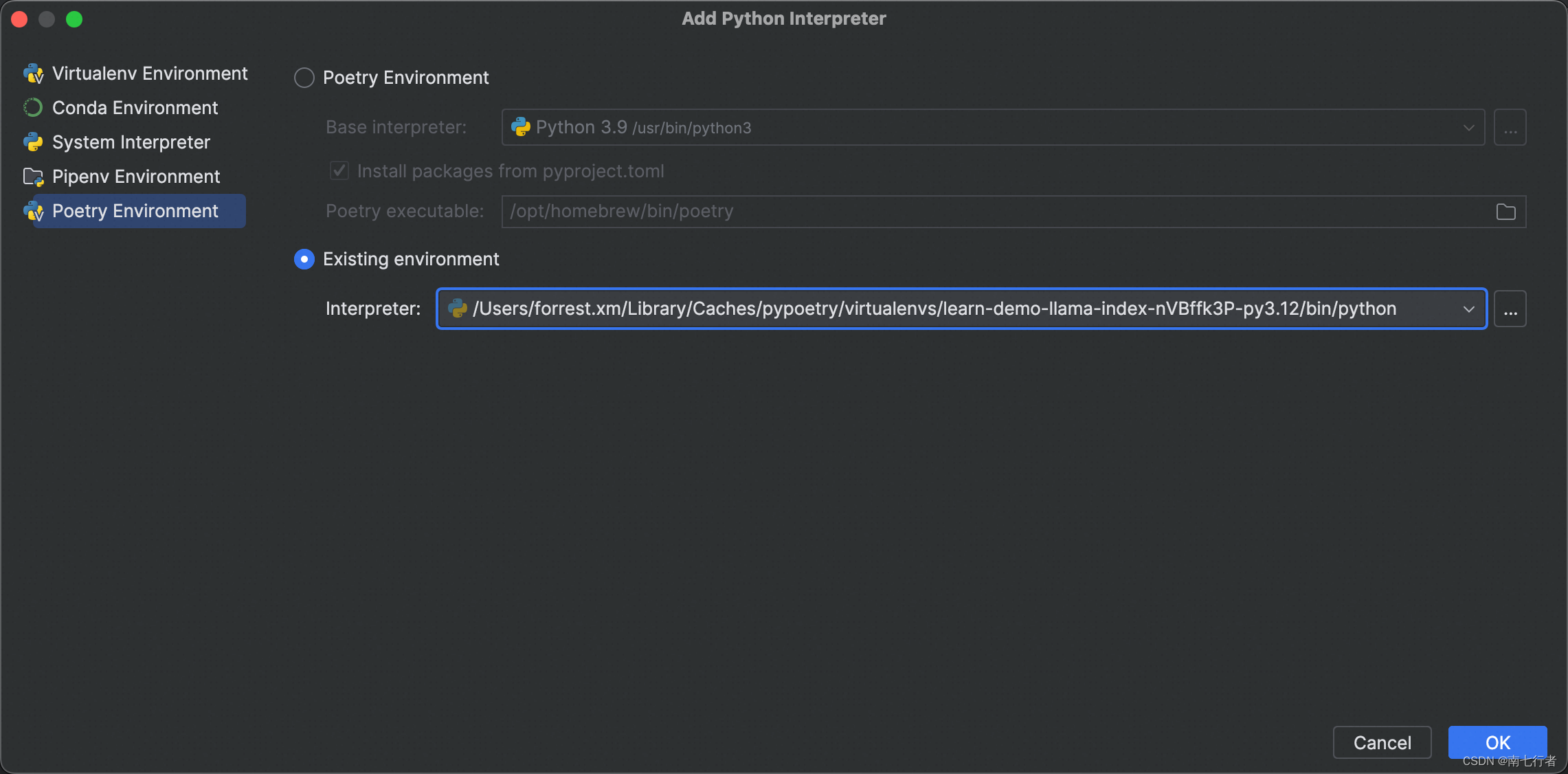
-
准备数据:data/paul_graham_essay.txt
官方文档提供了
- 编码:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
import os
os.environ['http_proxy'] = 'socks5://127.0.0.1:1081'
os.environ['https_proxy'] = 'socks5://127.0.0.1:1081'
os.environ["OPENAI_API_KEY"] = "..."
# Load data and build an index
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# Query your data
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
如果报错:
ModuleNotFoundError: No module named 'pkg_resources'
那么执行:poetry add setuptools
因为 ‘pkg_resources’ 是属于 ‘setuptools’ 的一部分,这将会把 ‘setuptools’ 添加到pyproject.toml文件中,并且安装这个包。
- 结果:The author wrote short stories and also worked on programming, specifically on an IBM 1401 computer in 9th grade.
注意:前提知道“通过代理如何调通openai的api”

















 1818
1818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









