







Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
使用不可靠伪标签的半监督语义分割
论文地址:https://arxiv.org/abs/2203.03884
代码地址 :https://haochen-wang409.github.io/U2PL.
摘要
半监督语义分割的关键是给无标签图像的像素分配适当的伪标签。通常的做法是选择高置信度的预测作为伪标签,但这导致了一个问题,即大部分置信度低的预测可能会被弃用。即使有些像素的预测是模糊的,我们也认为每个像素对模型训练都很重要。一个不可靠的预测可能会与在Top类(即概率最高的类)混淆。然而,它应该确定该像素不属于其余的类。因此,对于那些最不可能的类别,这样的像素可以视为负样本。基于这一发现,我们提出了一个有效的方法来充分利用未标记的数据。具体来说,我们通过预测结果的熵图来分离可靠和不可靠的像素,把每个不可靠的像素推到一个由负样本组成的分类队列中,并利用所有候选像素来训练模型。考虑到训练进程,预测结果越来越精确,因此我们自适应调整区分可靠-不可靠的阈值。在各种基准和训练设置上的实验结果表明,我们的方法优于SOTA方法
动机
现有的监督学习的方法需要大量的有标注数据,但是标注数据需要在实际中需要大量成本。因此半监督学习语义分割应运而生,如何充分利用无标签数据至关重要。现有的方法通过置信度分数过滤预测结果。也就是说,高置信度的预测被用作伪标签,而低置信度的则被丢弃。这可能造成一些像素可能在训练过程中一直没有被学习到,从而导致类别不平衡训练。因此,我们认为要想充分利用无标签数据,每个像素都应该被合理的利用。
创新点
本文提出了了一种使用不可靠伪标签(Using Unreliable Pseudo-Labels, U2PL)的替代方法。
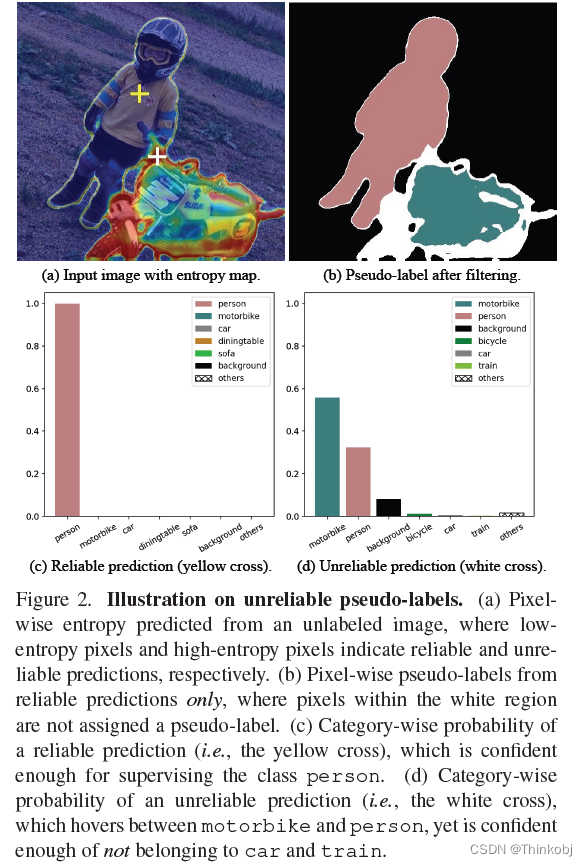
(1)首先,我们观察到,一个不可靠的预测通常只在少数类而不是所有类之间混淆。从未标记的图像中得到预测后,我们使用每像素熵作为度量将所有像素分为两组,即可靠像素和不可靠像素。
(2)所有可靠的预测都被用来获得正的伪标签,而预测不可靠的像素被推入一个充满负样本的内存池。为了避免所有负面伪标签只来自类别的一个子集,我们为每个类别使用了一个队列。这样的设计确保了每个类的负样本数量是平衡的。
(3)考虑到随着模型越来越精确,伪标签的质量越来越高,我们提出了一种自适应调整阈值的策略来划分可靠和不可靠像素。
方法论
总体框架
该框架是使用教师-学生模型的自训练框架(如图3),包括一个CNN编码器h,一个分割头f和一个表示头g。学生模型参数正常更新,老师模型通过学生模型及上一轮的指数滑动平均EMA更新。

总的损失函数为:$L_{s} 表 示 监 督 损 失 , 表示监督损失, 表示监督损失,L_{u} 表 示 无 监 督 损 失 , 表示无监督损失, 表示无监督损失,L_{c} $表示对比损失,
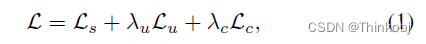
对于有标签图像$x_{l} $使用公式(2)标准的交叉熵优化
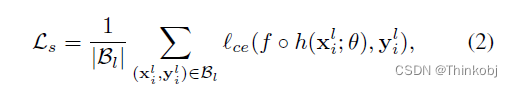
对于有标签图像$x_{u} $使用公式(3)标准的交叉熵优化
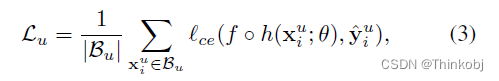
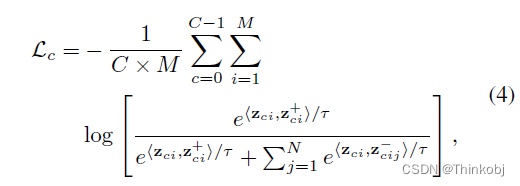
伪标签
熵的计算,其中$p_{ij} $表示Softmax函数
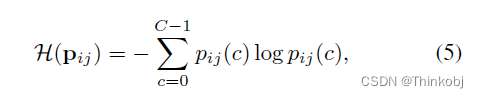
然后,我们将训练时间t时熵在αt上的像素点定义为不可靠伪标签,这种不可靠伪标签丢弃。
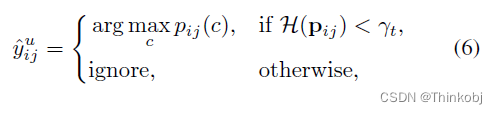
其中γt是通过αt计算而得的,比如:
γt=np.percentile(H.flatten(),100*(1-αt))
动态划分调整
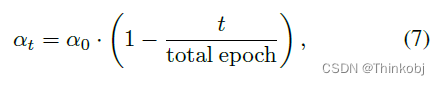
其中α0一开始设置为20%
自适应权重调整
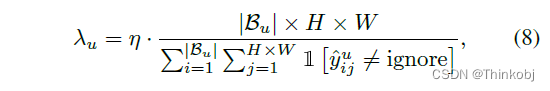
使用不可靠的伪标签
U2PL有三个组成部分,分别是anchor pixels、正候选点(positive candidates)和负候选点(negative candidates)
Anchor Pixels
我们将类c的所有标记候选anchor像素的特征集合表示为$A_{c}^{l} $
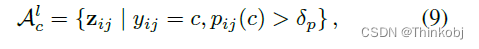
对于无标签数据$A_{c}^{u} $
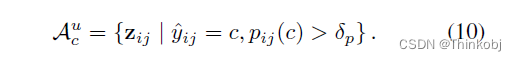
因此,对于类c,所有合格的anchors为
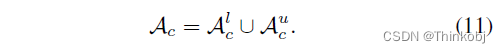
正样本
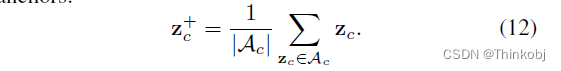
负样本
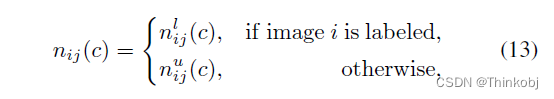
对于第i个标记的图像,c类负样本应满足:(a)不属于c类;(b)难以区分c类及其背景。
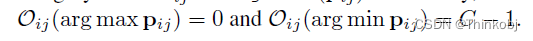
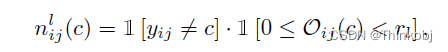
对于第i个无标记的图像,c类负样本应:(a)不可靠;(b)可能不属于c类;©不属于最不可能的类别。
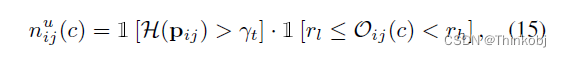
所以负样本的c类是
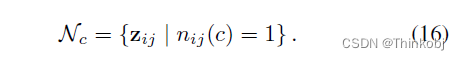

类别级内存池
使用的是先进先出队列
结果
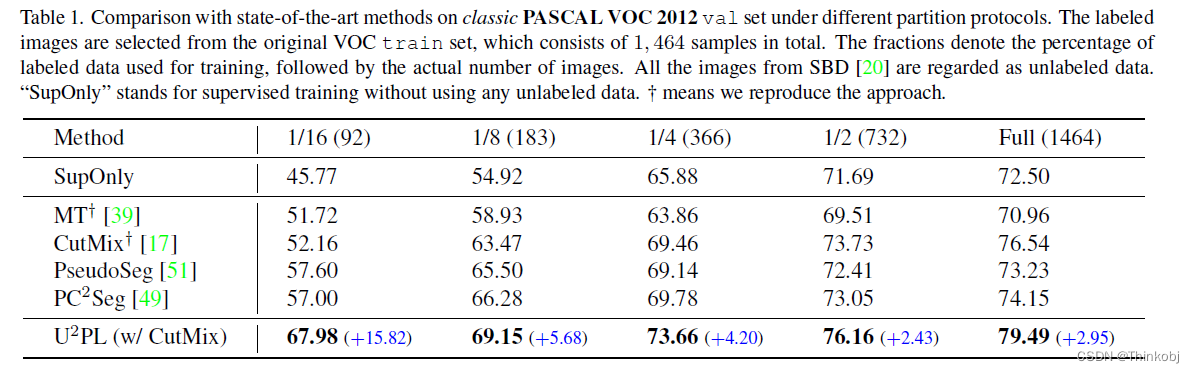
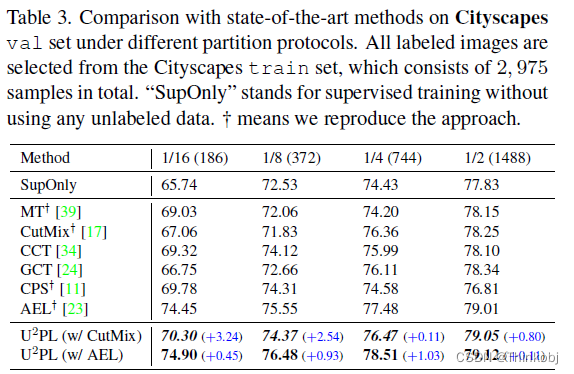
在PASCAL VOC 和 Cityscapes数据集上都得到了最好的结果















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









