







-
BEIT: BERT Pre-Training of Image Transformers
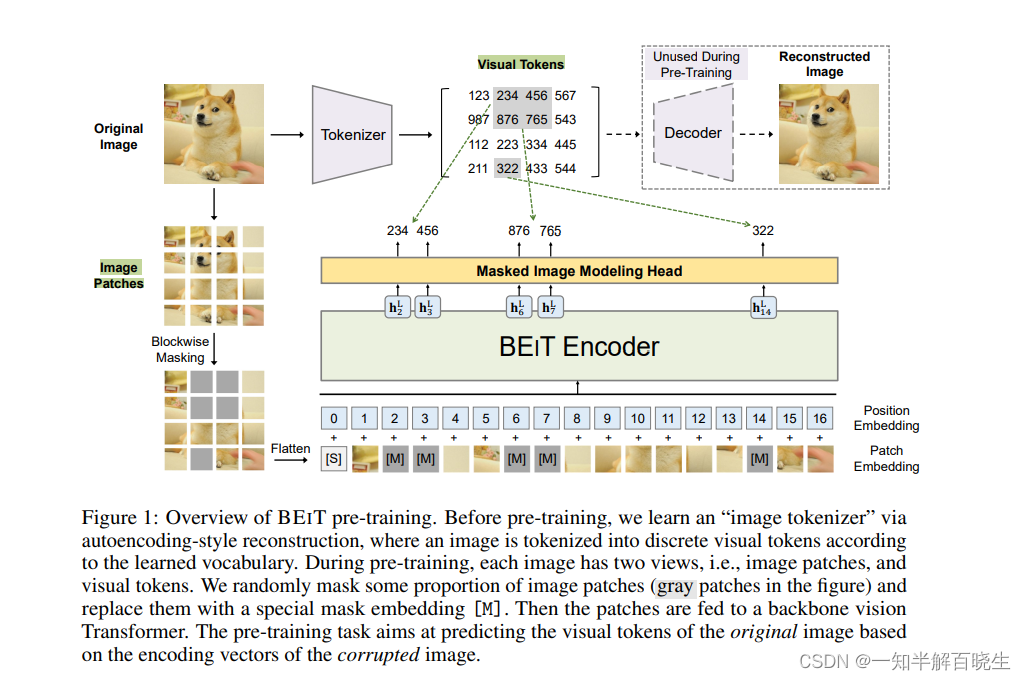
-
An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
VIT中多头注意力机制部分是不同patch互相交互信息的地方,VIT中还专门设置了class token,最终只有class token 被用于最终的分类。
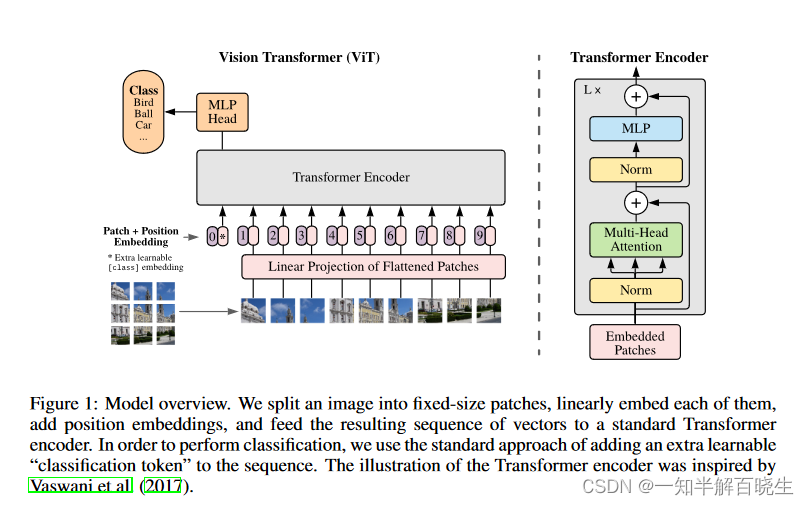
-
Training data-efficient image transformers & distillation through attention
与VIT 不同之处在于,多了个distillation token与class token整好对称。蒸馏策略有硬蒸馏和软蒸馏。
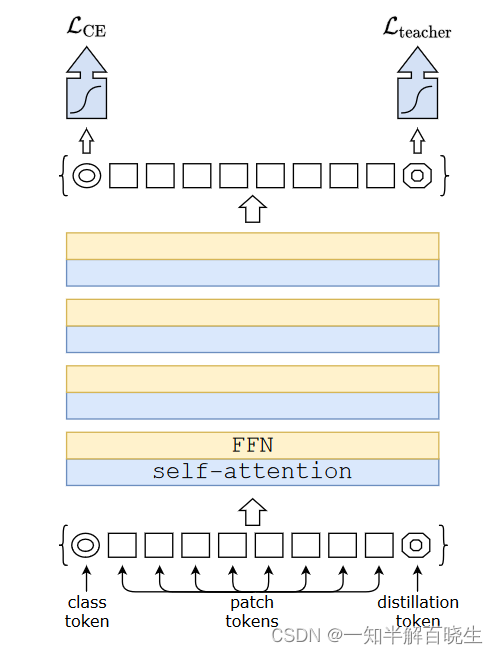















06-17
 1115
1115
1115
08-02
2222
2222
08-09
2448
2448
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









