






在场景理解(Scene understanding)和自动驾驶(Autonomous driving)等应用领域,仅关注分割精度并不能满足应用需要,更应该关注模型推理速度和内存占用等性能。在编解码分割框架上,不同的方法在编码器上一般都是大同小异,但在上采样解码器上各有不同。来自剑桥的研究团队认为,在内存不受限和实时性要求不高的情况下,UNet将编码器中的特征图全部连接到解码器上的操作是合理的,但在场景理解这样的高性能应用实践任务上,这种操作不够高效。基于这种动机,该研究团队提出了SegNet,通过存储最大池化层的位置索引来用于解码器的快速上采样,并且能够补充编码器下采样导致的边界信息损失。提出SegNet的论文为SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation,是基于U形结构设计的、用于实时性语义分割任务的经典网络之一。

SegNet网络结构如下图所示,是一个编解码完全对称的结构。其编码器直接用了VGG16的结构,并将全连接层全部改为卷积层,实际训练时可使用VGG16的预训练权重进行初始化;编码器将13层卷积层分为5组卷积块,每组卷积块之间用最大池化层进行下采样。作为一个对称结构,SegNet解码器也有13层卷积层,同样分为5组卷积块,每组卷积块之间用双线性插值和最大池化位置索引进行上采样,这也是SegNet最大的特色。
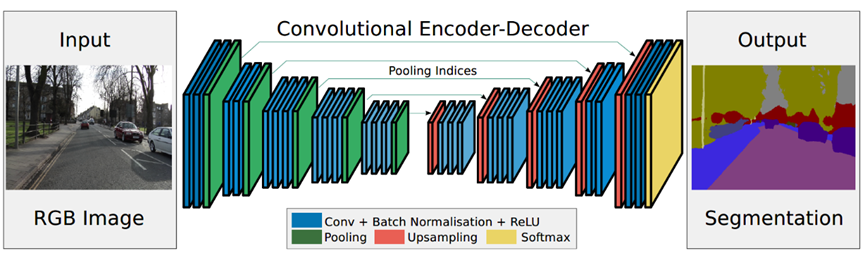
SegNet研究团队认为编码器下采样过程中图像信息损失较多,直接存储所有卷积块的特征图又非常占用内存,因而在SegNet中提出在每一次最大池化下采样前存储最大池化的位置索引(Max-pooling indices),即记住最大池化操作中,最大值在2*2池化窗口中的位置。每个2*2窗口仅需要2 bits内存存储量,这种池化位置索引可用于上采样解码时恢复图像信息。下图给出了SegNet与FCN之间的上采样方法对比。可以观察到,SegNet使用双线性插值并结合最大池化位置索引进行上采样,而FCN则是基于去卷积结合编码器卷积特征图进行上采样。
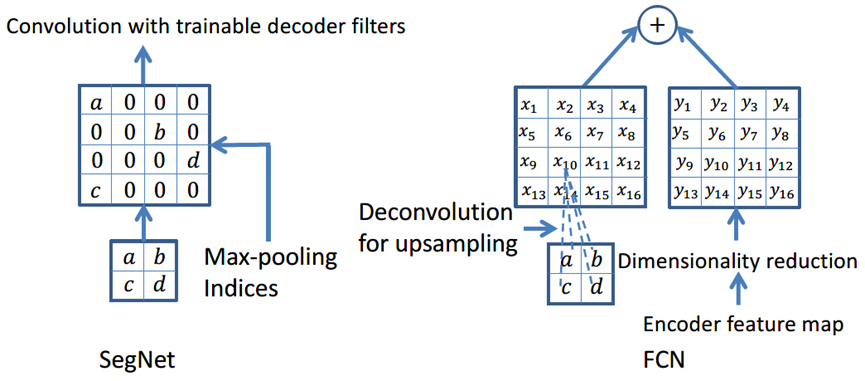
SegNet这种轻量化的上采样方式,不仅能够提升图像边界分割效果,在端到端的实时分割项目中速度也非常快,并且这种结构设计可以配置到任意的编解码网络中,是一种优秀的分割网络设计方式。下述代码给出了SegNet的一个简易的结构实现,因为SegNet解码器的特殊性,我们单独定义了一个解码器类,编码器部分直接使用VGG16的预训练权重层,然后在编解码器基础上搭建SegNet并定义前向计算流程。
# 导入PyTorch相关模块
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as F
from torchvision import models
# 定义SegNet解码器类
class SegNetDec(nn.Module):
def __init__(self, in_channels, out_channels, num_layers):
super().__init__()
layers = [
nn.Conv2d(in_channels, in_channels // 2, 3, padding=1),
nn.BatchNorm2d(in_channels // 2),
nn.ReLU(inplace=True),
]
layers += [
nn.Conv2d(in_channels // 2, in_channels // 2, 3, padding=1),
nn.BatchNorm2d(in_channels // 2),
nn.ReLU(inplace=True),
] * num_layers
layers += [
nn.Conv2d(in_channels // 2, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
]
self.decode = nn.Sequential(*layers)
def forward(self, x):
return self.decode(x)
### 定义SegNet类
class SegNet(nn.Module):
def __init__(self, classes):
super().__init__()
# 编码器使用vgg16预训练权重
vgg16 = models.vgg16(pretrained=True)
features = vgg16.features
self.enc1 = features[0: 4]
self.enc2 = features[5: 9]
self.enc3 = features[10: 16]
self.enc4 = features[17: 23]
self.enc5 = features[24: -1]
# 编码器卷积层不参与训练
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.requires_grad = False
self.dec5 = SegNetDec(512, 512, 1)
self.dec4 = SegNetDec(512, 256, 1)
self.dec3 = SegNetDec(256, 128, 1)
self.dec2 = SegNetDec(128, 64, 0)
self.final = nn.Sequential(*[
nn.Conv2d(64, classes, 3, padding=1),
nn.BatchNorm2d(classes),
nn.ReLU(inplace=True)
])
# 定义SegNet前向计算流程
def forward(self, x):
x1 = self.enc1(x)
e1, m1 = F.max_pool2d(x1, kernel_size=2, stride=2,
return_indices=True)
x2 = self.enc2(e1)
e2, m2 = F.max_pool2d(x2, kernel_size=2, stride=2,
return_indices=True)
x3 = self.enc3(e2)
e3, m3 = F.max_pool2d(x3, kernel_size=2, stride=2,
return_indices=True)
x4 = self.enc4(e3)
e4, m4 = F.max_pool2d(x4, kernel_size=2, stride=2,
return_indices=True)
x5 = self.enc5(e4)
e5, m5 = F.max_pool2d(x5, kernel_size=2, stride=2,
return_indices=True)
def upsample(d):
d5 = self.dec5(F.max_unpool2d(d, m5, kernel_size=2,
stride=2, output_size=x5.size()))
d4 = self.dec4(F.max_unpool2d(d5, m4, kernel_size=2,
stride=2, output_size=x4.size()))
d3 = self.dec3(F.max_unpool2d(d4, m3, kernel_size=2,
stride=2, output_size=x3.size()))
d2 = self.dec2(F.max_unpool2d(d3, m2, kernel_size=2,
stride=2, output_size=x2.size()))
d1 = F.max_unpool2d(d2, m1, kernel_size=2, stride=2,
output_size=x1.size())
return d1
d = upsample(e5)
return self.final(d)往期精彩:














 7494
7494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









