






The IM Algorithm : A variational approach to Information Maximization
由于互信息Mutual Information (MI)是信息传输的衡量标准,我们的核心目标是使MI的下限最大化。利用MI的对称性,MI的等价表述是I(x, y)=H(x)-H(x|y)。由于我们通常对优化MI与p(y|x)的参数有关,而p(x)只是数据分布,我们需要适当地约束H(x|y)。KL散度公式约束
Σ
x
p
(
x
∣
y
)
l
o
g
p
(
x
∣
y
)
−
p
(
x
∣
y
)
l
o
g
q
(
x
∣
y
)
≥
0
\Sigma_x p(x|y) log\ p(x|y) - p(x|y) log\ q(x|y) ≥ 0
Σxp(x∣y)log p(x∣y)−p(x∣y)log q(x∣y)≥0,得到
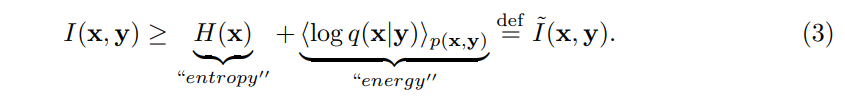
具体推到过程可参考互信息的原理、计算和应用
其中q(x|y)是一个任意的变分分布。如果q(x|y)≡p(x|y),该约束是精确的。这个约束的形式很方便,因为它明确包括了编码器p(y|x)和解码器q(x|y),见图(1)。
当然也可以考虑其他众所周知的MI下限[6],将来对这些不同的方法进行比较会很有趣。然而,我们目前的经验表明,上面考虑的界限在计算上特别方便。由于该约束是基于KL散度的,它相当于用q(x|y)对p(x|y)进行 moment matching approximation。这一事实对解码非常有利,因为模式匹配方法,如均值场理论,通常会被困在许多次优的局部最小值中。更成功的解码算法近似于后验平均值[10]。
The IM algorithm
为了使MI相对于p(y|x, θ)的任何参数θ最大化,我们的目标是推高下限(3)。首先,我们需要选择一类变量分布q(x|y)∈Q,对其来说,能量项是可控的。然后,对于给定的p(x),最大化 I ~ ( X , Y ) \widetilde I(X, Y ) I (X,Y)的自然递归程序是
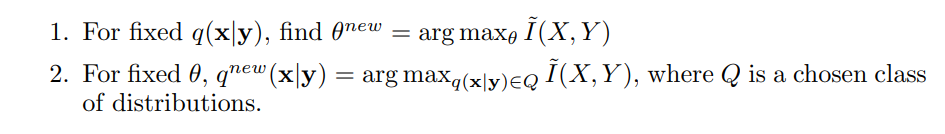
这些步骤反复进行,直到收敛。这个过程类似于(G)EM算法,它使likelihood的下限最大化[9]。区别仅仅在于 "能量 "项的形式。
请注意,如果|y|很大,后验p(x|y)通常会在其模式周围出现急剧的峰值。这将促使人们对后验进行简单的近似q(x|y),显著降低优化的计算复杂性。在实值x的情况下,在 large |y| limit中的一个自然选择是使用高斯函数( a natural choice in the large |y| limit is to use a Gaussian. )。那么,一个简单的近似方法就是使用拉普拉斯近似法对p(x|y)进行协方差元素的计算 [ Σ − 1 ] i j = ∂ 2 l o g p ( x ∣ y ) ∂ x i ∂ x j [\Sigma^{-1}]_{ij}=\frac{\partial^2log\ p(x|y)}{\partial x_i\partial x_j} [Σ−1]ij=∂xi∂xj∂2log p(x∣y)。Inserted in the bound,这将给出一种形式,让人想起费舍尔信息[5]。这里给出的界限可以说比[5]中所述更为普遍和适当,因为,虽然它也倾向于在大量响应的限制下MI的精确值,但它是任何响应维度的原则性约束。
Relation to Conditional Likelihood
考虑一个自动编码器
x
→
y
→
x
~
x→y→\widetilde x
x→y→x
,设想我们希望最大限度地提高重建的
x
~
\widetilde x
x
与x处于相同s状态的概率。
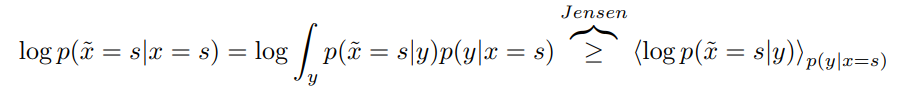
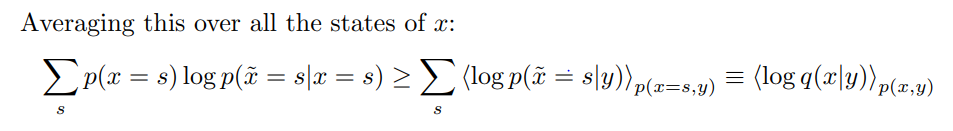
因此,最大化
I
~
(
X
,
Y
)
\widetilde I(X, Y )
I
(X,Y)(对于固定的p(x))与最大化正确重建的概率下限是一样的。这是下限的一个令人放心的属性。尽管我们没有直接最大化MI,但我们也间接地最大化了正确重建的概率–一种自动编码器的形式。
Generalisation to Mixture Decoders
对Jensen不等式的一个直接应用可以得到更一般的结果:
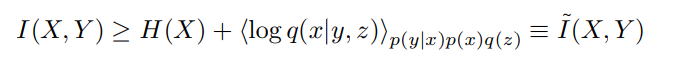
其中q(x|y, z)和q(z)是变分分布。其目的是选择q(x|y, z),以使该约束可被实际计算。该结构如图(1)所示。















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









