







An Analysis of Temporal-Difference Learning with Function Approximation
II. DEFINITION OF TEMPORAL-DIFFERENCE LEARNING
论文
在这一节中,我们精确地定义了时间差分学习的性质,并将其应用于infinite-horizon discounted马尔科夫链的成本–目标函数的近似。虽然该方法适用于具有无限状态空间的马尔科夫链,但我们将注意力限制在状态空间是可数的情况下。这使我们能够使用相对简单的符号;例如,马尔科夫链可以用(无限的)转移概率矩阵来定义,而不是用转移概率核。扩展到一般状态空间的情况下,需要将矩阵符号转化为算子符号,但在其他方面是很简单的。
我们考虑一个 irreducible aperiodic马尔科夫链,其状态位于一个有限或无限空间 S \mathbf S S中。通过用正整数对状态进行索引,我们可以把状态空间看作一个集合 S = { 1 , . . . , n } S=\{1,...,n\} S={1,...,n},其中n可能是无限的。请注意,正整数在这里只是作为索引的作用。特别是,每个状态实际上可能对应于其他一些实体,比如描述物理系统状态的实数向量。在这种情况下,实际的状态空间将由欧氏空间的一个可数子集组成。
马尔可夫链访问的状态序列表示为 { i t ∣ t = 0 , 1 , . . . } \{i_t|t=0,1,...\} {it∣t=0,1,...}。马尔科夫链的动态过程由一个(有限或无限)转移概率矩阵P来描述,其中 p i , j p_{i,j} pi,j代表由状态i转换为状态j的概率( j = i t + 1 j=i_{t+1} j=it+1)。标量 g ( i , j ) g(i,j) g(i,j)代表从i转移为j的代价(cost)。 α ∈ ( 0 , 1 ) \alpha\in(0,1) α∈(0,1)是折扣因子。
关于cost-to-go函数(暂且把它称为值函数,以下值函数即代表cost-to-go函数) J ∗ : S → R J^*:S\rightarrow\mathcal R J∗:S→R的马尔科夫链定义为:

假设这个期望是定义良好的(assuming that this expectation is well-defined)。将 J J J看作一个向量而不是一个函数(如果是无穷大,则其维数为无穷大)。
我们用一个函数逼近器 J ~ : S × R K → R \widetilde J:S\times\mathcal R^K\rightarrow\mathcal R J :S×RK→R来近似 J ∗ : S → R J^*:S\rightarrow\mathcal R J∗:S→R。为了近似值函数,人们通常会选择一个参数向量 r ∈ R K r\in\mathcal R^K r∈RK,以使函数 J ~ ( ⋅ , r ) a n d J ∗ ( ⋅ ) \widetilde J(\cdot,r)\ and\ J^*(\cdot) J (⋅,r) and J∗(⋅)之间的误差最小。
假设我们观察到一串根据转移概率矩阵P生成的状态 i t i_t it,t时刻,参数向量r的值为 r t r_t rt。我们定义了由 i t i_t it到 i t + 1 i_{t+1} it+1转移对应的时间差分 d t d_t dt

对于 t = 0 , 1 , . . . , t=0,1,..., t=0,1,...,,时间差分学习方法根据以下公式更新 r t r_t rt:

r 0 r_0 r0为随机初始化向量, γ t \gamma_t γt为一系列的步长标量, λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ∈[0,1],向量 ∇ J ~ ( i , r ) \nabla\widetilde J(i,r) ∇J (i,r)是关于r的偏导数。由于时间差分学习实际上是一个连续的算法,参数为 λ \lambda λ,它通常被称为TD( λ \lambda λ)。
在线性函数逼近器的特殊情况下,函数 J ~ \widetilde J J 采用这种形式

r = ( r ( 1 ) , . . . , r ( K ) ) r=(r(1),...,r(K)) r=(r(1),...,r(K))为参数向量,每一个 ϕ k \phi_k ϕk是定义在状态空间S里的固定的标量函数(fixed scalar function)。 ϕ k \phi_k ϕk可以看成是基函数(basis functions) (或者是维度为|S|的向量 ),每一个 r ( k ) r(k) r(k)可以看作是相关的权重。
用 ϕ ′ ( i ) = ( ϕ 1 ( i ) , . . . , ϕ K ( i ) ) \phi'(i)=(\phi_1(i),...,\phi_K(i)) ϕ′(i)=(ϕ1(i),...,ϕK(i))来定义vector-valued function向量值函数 ϕ : S → R K \phi:S\rightarrow\mathcal R^K ϕ:S→RK。有了这个符号,近似值也可以写成这样的形式

Φ \Phi Φ可以被看成是一个 ∣ S ∣ × K |S|\times K ∣S∣×K的矩阵,第k列等于 ϕ k \phi_k ϕk

注意这里的梯度向量是

其中 ∇ J ~ ( r ) \nabla\widetilde J(r) ∇J (r)是雅可比矩阵,第i列为 ∇ J ~ ( i , r ) \nabla\widetilde J(i,r) ∇J (i,r)。
对于线性函数逼近器,通过定义维数为K的eligibility vectors资格向量序列,得到TD( λ \lambda λ)更一般的表示

使用这种新符号,TD( λ \lambda λ)更新由

资格向量可根据下式更新

初始化 z − 1 = 0 z_{-1}=0 z−1=0
在接下来的几节中,我们将重点讨论与线性函数逼近器一起使用的时间差学习。只有在第X节中,我们才回到非线性函数逼近器的更一般的背景。
III. UNDERSTANDING TEMPORAL-DIFFERENCE LEARNING
时差学习起源于强化学习领域。在最初的设定中,通常采用的观点是,该算法涉及 “回顾过去,纠正以前的预测”。在这种情况下,资格向量跟踪参数向量应该如何调整,以便在观察到时间差分 d t d_t dt时适当地修改先前的预测。在本文中,我们采取了一种不同的观点,即研究算法的 "steady-state "行为,并认为这表征了参数向量的长期演变。在本节的其余部分,我们介绍了TD( λ \lambda λ),并在线性函数逼近器的背景下提供了它所导致的分析概述。我们的目标是传达一些关于算法如何工作的直觉,本着这种精神,我们将讨论保持在一个非正式的水平上,省略了技术假设和其他需要正式证明我们的statements的细节。这些技术性问题将在随后的章节中讨论,在这些章节中会提出正式的证明。
A. Inner Product Space Concepts and Notation
我们首先介绍一些符号,这些符号将使我们在这里的讨论以及本文后面的分析更加简洁。设
π
(
1
)
,
.
.
.
,
π
(
n
)
\pi(1),...,\pi(n)
π(1),...,π(n)表示过程
i
t
i_t
it的平稳概率。我们假设对于
i
∈
S
,
π
(
i
)
>
0
i\in S,\pi(i)>0
i∈S,π(i)>0。定义D为对角线为
π
(
1
)
,
.
.
.
,
π
(
n
)
\pi(1),...,\pi(n)
π(1),...,π(n)的
n
×
n
n\times n
n×n对角矩阵。很容易看出 满足了内积的要求(satisfies the requirements for an inner product)。用
∣
∣
⋅
∣
∣
D
=
<
⋅
,
⋅
>
D
||\cdot||_D=\sqrt{<\cdot,\cdot>_D}
∣∣⋅∣∣D=<⋅,⋅>D表示相关内积空间上的范数,向量的集合
{
J
∈
R
n
∣
∣
∣
J
∣
∣
D
<
∞
}
\{J\in\mathcal R^n|\ ||J||_D<\infin\}
{J∈Rn∣ ∣∣J∣∣D<∞}用
L
2
(
S
,
D
)
L_2(S,D)
L2(S,D)表示。后面我们会证明
J
∗
J^*
J∗ lies in
L
2
(
S
,
D
)
L_2(S,D)
L2(S,D)。关于符号,我们也将继续使用
∣
∣
⋅
∣
∣
||\cdot||
∣∣⋅∣∣,不加下标,来表示有限维向量上的欧几里得范数或有限矩阵上的Euclidean-induced norm。(也就是是,对应矩阵A,我们有
∣
∣
A
∣
∣
=
m
a
x
∣
∣
x
∣
∣
=
1
∣
∣
A
x
∣
∣
||A||=max_{||x||=1}||Ax||
∣∣A∣∣=max∣∣x∣∣=1∣∣Ax∣∣)。
满足了内积的要求(satisfies the requirements for an inner product)。用
∣
∣
⋅
∣
∣
D
=
<
⋅
,
⋅
>
D
||\cdot||_D=\sqrt{<\cdot,\cdot>_D}
∣∣⋅∣∣D=<⋅,⋅>D表示相关内积空间上的范数,向量的集合
{
J
∈
R
n
∣
∣
∣
J
∣
∣
D
<
∞
}
\{J\in\mathcal R^n|\ ||J||_D<\infin\}
{J∈Rn∣ ∣∣J∣∣D<∞}用
L
2
(
S
,
D
)
L_2(S,D)
L2(S,D)表示。后面我们会证明
J
∗
J^*
J∗ lies in
L
2
(
S
,
D
)
L_2(S,D)
L2(S,D)。关于符号,我们也将继续使用
∣
∣
⋅
∣
∣
||\cdot||
∣∣⋅∣∣,不加下标,来表示有限维向量上的欧几里得范数或有限矩阵上的Euclidean-induced norm。(也就是是,对应矩阵A,我们有
∣
∣
A
∣
∣
=
m
a
x
∣
∣
x
∣
∣
=
1
∣
∣
A
x
∣
∣
||A||=max_{||x||=1}||Ax||
∣∣A∣∣=max∣∣x∣∣=1∣∣Ax∣∣)。
我们假设每个基函数(basis function)
ϕ
k
\phi_k
ϕk是
L
2
(
S
,
D
)
L_2(S,D)
L2(S,D)的一个元素,所有
{
Φ
r
∣
r
∈
R
K
}
⊂
L
2
(
S
,
D
)
\{\Phi r|r\in\mathcal R^K\}\subset L_2(S,D)
{Φr∣r∈RK}⊂L2(S,D)。对于每一对函数
J
,
J
‾
∈
L
2
(
S
,
D
)
J,\overline J\in L_2(S,D)
J,J∈L2(S,D),当且仅当
⟨
J
,
J
‾
⟩
D
=
0
\lang J,\overline J\rang_D=0
⟨J,J⟩D=0时,我们称J D-正交(D-orthogonal)
J
‾
\overline J
J,表示为
J
⊥
D
J
‾
J\perp_D\overline J
J⊥DJ。对于任意
J
∈
L
2
(
S
,
D
)
J\in L_2(S,D)
J∈L2(S,D),只存在唯一
J
‾
∈
{
Φ
r
∗
∣
r
∈
R
K
}
\overline J\in\{\Phi r^*|r\in\mathcal R^K\}
J∈{Φr∗∣r∈RK}使
∣
∣
J
−
J
‾
∣
∣
||J-\overline J||
∣∣J−J∣∣最小化。
J
‾
\overline J
J称为J在
{
Φ
r
∣
r
∈
R
K
}
\{\Phi r|r\in\mathcal R^K\}
{Φr∣r∈RK}上关于
⟨
⋅
,
⋅
⟩
\lang\cdot,\cdot\rang
⟨⋅,⋅⟩的投影(This
J
‾
\overline J
J is referred to as the projection of J on
{
Φ
r
∣
r
∈
R
K
}
\{\Phi r|r\in\mathcal R^K\}
{Φr∣r∈RK} with respect to
⟨
⋅
,
⋅
⟩
\lang\cdot,\cdot\rang
⟨⋅,⋅⟩)。我们定义一个“投影矩阵”
Π
\Pi
Π(更准确地说,是投影算子),应用于J已得到
J
‾
\overline J
J。假说basis functions基函数
ϕ
1
,
.
.
.
,
ϕ
K
\phi_1,...,\phi_K
ϕ1,...,ϕK是线性无关的,投影矩阵为:
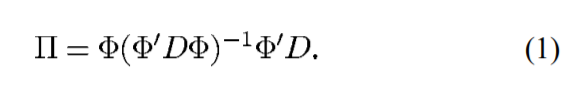
(注意
Φ
′
D
Φ
\Phi'D\Phi
Φ′DΦ是
K
×
K
K\times K
K×K的矩阵)。对于所有
J
∈
L
2
(
S
,
D
)
J\in L_2(S,D)
J∈L2(S,D),我们有:
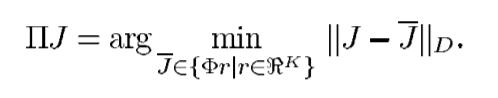

在给定一组固定的基函数时,投影
Π
J
∗
\Pi J^*
ΠJ∗是
J
∗
J^*
J∗的一种自然的近似值( a natural approximation)。 特别是,
Π
J
∗
\Pi J^*
ΠJ∗是加权线性最小二乘法问题的解,即最小化
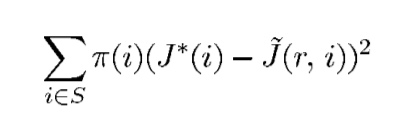
请注意,与每个状态相关的误差是由该状态被访问的频率来加权的。(如果状态空间是连续的而不是可计算的,这个和就会被一个积分所取代)。
B. The TD( λ \lambda λ) Operator
为了简化我们对TD(
λ
\lambda
λ)的分析,我们引入了一个算子。这个算子,我们将其称为TD(
λ
\lambda
λ)操作符,由一个参数
λ
∈
[
0
,
1
]
\lambda \in[0,1]
λ∈[0,1]索引(is indexed by a parameter
λ
∈
[
0
,
1
]
\lambda \in[0,1]
λ∈[0,1])并表示为
T
(
λ
)
:
L
2
(
S
,
D
)
→
L
2
(
S
,
D
)
T^{(\lambda)}:L_2(S,D)\rightarrow L_2(S,D)
T(λ):L2(S,D)→L2(S,D)。它的定义是:

当
λ
=
1
\lambda=1
λ=1时,极限为
l
i
m
λ
↑
1
(
T
(
λ
)
J
)
(
i
)
=
(
T
(
1
)
J
)
(
i
)
lim_{\lambda\uparrow1}(T^{(\lambda)}J)(i)=(T^{(1)}J)(i)
limλ↑1(T(λ)J)(i)=(T(1)J)(i)(under some technical conditions). 为了以有意义的方式解释TD(
λ
\lambda
λ)算子,请注意,对于每一个m,
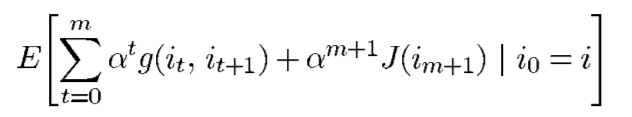
是在m个transitions内的expected cost,加上根据J计算出的remaining cost的近似值。这个总和有时被称为“m-stage truncated cost-to-go.”。直观地说,如果J是cost-to-go function的近似值,那么m-stage truncated cost-to-go可以看作是一种改进的近似值。由于
T
(
λ
)
J
T^{(\lambda)}J
T(λ)J是在m-stage truncated cost-to-go上的加权平均,
T
(
λ
)
J
T^{(\lambda)}J
T(λ)J也可以看作是一种改进的近似。 事实上,我们将在后面证明,
T
(
λ
)
T^{(\lambda)}
T(λ)是
L
2
(
S
,
D
)
L_2(S,D)
L2(S,D)上的一个contraction (
T
(
λ
)
T^{(\lambda)}
T(λ) is a contraction on
L
2
(
S
,
D
)
L_2(S,D)
L2(S,D)),它的不动点是
J
∗
J^*
J∗。因此, in the sense of the norm
∣
∣
⋅
∣
∣
D
||\cdot||_D
∣∣⋅∣∣D,
T
(
λ
)
J
T^{(\lambda)}J
T(λ)J总是比
J
∗
J^*
J∗实际更接近J。
C. Dynamics of the Algorithm
为了阐明TD( λ \lambda λ)的基本结构,我们构造了一个过程 X t = ( i t , i t + 1 , z t ) X_t=(i_t,i_{t+1},z_t) Xt=(it,it+1,zt)。显然, X t X_t Xt是一个马尔科夫过程。特别地, z t + 1 z_{t+1} zt+1和 i t + 1 i_{t+1} it+1是 X t X_t Xt的确定性函数, i t + 2 i_{t+2} it+2的分布只依赖于 i t + 1 i_{t+1} it+1。请注意,在每个时间t,随机向量 X t X_t Xt与当前参数向量 r t r_t rt一起,提供了计算 r t + 1 r_{t+1} rt+1的所有必要信息。通过定义一个函数s
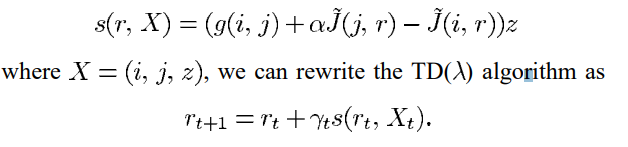
正如我们稍后将表明的那样,对于任何r,
s
(
r
,
X
t
)
s(r,X_t)
s(r,Xt)都有一个well-defined “steady-state” expectation,我们用
E
0
[
s
(
r
,
X
t
)
]
E_0[s(r,X_t)]
E0[s(r,Xt)]表示。直观地说,一旦
X
t
X_t
Xt达到稳定状态,TD(
λ
\lambda
λ)算法在 "平均 "的意义上,表现得像下面的确定性算法。
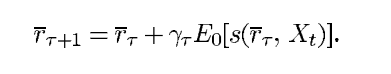
在一些技术假设下,这种确定性算法的收敛性意味着TD(
λ
\lambda
λ)的收敛性,而且两种算法都有相同的收敛极限。我们的研究集中在对这种确定性算法的分析上。















 3676
3676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









