









-
作者:Xinshuai Song, Weixing Chen, Yang Liu, Weikai Chen, Guanbin Li, Liang Lin
-
单位:中山大学,腾讯美国,鹏城实验室
-
原文链接:Towards Long-Horizon Vision-Language Navigation: Platform, Benchmark and Method (https://arxiv.org/pdf/2412.09082)
-
代码链接:https://hcplab-sysu.github.io/LH-VLN/
主要贡献
-
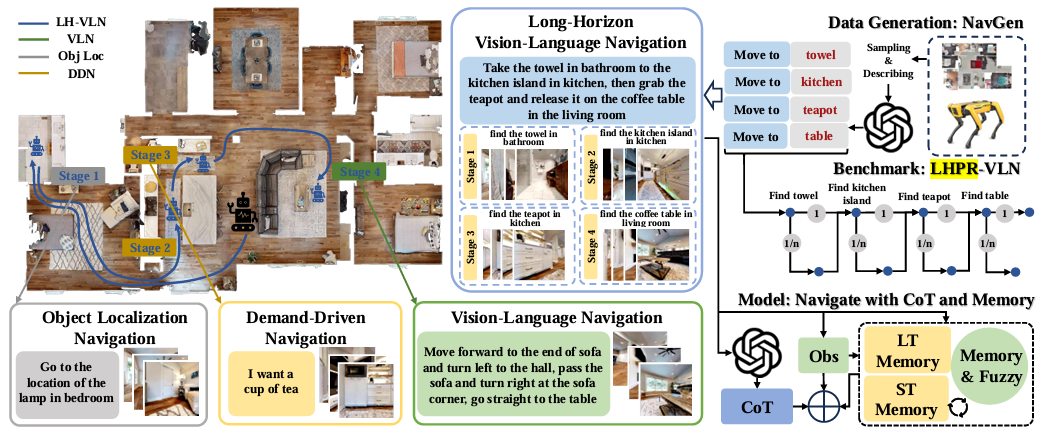
论文首次提出了多阶段长期视觉语言导航(LH-VLN)任务,旨在评估和增强智能体在复杂、多阶段导航任务中的能力,这些任务需要持续的推理和适应性。
-
开发了自动化数据生成平台NavGen,该平台能够生成具有复杂任务结构的高质量数据集,支持可扩展的任务多样性和提高数据利用率。
-
构建了LHPR-VLN基准,包含3260个任务,每个任务平均有150个步骤,捕捉了长期、多阶段任务的深度和多样性,并提出了三个新的评估指标:独立成功率(ISR)、条件成功率(CSR)和基于真实值加权的CSR(CGT)。
-
提出了多粒度动态记忆(MGDM)模块,通过结合短期和长期记忆机制,增强了模型在动态环境中的适应性和记忆处理能力。
研究背景
研究问题
现有的VLN方法主要集中在单阶段导航上,缺乏对复杂动态环境中长期规划和决策一致性的支持。
论文主要解决现有视觉语言导航(VLN)方法在处理多阶段和长期发展任务时的局限性。
研究难点
该问题的研究难点包括:
-
如何在复杂和动态环境中实现长期规划和决策一致性,
-
如何构建支持多阶段导航任务的数据集,
-
以及如何设计能够适应复杂任务的导航模型。
相关工作
该问题的研究相关工作有:
-
现有的VLN基准数据集如R2R、VLN-CE等在任务结构和数据多样性方面存在局限性,主要集中在单阶段或短期任务上,缺乏对多阶段、长期任务的支持。
-
基于地图的策略、路径预测、图方法和大型语言模型预测的VLN基准方法,在处理复杂任务结构和提高数据效用方面存在局限性。
研究方法
论文提出了多阶段长期视觉语言导航(Long-Horizon Vision-Language Navigation,LH-VLN)任务,并开发了自动化数据生成平台NavGen和新的基准LHPR-VLN来支持该任务。
NavGen平台
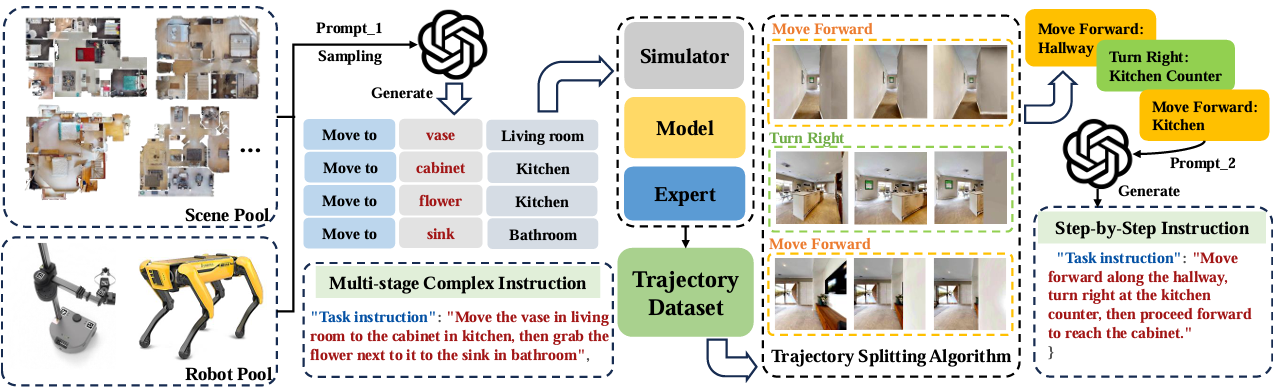
NavGen平台通过双向、多粒度生成方法构建具有复杂任务结构的数据集。
-
前向数据生成使用GPT-4生成任务指令,并在模拟器中生成轨迹数据。
-
后向数据生成将复杂任务的轨迹分解为单步导航任务。
LHPR-VLN基准
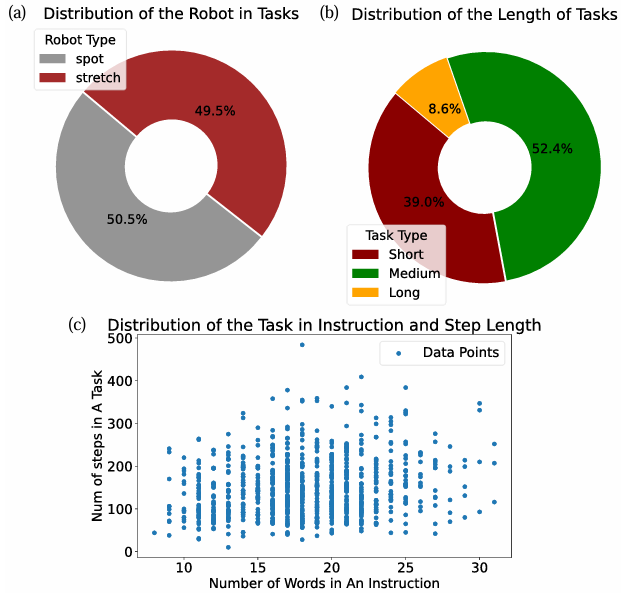
在NavGen平台上构建了LHPR-VLN(Long-Horizon Planning and Reasoning in VLN)基准。LHPR-VLN基准由3,260个任务组成,每个任务平均有150个任务步骤。
这个大规模基准测试具备评估多阶段长期VLN所需的多样性,涵盖了广泛的子任务结构和导航复杂性,是第一个专门为多阶段长期视觉语言导航任务设计的数据集。
Multi-Granularity Dynamic Memory(MGDM)模型
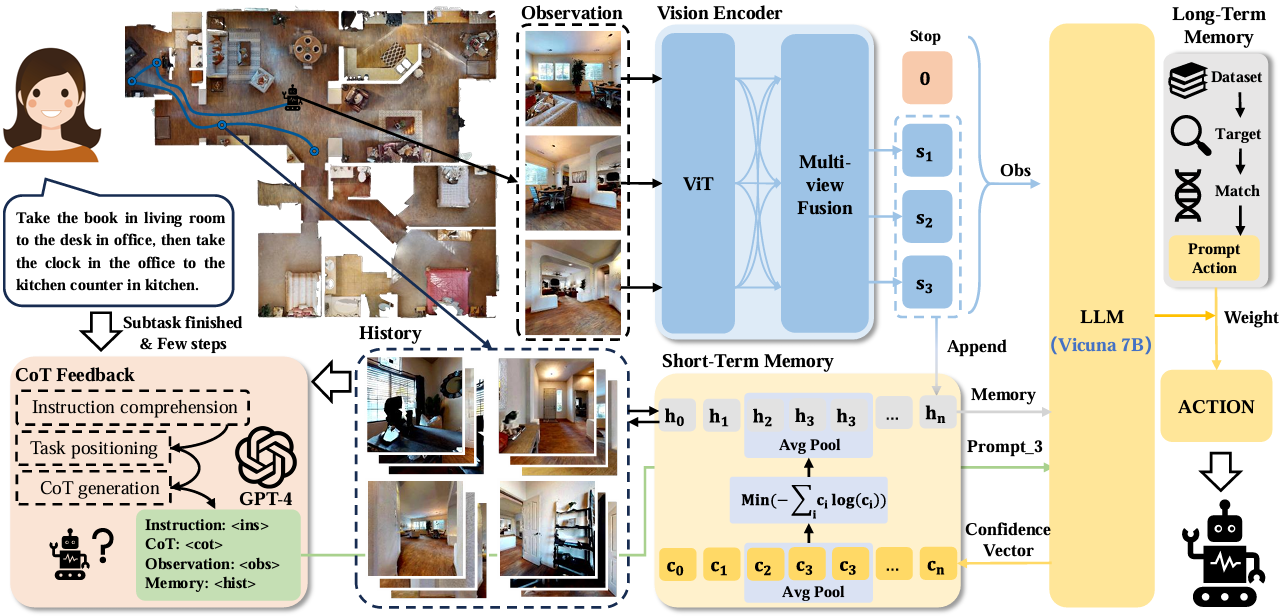
MGDM模型通过结合短期和长期记忆机制来增强模型在动态环境中的适应性。
-
短期记忆模块通过模糊和遗忘操作减少记忆序列的熵,
-
长期记忆模块通过从数据集中检索相关观察和动作来提供决策指导。
实验设计
模拟器
实验在Habitat3和Isaac Sim中进行,提供连续的3D场景平台和高质量的场景渲染及物理交互。
传感器
智能体在每个动作步骤接收来自前方、左方(+60°)和右方(-60°)的RGB观察和深度图像。
动作
提供原子动作包括“向前移动”、“左转”、“右转”和“停止”。当智能体执行“停止”动作时,当前任务或子任务视为完成。
场景
主要使用HM3D数据集中的216个大规模室内3D重建场景,并使用HSSD数据集进行测试。
机器人配置
包括Hello Robot的Stretch机器人和Boston Dynamics的Spot机器人。
基线模型
论文使用四种基线模型:ETPNav、GLM-4v prompt、NaviLLM和GPT-4 + NaviLLM,探究现有模型在有限信息下理解和完成多阶段复杂任务的能力,以及记忆在多阶段复杂任务中的重要性:
-
ETPNav:一种基于图的导航模型,将当前和历史的观测视为图节点。
-
GLM-4v prompt:使用prompt引导GLM-4v生成合理的输出,并测试其在LH-VLN任务中的实际表现。
-
NaviLLM:在连续环境训练并在数据集上进行微调,以评估其在LH-VLN任务中的表现。
-
GPT-4 + NaviLLM:将GPT-4与NaviLLM结合,利用GPT-4分解复杂任务,然后由NaviLLM依次执行每个子任务。
结果与分析
现有模型的性能

现有模型在LH-VLN任务中表现不佳,尤其是在多阶段复杂任务中。所有模型在2-3个子任务的LH-VLN任务中均未能完成单个子任务。

任务分解的效果
使用GPT-4进行任务分解的NaviLLM模型在单个子任务上的表现有所提高,但在整体任务理解上仍存在不足。
记忆模块的重要性
MGDM模型在LH-VLN任务中表现出色,尤其是在处理较长和较复杂的子任务时。MGDM模型通过结合短期和长期记忆机制,能够在动态环境中保持一致的决策和导航。
总结
论文通过提出LH-VLN任务、开发NavGen平台和LHPR-VLN基准以及设计MGDM模型,解决了多阶段视觉语言导航中的关键挑战。
MGDM模型通过结合短期和长期记忆机制,在动态环境中实现了高效的导航,达到了新的最佳性能。


















 3429
3429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









