







Pandas 的 DataFrame 如何按指定 list 排序
解析过程如下图:
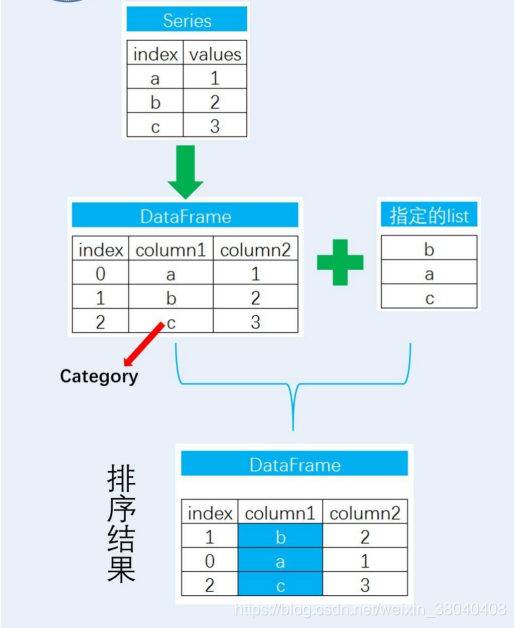 这里主要涉及pandas 中的categorical data type 分类数据,和R中的因子行型变量类似,可以进行排序操作,不可进行数值运算操作。具体可参考官方文档
这里主要涉及pandas 中的categorical data type 分类数据,和R中的因子行型变量类似,可以进行排序操作,不可进行数值运算操作。具体可参考官方文档
下面会先创建分类dataframe,然后使用Series.cat.reorder_categories按照指定顺序对类别进行重新排序。
ss = pd.Series({'a': 1, 'b': 2, 'c': 3})
list_1 = ['b', 'c', 'a']
dff = pd.DataFrame(ss)
dff = dff.reset_index()
dff.columns = ['word', 'number']
# 设置成 “category” 数据类型
dff['word'] = dff['word'].astype('category')
dff['word'].cat.reorder_categories(list_1, inplace=True)
# Series.cat.reorder_categories(new_categories,ordered,inplace)
# new_categories: list,新类别顺序
# ordered: bool 是否是为有序类别,若梅指定该参数则不改变顺序
# inplace:参数设置为True使得变动覆盖原数据
dff.sort_values('word', inplace=True)
print(dff)
# word number
# 1 b 2
# 2 c 3
# 0 a 1
指定 list 元素多的情况:
若指定的 list 所包含元素比 Dataframe 中需要排序的列的元素 多,怎么办? reorder_catgories()方法不能继续使用,因为该方法使用时要求新的 categories 和 dataframe 中的categories 的元素个数和内容必须一致,只是顺序不同。这种情况下,可以使用 set_categories() 方法来实现。新的 list 可以比 dataframe 中元素多。
list_2 = ['d', 'c', 'b', 'a', 'e']
dict_2 = {'e': 1, 'b': 2, 'c': 3}
new_df = pd.DataFrame(list(dict_2.items()), columns=['word', 'value'])
new_df['word'] = new_df['word'].astype('category')
new_df['word'].cat.set_categories(list_2, inplace=True)
# Series.cat.set_categories(new_categories, ordered, rename, inplace)
# new_categories: list,新类别顺序
# ordered: bool default False, 是否是为有序类别,若梅指定该参数则不改变顺序
# rename: bool default False, 是否应将new_categories视为旧类别的重命名或重新排序的类别。
# inplace: bool default False,参数设置为True使得变动覆盖原数据
new_df.sort_values('word', inplace=True)
print(new_df)
# word value
# 2 c 3
# 1 b 2
# 0 e 1
指定 list 元素少的情况:
若指定的 list 所包含元素比 Dataframe 中需要排序的列的元素 少,怎么办?
这种情况下,set_categories() 方法还是可以使用的,只是没有的元素会以 NaN 表示
注意下面的 list 中没有元素“b”
list_3 = ['d', 'c', 'a', 'e']
dict_3 = {'e': 1, 'b': 2, 'c': 3}
new_df_3 = pd.DataFrame(list(dict_3.items()), columns=['word', 'value'])
new_df_3['word'] = new_df_3['word'].astype('category')
new_df_3['word'].cat.set_categories(list_3, inplace=True)
new_df_3.sort_values('word', inplace=True)
print(new_df_3)
# word value
# 2 c 3
# 0 e 1
# 1 NaN 2
Categorical
print(pd.Categorical([1,2,3,1,2,3]))
# [1, 2, 3, 1, 2, 3]
# Categories (3, int64): [1, 2, 3]
print(pd.Categorical(['a', 'b', 'c', 'a', 'b', 'c']))
# [a, b, c, a, b, c]
# Categories (3, object): [a, b, c]
# 排序的分类可以根据类别的自定义顺序进行排序,并且可以具有最小值和最大值
c=pd.Categorical(['a', 'b', 'c', 'a', 'b', 'c'], ordered=True,categories=['c', 'b', 'a'])
print(c)
# [a, b, c, a, b, c]
# Categories (3, object): [c < b < a]
import numpy as np
print(c.max(), c.min())# a c
df_4 = pd.DataFrame({
'class':np.random.choice(['A','B','C','D'],10),
'value':np.random.uniform(0,20,10)
})
print(df_4)
# class value
# 0 A 7.775473
# 1 D 1.715003
# 2 C 7.288511
# 3 A 13.373221
# 4 B 16.103561
# 5 A 8.605237
# 6 C 17.693875
# 7 C 14.938128
# 8 B 3.140564
# 9 B 14.997153
print(df_4.sort_values('class')) # 数据按照class列的字母升序排列
# class value
# 3 A 12.099352
# 5 A 15.646437
# 6 A 13.028520
# 9 A 14.934795
# 8 B 5.664879
# 0 C 5.156619
# 1 C 8.305190
# 2 C 15.215959
# 4 C 14.725711
# 7 D 5.506384
# 将数据按照自定义顺序排序
from pandas.api.types import CategoricalDtype
cat = CategoricalDtype(categories=['B', 'D', 'A', 'C'], ordered=True)
df_4['class'] = df_4['class'].astype(cat)
print('class: \n', df_4.sort_values('class'))
# class:
# class value
# 5 B 12.548725
# 8 B 9.691730
# 0 D 4.415791
# 2 D 8.245081
# 7 A 1.415189
# 9 A 14.537328
# 1 C 4.467335
# 3 C 7.765526
# 4 C 16.964883
# 6 C 4.008942















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









