







论文笔记--Learning To Retrieve Prompts for In-Context Learning
1. 文章简介
- 标题:Learning To Retrieve Prompts for In-Context Learning
- 作者:Rubin O, Herzig J, Berant J
- 日期:2021
- 期刊:arXiv preprint
2. 文章导读
2.1 概括
文章提出了一种新的In-Context Learning的思路。传统的In-Context Learning 获得training samples(训练样本)的方法主要分为两种;1) 基于非监督的相似度方法得到训练样本 2) 训练一个prompt retriever来为模型挑选训练样本。文章认为,我们应当让大语言模型自己去找到训练样本作为prompt去训练。
文章的整体架构如下
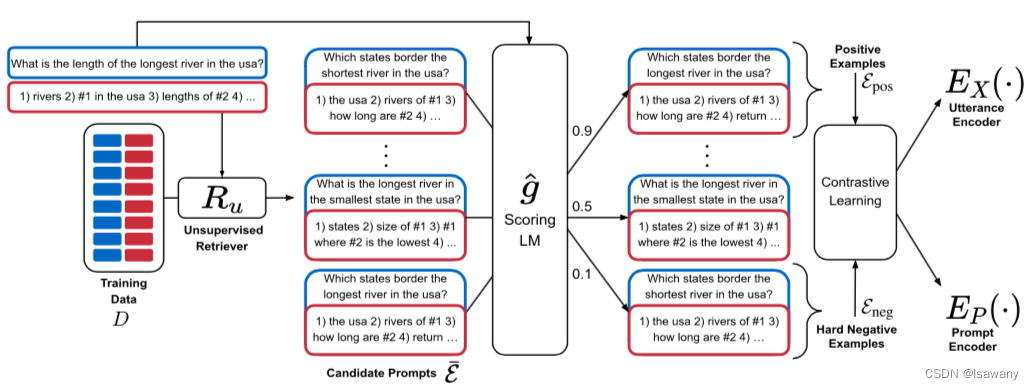
2.2 文章重点技术
2.2.1 In-Context Learning
首先简单介绍下In-Context Learning的概念。所谓In-Context,即“上下文”“内”,意指我们要从上下文内部找到合适的prompt进行训练,而非人工定义prompt。传统的In-Context Learning一般会找到和测试样本最相似的一些标记样本作为测试样本的上下文。例如在一个情感分类任务中,测试样本为 s = s= s=“It is such an awful movie”,传统的预测方法为将 s s s直接输入给模型,模型会预测 s s s的分类,即 y ∈ { n e g a t i v e , p o s i t i v e } y\in \{negative, positive\} y∈{negative,positive}。In-Context Learing 会首先遍历标注数据集,找到和 s s s最为相似的样本,假设模型找到 2 2 2个样本对"The movie is awful–>negative", “It is such a terrible movie! -> negative”,则模型的输入为“"The sentiment of ‘The movie is awful’ is negative; The sentiment of ‘It is such a terrible movie!’ is negative; The sentiment of ‘It is such an awful movie’ is ",然后预测下一个token可能时positive还是negative。
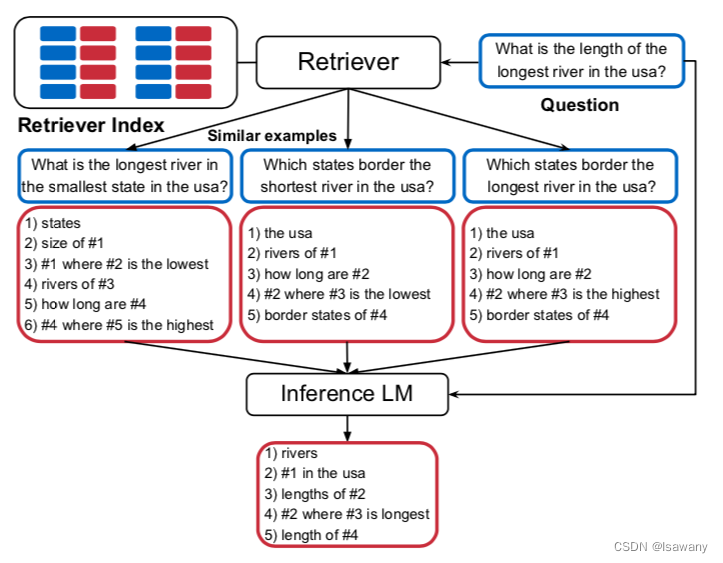
2.2.2 Prompt Retrieval
上述步骤中一个重要的技术就是如何找到这些标记样本,即Prompt Retrieval。下图为一个QA问题的Prompt Retrieval示意。
本文希望让语言模型自己筛选出来上述定义的训练样本。具体任务描述如下:给定标记数据集
D
=
{
(
x
i
,
y
i
)
}
i
=
1
n
\mathcal{D} = \{(x_i, y_i)\}_{i=1}^n
D={(xi,yi)}i=1n和测试样本
x
t
e
s
t
x_{test}
xtest,Prompt Retrieval 的任务就是找到一个训练样本集
P
=
{
(
x
i
,
y
i
)
}
i
=
1
m
⊂
D
,
m
≪
n
\mathcal{P} = \{(x_i, y_i)\}_{i=1}^m \subset \mathcal{D}, m \ll n
P={(xi,yi)}i=1m⊂D,m≪n。我们也可以称这个样本集为一种prompt。
2.2.3 Efficient Prompt Retrieval(EPR)
文章提出了一种叫做EPR的训练集检索方法,具体步骤如下
- 候选集生成 :遍历所有的标记样本 ( x i , y i ) ∈ D (x_i, y_i) \in \mathcal{D} (xi,yi)∈D,我们通过无监督文本相似度判别方法BM25或SBERT得到和每个标记样本最相似的样本集合,作为该样本的候选prompt: E ‾ ( x , y ) : = E ‾ = { e ‾ 1 , … , e ‾ L } \overline{\mathcal{E}}(x, y):=\overline{\mathcal{E}} = \{\overline{e}_1, \dots, \overline{e}_L\} E(x,y):=E={e1,…,eL}。
- 得分计算: 文章选定一个语言模型
g
^
\hat{g}
g^来为每个
E
‾
\overline{\mathcal{E}}
E中的样本打分:
s c o r e ( e ‾ l ) = P r o b ( y ∣ e ‾ l , x ) score(\overline{e}_l) = Prob(y|\overline{e}_l, x) score(el)=Prob(y∣el,x)
即给定 x x x及prompt中的一个候选样本 s c o r e ( e ‾ l ) score(\overline{e}_l) score(el)时, g ^ \hat{g} g^将输出预测为 y y y的概率有多大。这个得分衡量了该候选样本(不考虑prompt中其它样本对情况下)对解码 y y y的帮助有多大。将该得分函数应用于所有的标记样本,对每个样本 ( x , y ) (x,y) (x,y)我们定义其正样本集合 E p o s \mathcal{E}_{pos} Epos为 E ‾ \overline{\mathcal{E}} E中得分最高的 k k k个样本,负样本集合 E n e g \mathcal{E}_{neg} Eneg为 E ‾ \overline{\mathcal{E}} E中得分最低的 k k k个样本。基于假设“候选集中包含好的和差的prompt”,我们认为得分越高越可能时好的,反之得分越低越差。 - 训练 : 定义两个编码器
E
x
(
⋅
)
E_x(\cdot)
Ex(⋅)和
E
P
(
⋅
)
E_P(\cdot)
EP(⋅)分别用来编码输入句子
x
x
x的分词和prompt(训练样本对的输入-输出拼接在一起)的分词。文中用BERT作为上述两种词向量编码器,并采用每句话的
C
L
S
CLS
CLS对应的向量作为该句编码。训练的目的是学习到一个相似度度量使得测试样本和产生对应输出的训练样本集尽可能相似。为此,文章采用了对比学习方法,定义损失函数如下
L ( x i , e i + , e i , 1 − , … , e i , 2 B − 1 − ) = − log e s i m ( x i , e i + ) e s i m ( x i , e i + ) + ∑ j = 1 2 B − 1 e s i m ( x i , e i , j − ) L(x_i, e_i^+, e_{i,1}^-,\dots, e_{i,2B-1}^- ) = -\log \frac{e^{sim(x_i, e_i^+)}}{e^{sim(x_i, e_i^+)} + \sum_{j=1}^{2B-1} e^{sim(x_i, e_{i,j}^-)}} L(xi,ei+,ei,1−,…,ei,2B−1−)=−logesim(xi,ei+)+∑j=12B−1esim(xi,ei,j−)esim(xi,ei+)
其中作者采用了in-batch negatives trick,即给定 x i x_i xi时,随机从它的正候选样本集合 E p o s ( i ) \mathcal{E}^{(i)}_{pos} Epos(i)中抽取一个样本 e i + e_i^+ ei+,该样本与 x i x_i xi的相似度要尽可能高:在损失函数中, s i m ( x i , e i + ) sim(x_i, e_i^+) sim(xi,ei+)越高,损失函数 L L L的值越小;同理随机从它的负候选样本中抽取样本 e i , 1 − e_{i,1}^- ei,1−,再随机从和 x i x_i xi相同Batch(假设batch size为B)的每个样本 x j x_j xj的负候选样本 E n e g ( j ) \mathcal{E}^{(j)}_{neg} Eneg(j)中随机挑选一个样本 e i , j − , j = 2 , 3 , … , B e_{i,j}^-, j=2, 3, \dots, B ei,j−,j=2,3,…,B,从其正候选样本中随机挑选一个样本 e i , j − , j = B + 1 , B + 2 , … , 2 B − 1 e_{i,j}^-, j=B+1, B+2, \dots, 2B-1 ei,j−,j=B+1,B+2,…,2B−1,所有这些样本与 x i x_i xi的相似度应该尽可能的小,反映在损失函数中即 s i m ( x i , e i , j − ) , ∀ j sim(x_i, e_{i,j}^-), \forall j sim(xi,ei,j−),∀j越小,损失函数越小。 - 推断:给定测试样本 x t e s t x_{test} xtest,首先计算其编码 E X ( x t e s t ) E_X(x_{test}) EX(xtest),然后找到与其最相似的 L L L个样本 P = { e 1 , … , e L } \mathcal{P} = \{e_1, \dots, e_L\} P={e1,…,eL}。假设语言模型接受的最大长度为 C C C,则我们得到 L L L中相似度最高的 L ′ L' L′个样本使得这些样本的长度和 ∑ i = 1 L ′ ∣ e i ∣ + ∣ x t e s t ∣ + ∣ y ′ ∣ ≤ C \sum_{i=1}^{L'} |e_i| + |x_{test}|+|y'|\le C ∑i=1L′∣ei∣+∣xtest∣+∣y′∣≤C。最后,模型基于上述 L ′ L' L′个样本和 x t e s t x_{test} xtest的拼接值给出预测输出结果。
3. 文章亮点
文章的主要贡献在于“让语言模型自己打分并选择合适的Prompt”。基于该方法,模型在多个任务上的表现均有了大幅的提升。















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









