







论文笔记--RoBERTa: A Robustly Optimized BERT Pretraining Approach
1. 文章简介
- 标题:RoBERTa: A Robustly Optimized BERT Pretraining Approach
- 作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer†, Veselin Stoyanov
- 日期:2019
- 期刊:arxiv preprint
2. 文章导读
2.1 概括
文章提出了RoBERTa(Robustly optimized BERT approach)模型,从名字也可以看出RoBERTa是在BERT[1]基础上进行的优化。文章进行了大量的消融、增强实验,进一步验证了通过调节超参数、增加数据量、微调训练目标,Bert在下游任务的表现可以得到大幅提升。相比于BERT,文章主要优化点在于
- 训练的模型参数量更多,数据更多
- 移除NSP训练目标
- 在更长的句子上进行训练
- 在训练数据上进行动态掩码
RoBERTa在NLA、QA、SST等任务上达到了SOTA水平。
2.2 文章重点技术
2.2.1 模型架构的优化
RoBERTa的基本架构和BERT相同,超参数也基本采用BERT原文的超参数,除了warmup步数(w)和peak learning rate(peak lr)。所谓warm up,即模型训练最开始的时候一般不稳定,所以令学习率lr很小,尤其是针对test数据集上损失较高的情况可采用warm up策略,防止基于mini-batch的训练过早的过拟合。在一段时间后模型的lr会趋于稳定达到peak lr然后再下降。再次下降是因为模型平稳之后不希望再被mini-batch的数据影响太多。BERT原文采用的w为10000步,peak lr为1e-4,而RoBERTa(large)采用w为30K,peak lr为4e-4。除此之外,RoBERTa选择Adam的
β
2
=
0.98
\beta_2=0.98
β2=0.98,当batch size比较大的时候更加稳定。
BERT在数值实验中为了提升效率选择90%的情况下使用句子长度为128,然后在剩余的10%步骤上训练长度为512的句子从而学习到位置编码。RoBERTa则在整个过程中都采用max length=512。
2.2.2 数据集的增强
文章认为预训练的数据集越大,下游任务表现越好(已在其它论文中被证实)。据此,文章尽可能地搜集更多数据进行预训练。文章从五个不同领域的英语语料库中收集共计160GB的数据集,包括
- BooksCorpus和英文维基百科(同BERT原文),共计16GB
- CC-NEWS,文章从CommonCrawl数据集中收集了其中的英文数据,包含在2016~2019年的63Million英文新闻,过滤之后共计76GB
- OpenWebText,来自WebText语料库的开源数据集(同GPT-1[2]),共计38GB
- STORIES,来自CommonCrawl数据库的一部分被转换成故事风格的预料,共计31GB
2.2.3 掩码方法的优化
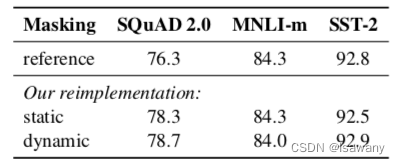
BERT原文采用的掩码策略为:先随机选出词表中的15%token,80%的概率用"[MASK]"替换这些token,10%的可能保持不变,10%的可能随机用其它token替换当前token。但这种方式是静态的(Static)。为了避免每个epoch模型采用相同的掩码,文章提出1) 静态掩码策略(static masking):将训练数据复制10份,每个句子都采用10次不同的mask,这样40epochs之后,每个句子都有4次相同的mask。2) 动态掩码策略(dynamic masking):每个句子每次用于训练时均生成不同的mask。
文章比较了static、dynamic和BERT原文掩码在SQuAD,MNLI-m和SST-2上面的表现,发现动态掩码策略可以提升模型的F1-表现,故RoBERTa采用动态掩码策略,具体结果见下表
2.2.4 训练目标的调整
BERT原文采用了MLM(Masked Language Model)和NSP(Next Sentence Prediction)两种任务进行预训练,为了测试这两种训练目标对模型表现的影响,文章采用了下述训练方案
- Segment-pair+NSP:采用NSP损失。每个输入都是一对文本,每个文本可能包含多个自然语句,总长度不超过512。
- Sentence-pair+NSP:采用NSP损失。每个输入都是一对句子,一般来说每个句子的长度远小于512,从而在该实验中增加了batch size以保证每次训练的token数和其它任务相近。
- Full-Sentences:不采用NSP损失。每个输入都是从一个或者多个文档中连续采样的完整句子,满足总长度不超过512。如果当前采样到某文档的结尾,但句子总长度低于512,则从其它文档基于采样句子增加至当前文档,两个文档之间用特殊分隔符表示。
- Doc-Sentences:不采用NSP损失。类似Full-Sentences,只是不跨越文档。但不跨越文档就会导致部分采用的文本长度低于512,为此我们动态提升batch size从而满足每次训练的token数和其它任务相近。
对上述几种训练方式对数值实验结果进行比较,下表可以看到不采用NSP损失的Doc-Sentences表现最好,故RoBERTa选择采用Doc-Sentences训练方式。

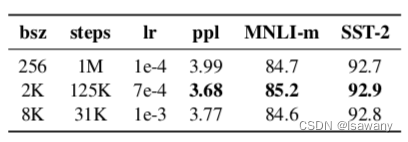
2.2.5 Batch size的提升
BERT BASE 采用batch size =256,训练了1M步。为了验证Batch size的影响,我们试验了batch size=2K,step=125K和batch size=8K,step=31K的情况(
1
M
∗
256
≈
2
K
∗
125
K
≈
8
K
∗
31
K
1M*256\approx 2K*125K\approx 8K*31K
1M∗256≈2K∗125K≈8K∗31K)。实验效果如下表。可以看到batch size为8K时,模型的困惑度(ppl)最高,且准确率也有提升,故RoBERTa采用batch size为8K。
2.2.6 编码方式的修改
原始BERT采用的是基于字符的BPE编码。参考GPT-2[3]中的编码方式,文章选择用基于字节的编码方式(byte-level BPE)对文本进行编码。
综上,我们将采用了上述优化策略的模型称为RoBERTa(Robustly optimized BERT approach)
3. 文章亮点
文章通过大量数值试验证明,BERT仍有很多优化的空间,包括超参数的调节、数据量的增加和训练目标的调整等。RoBERTa在包括QA、SST、NLI等下游任务中达到了SOTA表现。同样,未来也可以通过增强数据和模型参数量等方式对RoBERTa进行进一步的优化。
4. 原文传送门
RoBERTa: A Robustly Optimized BERT Pretraining Approach
5. References
[1] 论文笔记–BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2] 论文笔记–Improving Language Understanding by Generative Pre-Training
[3] 论文笔记–Language Models are Unsupervised Multitask Learners















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









