







©PaperWeekly 原创 · 作者 | 徐本峰
单位 | 中国科学技术大学
研究方向 | 自然语言处理
本文简要快速地向大家分享我们近期发表在 ICLR 2023 上关于大模型、上下文学习方向的工作。

论文链接:
https://arxiv.org/abs/2303.13824
代码链接:
https://github.com/BenfengXu/KNNPrompting

背景&动机
上下文学习在最早的 GPT3 论文 [1] 中就已经被提出:
We use the term “in-context learning” to describe the inner loop of this process, which occurs within the forward-pass upon each sequence.

▲ GPT3 paper demonstrates In-Context Learning
问题一:上下文学习的容量是有限的
这是一个非常直接、显然却往往被大家当做理所当然的问题,即受限于当前主流大模型的 context 长度,上下文学习只能容纳有限个 demonstration 样本。而实际上,在我们的 pilot study 里,随着 demonstration 数量的增加,性能是持续提升的:
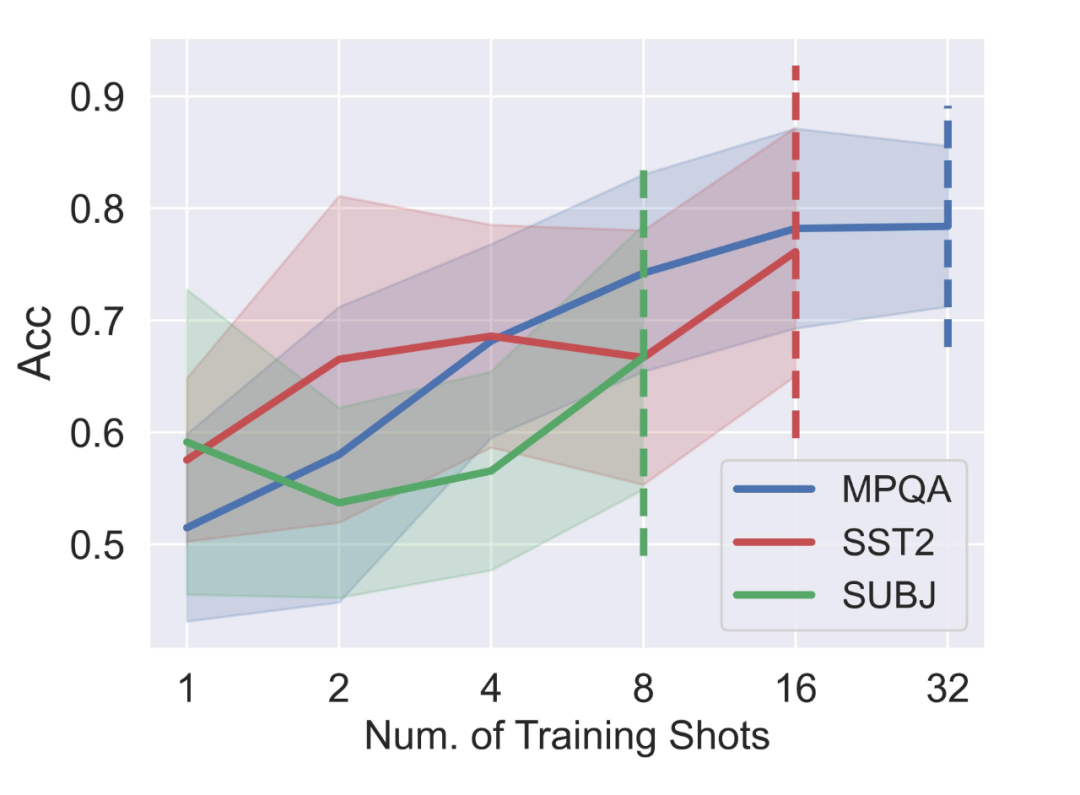
▲ 上下文学习的性能随样本数量持续提升,却被上下文长度容量截断
问题二:上下文学习受到多种潜在Bias的影响
Calibration before use [2](ICML21)这篇文章中较早地系统分析了 recency、common token、majority label 等多种 bias 对上下文学习性能的影响,并提出了一种非常简单且巧妙的,通过空置输入来测量和校正 bias 的方法:Contextual Calibration。
另外一篇 Fantastically Ordered Prompts [3](ACL 22 outstanding paper)也从 demonstration 的顺序这个角度切入,探讨了上下文学习性能的 sensitivity。

方法
本文提出一种基于近邻检索的方法,简单且十分有效地解决以上两个问题。
1. 首先将所有训练样本分为:Train Set 和 Anchor Set
2. 将 Anchor 样本用于推理,得到 LLM 输出的 LM Probability Distribution,作为 Key,而 Anchor 样本的 Label 作为 Value,key-value pair 构建 Datastore(这里的关键在于,记录并存储完整的 LM Distribution,这样才能保存完备的信息而没有任何损失)
3. 对于测试样本,不再直接解码 LM Distribution 到 Label Word,而是计算该分布在 Anchor Set 分布中的最近邻,取其 Value 直接作为最终的预测结果
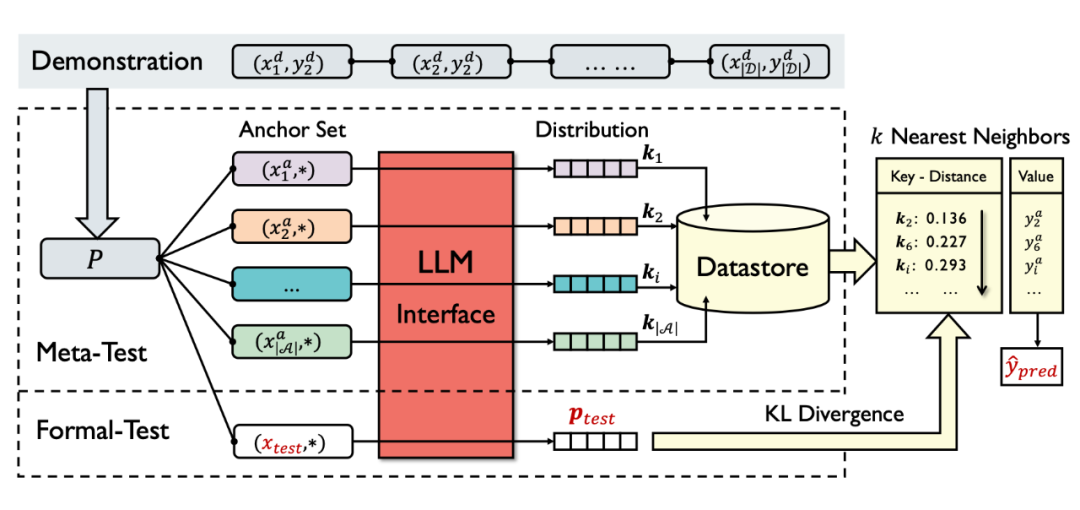
▲ kNN Prompting

实验结果
实验主要分两种 Setting,Few-Shot 和 Fully-Supervised。
先来看 Few-Shot:
主要是为了和 SOTA 方法 [2][4] 进行对比,展示 kNN Prompting 本身作为一种 inference 框架,相较于 In-Context Learning 的显著效果提升。
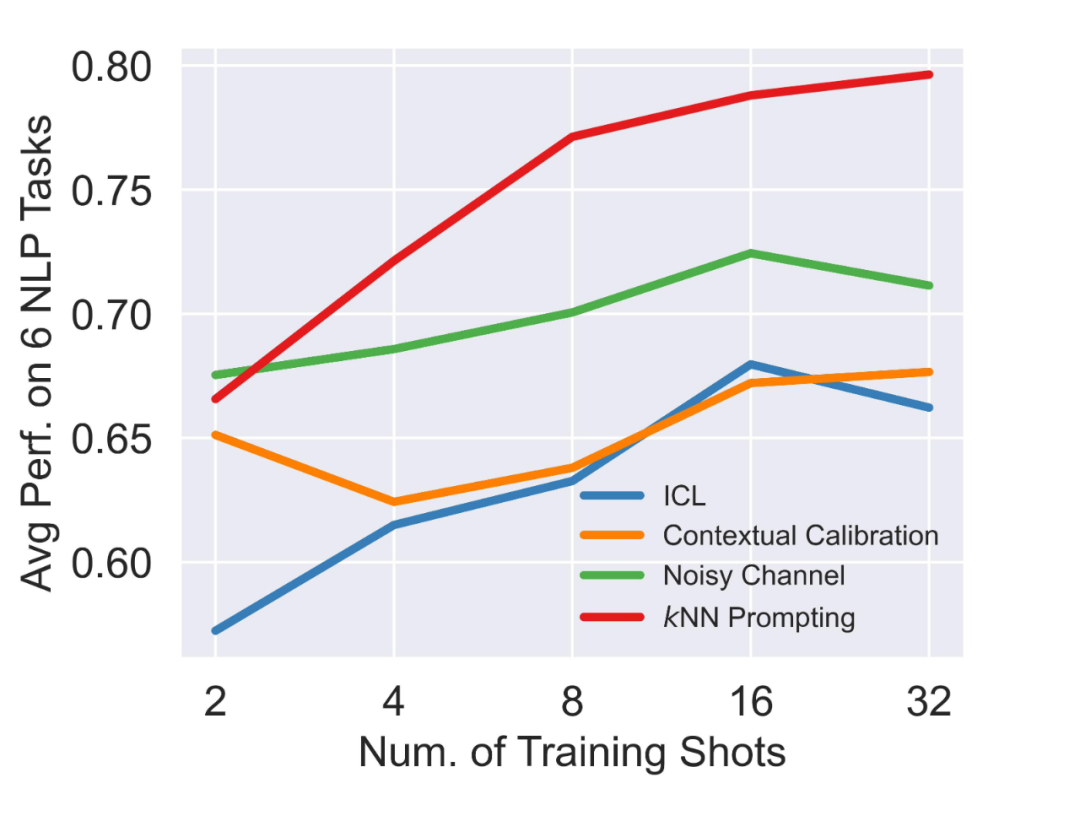
▲ kNN Promping VS SOTA under comparable Few-Shot Setting
然后是 Fully-Supervised:
kNN Prompting 在训练样本规模远远超过上下文容量的场景下,仍然能够 Effectively Scale Up,在 32~1024 的样本区间以及 0.8B~30B 的模型区间,展现出优秀的 Scaling Curve。
而相比之下,标准的 In-Context Learning 则会在很早的位置就被截断。
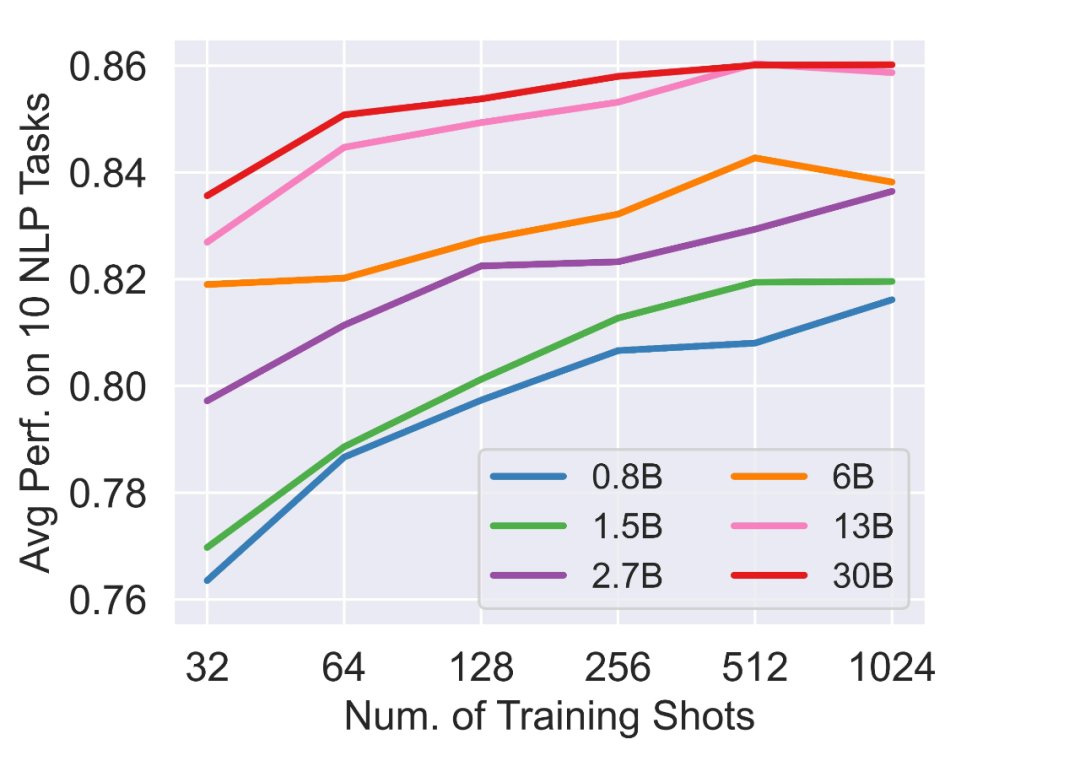
▲ Data Scaling Property of kNN Prompting
此外,一种很 Intuitive 的利用更多训练样本的方法是:从 training set 里检索尽可能相关(相似)的样本作为 Demonstration 来构建 Prompt,我们也做了相应的对比:
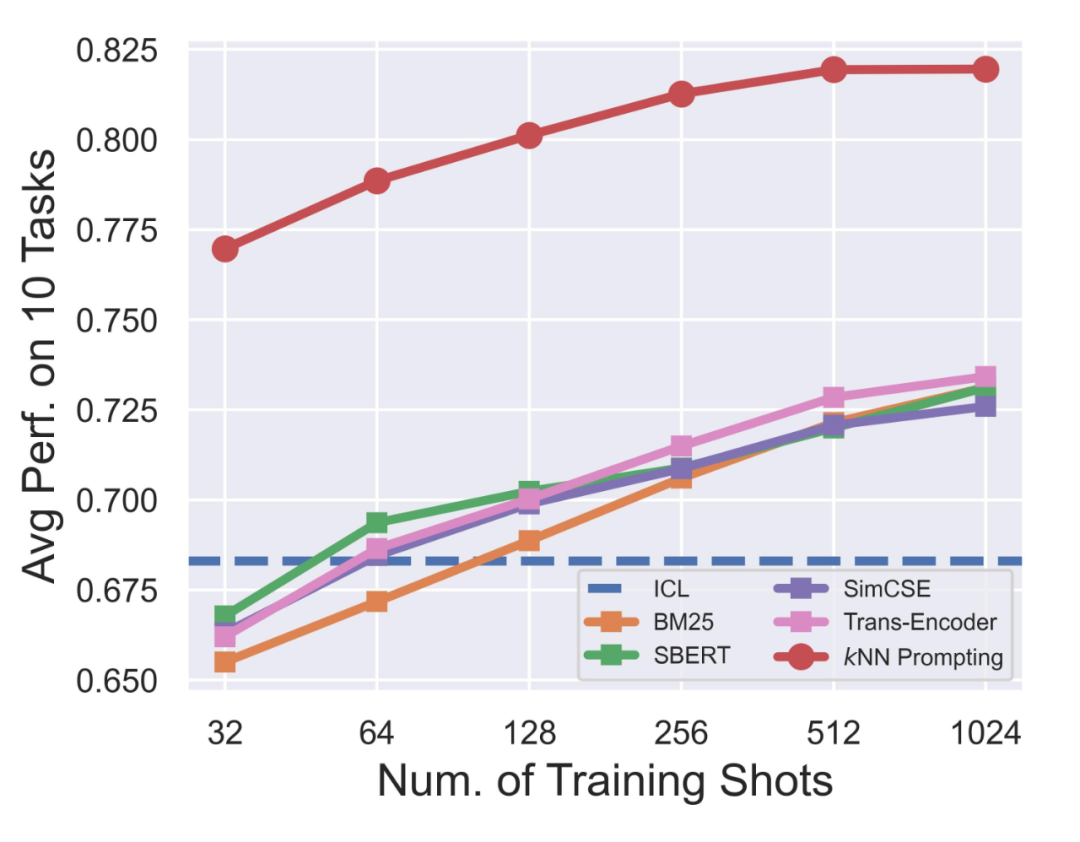
▲ kNN Prompting VS Retrievl-based Prompt Compse Method
还有更多实验大家可以移步 paper。

总结
本文提出了上下文学习的一种简单、有效的改进方法,通过 LM 预测分布的缓存+近邻检索,实现了:
少样本场景下的大幅提升,显著优于现有 SOTA 方法
全量样本场景下的无限扩展(Data Scaling)性能

参考文献
[1]Language Models are Few-Shot Learners, NIPS20
[2]Calibrate Before Use: Improving Few-Shot Performance of Language Models, ICML21
[3]Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity, ACL22
[4]Noisy Channel Language Model Prompting for Few-Shot Text Classification, ACL22
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









