






 本文详细介绍了决策树算法,包括ID3(基于信息增益)、C4.5(增益率改进)和CART(基尼指数)的学习过程。通过实例演示了如何利用这些算法从数据集中构建决策树以提高样本纯度。
本文详细介绍了决策树算法,包括ID3(基于信息增益)、C4.5(增益率改进)和CART(基尼指数)的学习过程。通过实例演示了如何利用这些算法从数据集中构建决策树以提高样本纯度。
hello,大家好!今天来为大家详细介绍决策树算法。决策树是一种常见的机器学习分类算法,从给定训练数据集学得一个模型用以对新示例进行分类。
首先,先来展示一下我们的数据集(这里采用西瓜书上的西瓜数据集):

一颗决策树有一个根结点,若干个内部节点和若干个叶子结点。叶节点对应于决策结果,其他每个节点则对应于一个属性测试,每个节点包含的样本集合根据属性测试的结果被划分到子节点中;根节点包含样本全集,从根节点到叶节点的每个路径对应一个判定测试序列。而决策树学习的目的就是为了产生一颗泛化能力强,处理未见示例能力强的决策树。
所以决策树学习的关键是如何选择最优划分属性。随着划分的不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,希望决策树更加简洁,也就是结点的纯度越来越高。
ID3决策树学习算法
学习算法
首先我们使用信息熵来度量样本集合纯度,信息熵越小,样本纯度越高。
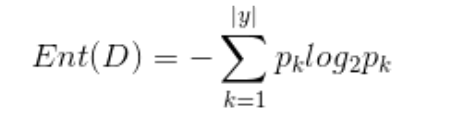
这里pk表示第k类样本在样本集合中所占的比例。
因为考虑到不同的分支节点所包含的样本数不同,所以接下来我们对各个分支赋予权重。假设属性a有v个可能取值,其中第v个分支节点包含了样本D中所有在属性a上取值为av的样本,记为Dv,则赋予权重可表示为|Dv|/|D|。则信息增益公式表示为

信息增益越大,则使用属性a进行划分的纯度越大。ID3算法就是以信息增益为准则来进行划分属性。
接下来,我们以西瓜数据集为例,来演示ID3如何构造决策树。
1. 根节点的信息熵

根节点有两个分类,好瓜和坏瓜,好瓜有8例,坏瓜有9例
2.计算当前所有属性{色泽,根蒂,敲声,纹理,脐部,触感}的信息增益,先以色泽为例,色泽有三个分支(D1=青绿,D2=乌黑,D3=浅白),D1编号为{1,4,6,10,13,17}6个样例,其中好瓜坏瓜各三个;D2编号为{2,3,7,8,9,15}6个样例,其中好瓜4个坏瓜2个;D3编号为{5,11,12,14,16}5个样例,其中好瓜1个,坏瓜4个,因此信息熵及信息增益为:

可以看出纹理信息增益最大,所以纹理被选为划分属性。
所以下一步,以纹理=清晰为例,该节点包含的样例中有D1:{1,2,3,4,5,6,8,10,15}9个样例,可选择的属性有{色泽,根蒂,敲声,脐部,触感},分别计算机他们的信息增益:

因此在纹理=清晰的分支处,我们可以选择根蒂或者脐部或者触感为划分属性。
以此类推,对每个分支节点进行上述操作,最终得到构造的决策树如下所示:
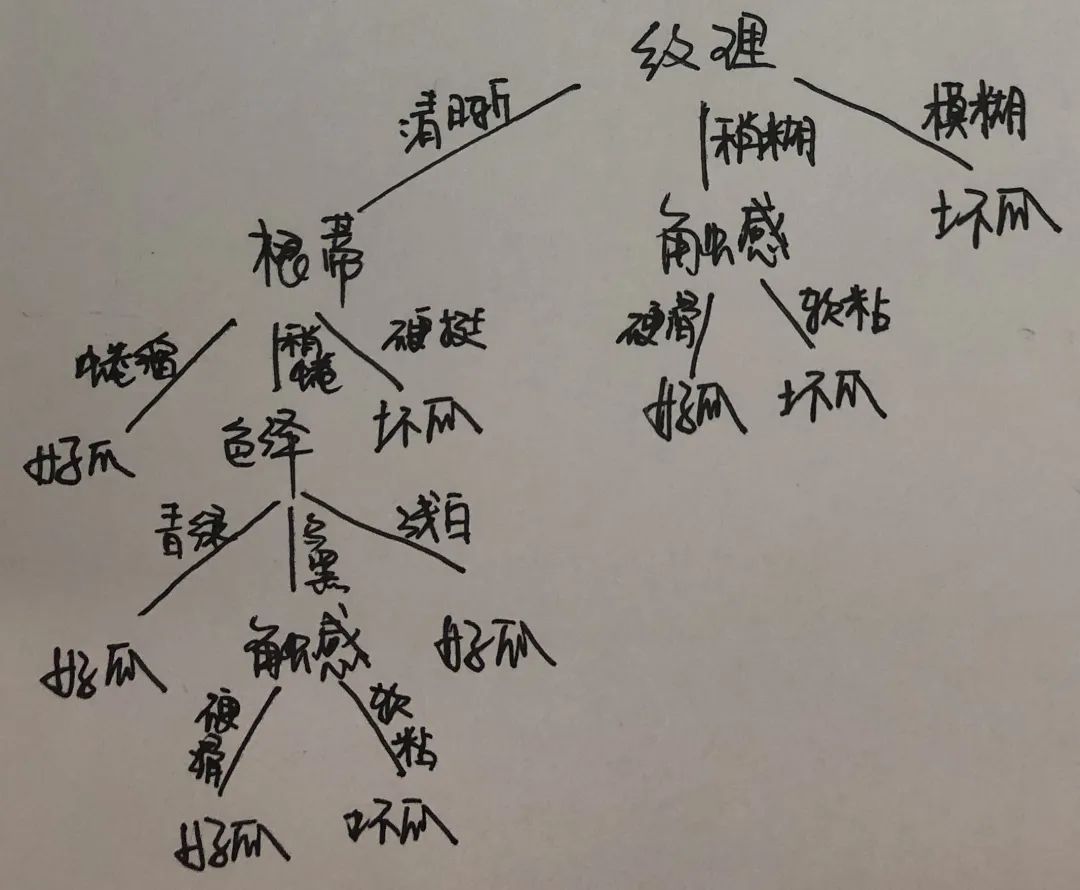
C4.5决策树学习算法
根据信息增益的公式我们可以看到,信息增益准则对取值数目较多的属性有所偏好。所以C4.5决策树算法不使用信息增益,而是增益率来选择最优划分属性。增益率定义为:

其中IV可以定义为:

其中IV称为属性a的固有值,以下计算可以看到,属性a的可取值数目越多,IV越大。

CART决策树学习算法
CART决策时使用基尼指数来选择划分属性,公式如下:

pk代表样本中第k类样本所占比例,所以pk的平方再求和是随机抽取两个样本,是同类样本的比例。那么基尼指数代表的就是随机抽取两个样本,不是同类样本的比例。所以基尼指数越小,样本纯度越高。
对于属性a的基尼指数可以定义为:

由此类推,只需不断选择最小的属性基尼指数作为最优划分属性即可。
以上,就是三种最经典的决策树啦,你学会了吗?
喜欢的就点个关注吧❤️。会持续更新机器学习以及人工智能算法,并不定时赠送学习资料~
















 1885
1885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









