







文章目录
回归任务
均方误差(mean squared error, MES)
MSE ( y , y ^ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \operatorname{MSE}(y, \hat{y})=\frac{1}{n} \sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2} MSE(y,y^)=n1i=1∑n(yi−y^i)2
精度(accuracy)
分类正确的样本个数
accuracy
(
y
,
y
^
)
=
1
n
∑
i
=
1
n
1
(
y
^
i
=
y
i
)
\operatorname{accuracy}(y, \hat{y})=\frac{1}{n} \sum_{i=1}^{n} 1\left(\hat{y}_{i}=y_{i}\right)
accuracy(y,y^)=n1i=1∑n1(y^i=yi)
分类任务
混淆矩阵
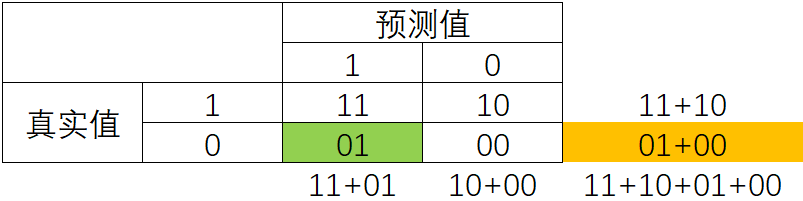
混淆矩阵阵如其名,十分容易让人混淆,在许多教材中,混淆矩阵中各种各样的名称和定义让大家难以理解难以记忆。我为大家找出了一种简化的方式来显示标准二分类的混淆矩阵,如图所示:
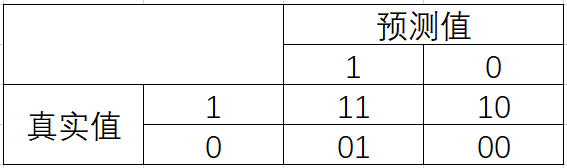
真实值和预测值相同则说明预测正确了。我们约定,少数类为1,多数类为0。

模型整体效果:accuracy
整体效果指的是同时考量少数类和多数类。
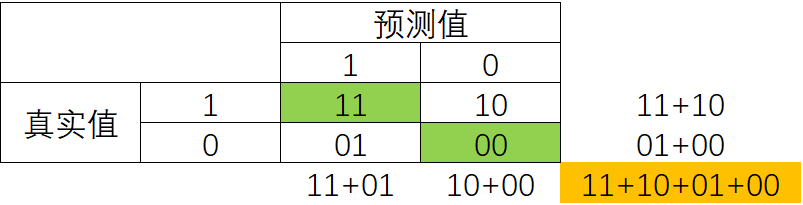
准确率Accuracy就是所有预测正确的所有样本除以总样本,通常来说越接近1越好。
Accuracy
=
11
+
00
11
+
10
+
01
+
00
\text { Accuracy }=\frac{11+00}{11+10+01+00}
Accuracy =11+10+01+0011+00
捕捉少数类的艺术:精确度、召回率和F1 score
精确度(查准率、Precision)
精确度Precision,又叫查准率,表示所有被我们预测为是少数类的样本中,真正的少数类所占的比例。
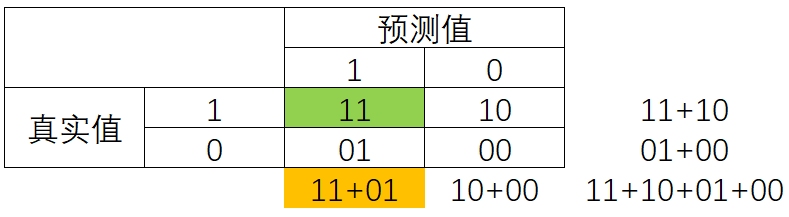
Precision = 11 11 + 01 \text { Precision }=\frac{11}{11+01} Precision =11+0111
- 精确度越高:代表我们对少数类预测越准确。
- 精确度越低:代表我们误伤了过多的多数类。
- 精确度可以看做对多数类误伤的衡量
召回率(查全率、敏感度、真正率、Recall)
召回率Recall,又被称为敏感度(sensitivity),真正率,查全率,表示所有真实为1的样本中,被我们预测正确的样本所占的比例。
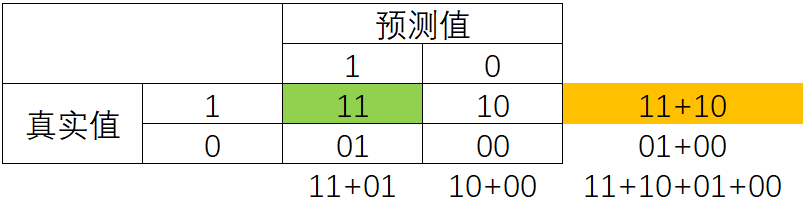
捕捉少数类,当然衡量的是少数类的比例了,所以以11为分子。
Recall
=
11
11
+
10
\text { Recall }=\frac{11}{11+10}
Recall =11+1011
- 召回率越高:代表我们尽量捕捉出了少数类
- 召回率越低:代表我们没有捕捉出足够的少数类
- 召回率可以看做捕捉少数类的能力
| 注意: |
|---|
precision和recall的分子都是11。所以二者是此消彼长的关系。如果想尽可能捕捉少数类,那就会更多误伤多数类;反之,想要少误伤多数类,也不可能捕捉更多少数类。所以,需要有一个平衡二者的评价指标。这个指标就是F1 measure。 |
F1 measure
两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此我们追求尽量高的F1 measure, 能够保证我们的精确度和召回率都比较高。F1 measure在[0,1]之间分布,越接近1越好。
F
−
measure
=
1
1
Precision
+
1
Recall
=
2
∗
Precision
∗
Recall
Precision
+
Recall
F-\text { measure }=\frac{1}{\frac{1}{\text { Precision }}+\frac{1}{\text { Recall }}}=\frac{2 * \text { Precision } * \text { Recall }}{\text { Precision }+\text { Recall }}
F− measure = Precision 1+ Recall 11= Precision + Recall 2∗ Precision ∗ Recall
F β \mathbf{F_\beta} Fβ加权调和平均
F β = ( 1 + β 2 ) × P × R ( β 2 × P ) + R F_{\beta}=\frac{\left(1+\beta^{2}\right) \times P \times R}{\left(\beta^{2} \times P\right)+R} Fβ=(β2×P)+R(1+β2)×P×R
- β = 1 \beta=1 β=1,标准F1 measure
- β > 1 \beta>1 β>1,偏重查全率,捕捉少数类的能力
- β < 1 \beta<1 β<1,偏重查准率,别误伤多数类的能力
| 另外一种平衡方法 |
|---|
| 二者有一个此消彼长的关系,我们可以将其关系的曲线绘制出来,找到一个尽量平衡二者的点,使其都很高。 |
P-R曲线
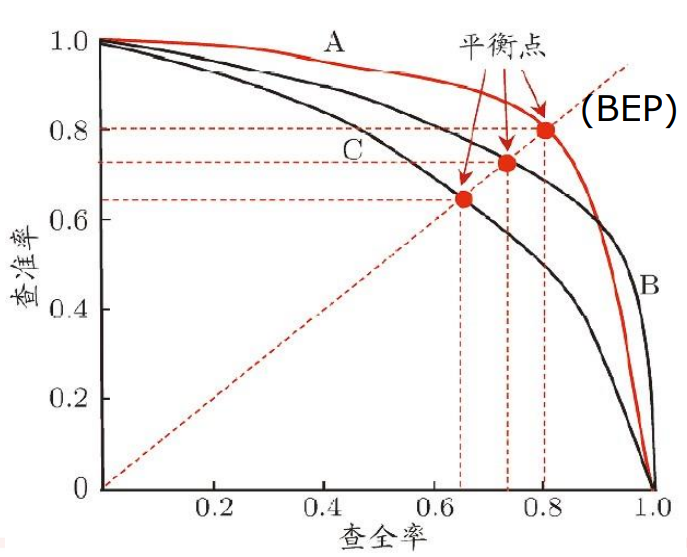
- P-R曲线如何评估模型
- p-r图
- 算面积
- BEP
- 平衡点靠右上的
- p-r图
如何绘制P-R曲线?
(西瓜书中描述绘制P-R曲线过程如何理解? - 知乎 (zhihu.com)
判错多数类的考量:特异度与假正率
特异度(specificity)
特异度(Specificity)表示所有真实为0的样本中,被正确预测为0的样本所占的比例。
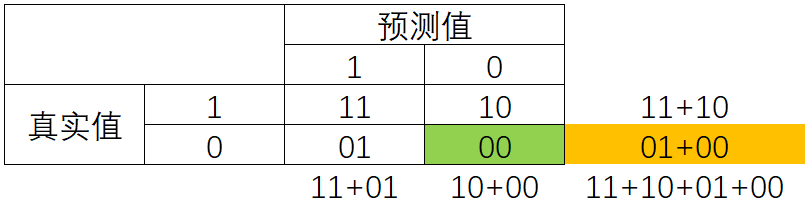
特异度衡量了一个模型将多数类判断正确的能力
S
p
e
c
i
f
i
c
i
t
y
=
00
01
+
00
Specificity=\frac{00}{01+00}
Specificity=01+0000
假正率(False Positive Rate, FPR)
特异度衡量了一个模型将多数类判断正确的能力,而1 - specificity就是一个模型将多数类判断错误的能力,这种能力被计算如下,并叫做假正率(False Positive Rate):
ROC曲线,AUC面积
我们可以将ROC曲线类比P-R曲线
| X轴 | Y轴 | |
|---|---|---|
| P-R曲线 | Recall:捕捉少数类的能力 | Precision:别误伤了多数类的能力 |
| ROC曲线 | FPR:误伤多数类 | TPR(Recall):捕捉少数类的能力 |
绘制过程与P-R曲线相同。
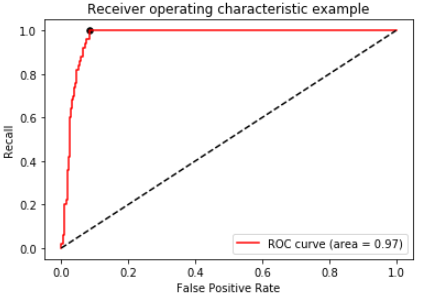
那个黑色的点,越靠近左上方越好。
legend中的面积,就是AUC面积,越大越好。AUC计算公式如下:
A
U
C
=
∑
i
=
1
n
0
r
i
−
n
0
×
(
n
0
+
1
)
/
2
n
0
×
n
1
A U C=\frac{\sum_{i=1}^{n_{0}} r_{i}-n_{0} \times\left(n_{0}+1\right) / 2}{n_{0} \times n_{1}}
AUC=n0×n1∑i=1n0ri−n0×(n0+1)/2
- n 0 n_0 n0和 n 1 n_1 n1分表表示反例和正例的个数
- r i r_i ri表示第i个反例的排序序号
AUC计算的一个例子

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











