







提示:transformer结构的目标检测解码器,包含loss计算,附有源码
前言
最近重温DETR模型,越发感觉detr模型结构精妙之处,不同于anchor base 与anchor free设计,直接利用100框给出预测结果,使用可学习learn query深度查找,使用二分匹配方式训练模型。为此,我基于detr源码提取解码decode、loss计算等系列模块,并重构、修改、整合一套解码与loss实现的框架,该框架可适用任何backbone特征提取接我框架,实现完整训练与预测,我也有相应demo指导使用我的框架。那么,接下来,我将完整介绍该框架源码。同时,我将此源码进行开源,并上传github中,供读者参考。
一、main函数代码解读
1、整体结构认识
在介绍main函数代码前,我先说下整体框架结构,该框架包含2个文件夹,一个losses文件夹,用于处理loss计算,一个是obj_det文件,用于transformer解码模块,该模块源码修改于detr模型,也包含main.py,该文件是整体解码与loss计算demo示意代码,如下图。
2、main函数代码解读
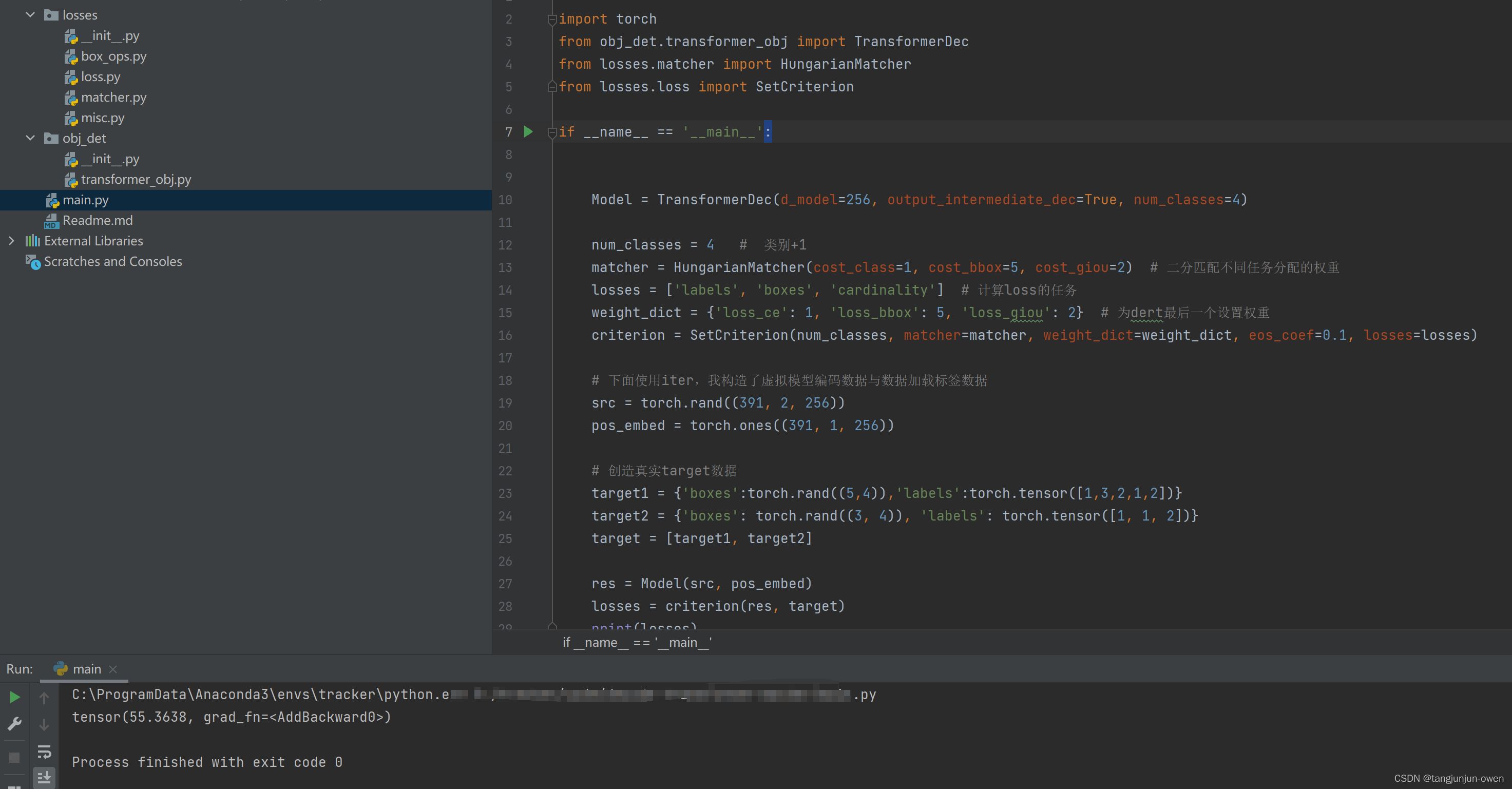
该代码实际是我随机创造了标签target数据与backbone特征提取数据及位置编码数据,使其能正常运行的demo,其代码如下:
import torch
from obj_det.transformer_obj import TransformerDec
from losses.matcher import HungarianMatcher
from losses.loss import SetCriterion
if __name__ == '__main__':
Model = TransformerDec(d_model=256, output_intermediate_dec=True, num_classes=4)
num_classes = 4 # 类别+1
matcher = HungarianMatcher(cost_class=1, cost_bbox=5, cost_giou=2) # 二分匹配不同任务分配的权重
losses = ['labels', 'boxes', 'cardinality'] # 计算loss的任务
weight_dict = {
'loss_ce': 1, 'loss_bbox': 5, 'loss_giou': 2} # 为dert最后一个设置权重
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict, eos_coef=0.1, losses=losses)
# 下面使用iter,我构造了虚拟模型编码数据与数据加载标签数据
src = torch.rand((391, 2, 256))
pos_embed = torch.ones((391, 1, 256))
# 创造真实target数据
target1 = {
'boxes':torch.rand((5,4)),'labels':torch.tensor([1,3,2,1,2])}
target2 = {
'boxes': torch.rand((3, 4)), 'labels': torch.tensor([1, 1, 2])}
target = [target1, target2]
res = Model(src, pos_embed)
losses = criterion(res, target)
print(losses)
如下图:
3、源码链接
github源码链接:点击这里
百度网盘源码链接:
链接:https://pan.baidu.com/s/1r9q_et6AVT6Rdx7_2-7X5w
提取码:detr
二、decode模块代码解读
该模块主要是使用transform方式对backbone提取特征的解码,主要使用learn query等相关trike与transform解码方式内容。
我主要介绍TransformerDec、TransformerDecoder、DecoderLayer模块,为依次被包含关系,或说成后者是前者组成部分。
1、decoded的TransformerDec模块代码解读
该类大意是包含了learn query嵌入、解码transform模块调用、head头预测logit与boxes等内容,是实现解码与预测内容,该模块参数或解释已有注释,读者可自行查看,其代码如下:
class TransformerDec(nn.Module):
'''
d_model=512, 使用多少维度表示,实际为编码输出表达维度
nhead=8, 有多少个头
num_queries=100, 目标查询数量,可学习query
num_decoder_layers=6, 解码循环层数
dim_feedforward=2048, 类似FFN的2个nn.Linear变化
dropout=0.1,
activation="relu",
normalize_before=False,解码结构使用2种方式,默认False使用post解码结构
output_intermediate_dec=False, 若为True保存中间层解码结果(即:每个解码层结果保存),若False只保存最后一次结果,训练为True,推理为False
num_classes: num_classes数量与数据格式有关,若类别id=1表示第一类,则num_classes=实际类别数+1,若id=0表示第一个,则num_classes=实际类别数
额外说明,coco类别id是1开始的,假如有三个类,名称为[dog,cat,pig],batch=2,那么参数num_classes=4,表示3个类+1个背景,
模型输出src_logits=[2,100,5]会多出一个预测,target_classes设置为[2,100],其值为4(该值就是背景,而有类别值为1、2、3),
那么target_classes中没有值为0,我理解模型不对0类做任何操作,是个无效值,模型只对1、2、3、4进行loss计算,然4为背景会比较多,
作者使用权重0.1避免其背景过度影响。
forward return: 返回字典,包含{
'pred_logits':[], # 为列表,格式为[b,100,num_classes+2]
'pred_boxes':[], # 为列表,格式为[b,100,4]
'aux_outputs'[{
},...] # 为列表,元素为字典,每个字典为{
'pred_logits':[],'pred_boxes':[]},格式与上相同
}
'''
def __init__(self, d_model=512, nhead=8, num_queries=100, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False, output_intermediate_dec=False, num_classes=1):
super().__init__()
self.num_queries = num_queries
self.query_embed = nn.Embedding(num_queries, d_model) # 与编码输出表达维度一致
self.output_intermediate_dec = output_intermediate_dec
decoder_layer = DecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=output_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
# 设置head头提取
self.num_classes=num_classes
self.class_embed = nn.Linear(d_model, num_classes + 1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3515
3515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











