







- 生成模型:由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。一般将隐变量z可视为公式中的y。典型的生成模型如朴素贝叶斯。
- 判别模型:数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。如k近邻、决策树、SVM直接面对预测,往往准确率较高。
1. AutoEncoder
- 即N层的神经网络,输入数据和输出数据一致,将隐层设置为较低的维度,学习出原始数据的较低维的隐层特征,误差函数使用MSE。
- 应用:
- 去噪(对输入加入随机噪声,对于的输出使用真实不加噪声的数据)
- 降维
2.Variational Autoencoder
-
考虑AE的Decoder部分,如果我们已知一个数据的隐层表示,那么将这个表示送入Decoder网络,我们就可以生成一个样本。但是我们无法随意的生成一个符合要求的隐表示,因为隐表示的分布可能很复杂。
-
现在我们通过Encoder网络不仅仅学习它的隐表示,而是要学习隐表示的分布。假定隐表示向量的每一维都服从一个高斯分布,那么学习的就是每个高斯分布的均值和方差。

-
通过重参技巧,可以从上述均值和方差组成的高斯分布中采样得到隐层节点,在用隐层节点向量输入Decoder网络,得到重构的图像。(重参:对标准高斯采样得到一个 z z z,对他进行线性变换 μ + σ z μ+σz μ+σz即可得到服从要求分布的隐层节点。)
-
当我们的网络学习好了之后,每次采样得到一组 z z z,都可以生成一幅相应的图像,这就达到了生成图像的作用。
-
- 模型的损失函数包括三部分:1.重构误差(MSE或交叉熵(即似然)) 2. 分布误差 3.正则项,现在主要推导第二项分布误差,最终的总LOSS就是三者之和。
- 分布误差:假定
z
z
z的后验
p
1
p_1
p1服从高斯分布,但是这个高斯分布应该向标准高斯分布
p
2
p_2
p2看齐。这是因为如果没有这项损失,模型会倾向于使得整个网络的重构误差趋于0,这必然导致隐变量
z
z
z失去随机性,在直白一点就是
z
z
z的方差会趋近于0,这样模型就会退化为AE。解决办法就是在损失函数中增加后验分布
p
1
p_1
p1与标准高斯分布的KL距离。这样,模型会自动的在重构与生成间平衡。
多元高斯分布的pdf为:
p ( x 1 , x 2 , . . . x n ) = 1 2 π d e t ( Σ ) e − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) p(x_1,x_2,...x_n)=\frac{1}{\sqrt{2\pi det(\Sigma)}}e^{-\frac{1}{2}(x-\mu)^T \Sigma^{-1}(x-\mu)} p(x1,x2,...xn)=2πdet(Σ)1e−21(x−μ)TΣ−1(x−μ)
假设各维度独立,则可分别为 n n n个一维的高斯分布,高斯分布的pdf为:
N ( μ , σ ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 N(\mu,\sigma)=\frac{1}{\sqrt{2\pi }\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} N(μ,σ)=2πσ1e−2σ2(x−μ)2
KL距离公式为:
K L ( p ∣ ∣ q ) = ∫ p ( x ) l o g p ( x ) q ( x ) KL(p||q) = \int p(x)log\frac{p(x)}{q(x)} KL(p∣∣q)=∫p(x)logq(x)p(x)
计算两个高斯分布的KL距离,其步骤如下

注意最后一项积分结果就是方差

模型假设 p 2 p_2 p2服从标准高斯分布,即 μ 2 = 0 , σ 2 = 1 \mu_2=0,\sigma_2=1 μ2=0,σ2=1代入上式,可得
K L = − l o g σ 1 + 1 2 ( μ 1 2 + σ 1 2 ) − 1 2 KL=-log\sigma_1+\frac{1}{2}(\mu_1^2+\sigma_1^2)-\frac{1}{2} KL=−logσ1+21(μ12+σ12)−21
将上式作为分布的距离损失加入到损失函数Loss中即可
-
Trick:
- 学习方差时,由于方差必须非负,所以我们不直接计算方差 v a r var var,而是计算对数方差 l g ( v a r ) lg(var) lg(var),然后重参数的时候,对他取指数 e l g ( v a r ) e^{lg(var)} elg(var)即可得到正常的方差。
3. GAN

-
核心原理:
- 假设数据 x x x服从某个分布 p d a t a p_{data} pdata,我们不知道这个分布是什么样子,但是我们可以用另一个分布 p z p_z pz和一个生成器 G ( z ) G(z) G(z)逼近这个分布,使得生成器的分布和数据的分布一致。
- 正如图中数据分布是黑线不动,我们一直调整绿色的生成器分布,直到两个分布重合。当两个分布重合时,由生成器产生的数据可以认为就是真正的数据,我们便可以从中采样得到新的样本。
- 图中的蓝线表示经过判别器 D ( x ) D(x) D(x)后模型的判别结果,若认为是真实图片输出1,否则输出0。当判别结果无法正确区分样本来自真实数据还是由生成器产生的数据时认为模型训练完成。
-
损失函数:
min G max D E x ∼ P d a t a [ l o g D ( x ) ] + E z ∼ P z [ 1 − l o g D ( G ( z ) ) ] \min\limits_{G} \max\limits_{D} E_{x\sim P_{data}}[logD(x)]+ E_{z\sim P_{z}}[1-logD(G(z))] GminDmaxEx∼Pdata[logD(x)]+Ez∼Pz[1−logD(G(z))]- 损失函数由两部分组成:
- 从分类器 D D D的角度来看,我们希望最大化区分样本来自真是分布还是虚假分布。(前一项来自真是分布–最大化;后一项是负的虚假分布,也是最大化)
- 从生成器 G G G角度来看,正好相反。
- 损失函数由两部分组成:
-
G G G和 D D D的实际组成:
- 可根据要求使用任何的网络(CNN,MLP等),我们的目标是学习它的权系数。
-
生成网络 G G G的输入:
- 一组从标准高斯采样得到的噪声向量。
-
模型优点:
- 基于BP反向传播
- 不需要计算隐变量的分布(从标准高斯采样就行)
- 增加D和G的深度可以增加性能
- G的分布不依赖样本,依赖于判别器的误差传播
-
模型缺点:
- G分布没有显示的表达,仅仅是一个复杂的映射函数,可解释性差
- 很难训练(不稳定),一般可设置D更新K次而G更新1次
4. 补充 VAEGAN
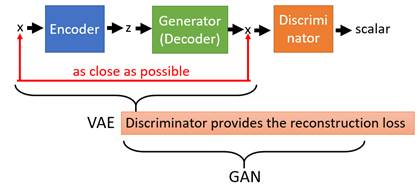
-
VAE:输入图像–高斯的隐层–重构回原始输入图像
-
GAN:
- 随机噪声Z–(生成器G)–假的图像–判别器D判别
- 真实图像–判别器D判别
-
问题:VAE生成的图像模糊
-
VAEGAN:给VAE加上了GAN的架构,通过判别器D使得VAE产生的图片变得清晰。VAEGAN就是利用GANs去提升了VAE的图片生成质量。
-
操作:真实图像 x i n x_{in} xin经过VAE得到重构的图像 x o u t x_{out} xout,将 x o u t x_{out} xout送入一个GAN网络的判别器(注意 不是整个GAN,只有判别器),让判别器判断输入图像来自真实分布还是生成分布。(此时GAN的生成器就相当于VAE的decoder部分)















 3313
3313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









