







最近看到 Mukherjee et al. (2021, JFE) 的文章,受到了点启发,想找中国的云层数据来试试,但是没有质量特别高的数据,只好老老实实按照这篇论文中的做法从NOAA 下数据洗出来。
数据来源
数据源为 NCDC(美国国家气候数据中心,National Climatic Data Center),隶属于NOAA(美国国家海洋及大气管理局,National Oceanic and Atmospheric Administration)。
数据来自NCDC的公开FTP服务器中的 ftp://ftp.ncdc.noaa.gov/pub/data/noaa/isd-lite/。
为了方便查看,文章中提到的所有数据源文件都可以在我的百度网盘分享链接里找到。
链接: https://pan.baidu.com/s/1GraMF6SgSg3DBIPxVNlgQQ 密码: l8j9
分析样本为 2000-2020 年间中国的地面气象数据 (每三小时记录一次)。
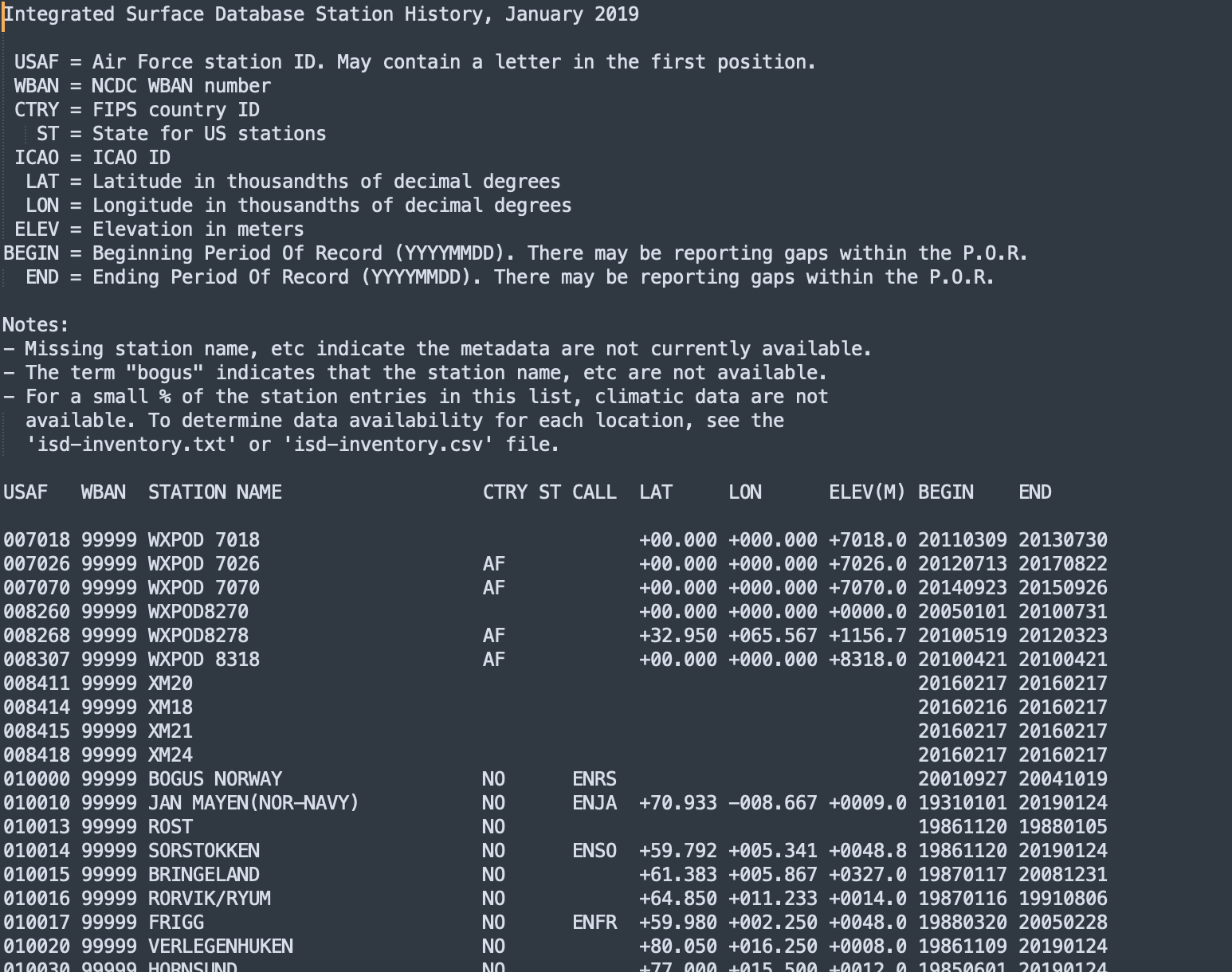
原始数据结构
以2020年为例,文件命名方式为 气象站id - 99999 (NCDC WBAN Number) - 年份。
先看一个样例文件,该文件有 9 列,其变量按顺序分别为 观测年份,观测月份,观测日期,观测小时,空气温度,露点温度,海平面气压,风向,风速,云层厚度,液体渗透深度(1小时),液体渗透深度(6小时)。
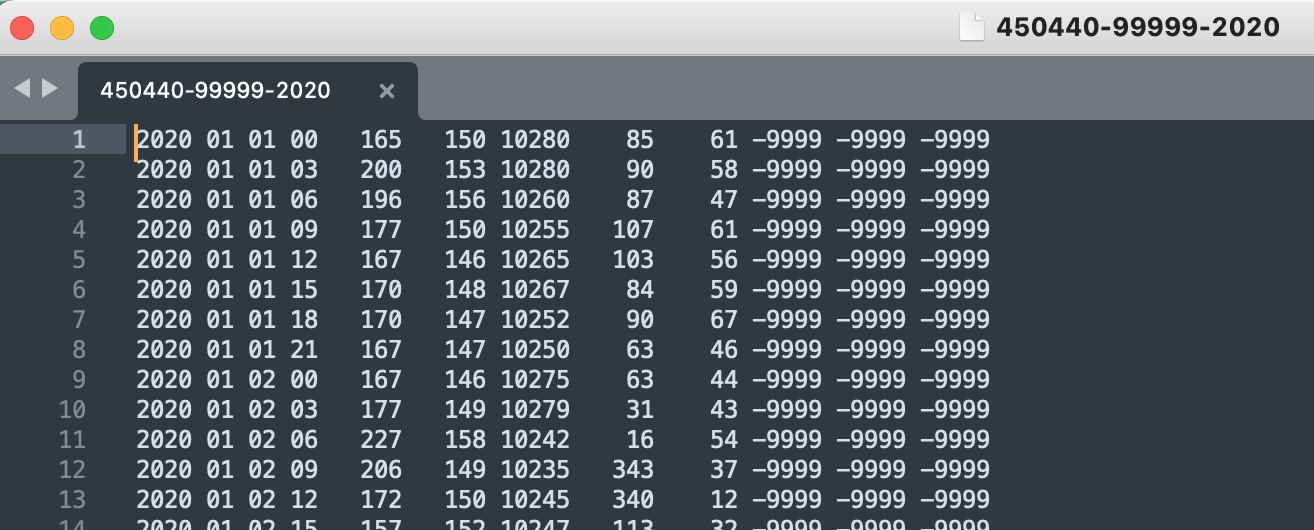
详细变量说明如下:
Introduction
The ISD-Lite data contain a fixed-width formatted subset of the complete Integrated Surface Data (ISD) for a select number of observational elements. The data are typically stored in a single file corresponding to the ISD data, i.e. one file per station per year. For more information on the ISD-Lite format, consult the ISD-Lite technical document.
Data Format
Field 1: Pos 1-4, Length 4: Observation Year
Year of observation, rounded to nearest whole hour
Field 2: Pos 6-7, Length 2: Observation Month
Month of observation, rounded to nearest whole hour
Field 3: Pos 9-11, Length 2: Observation Day
Day of observation, rounded to nearest whole hour
Field 4: Pos 12-13, Length 2: Observation Hour
Hour of observation, rounded to nearest whole hour
Field 5: Pos 14-19, Length 6: Air Temperature
The temperature of the air
UNITS: Degrees Celsius
SCALING FACTOR: 10
MISSING VALUE: -9999
Field 6: Pos 20-24, Length 6: Dew Point Temperature
The temperature to which a given parcel of air must be cooled at constant pressure and water vapor content in order for saturation to occur.
UNITS: Degrees Celsius
SCALING FACTOR: 10
MISSING VALUE: -9999
Field 7: Pos 26-31, Length 6: Sea Level Pressure
The air pressure relative to Mean Sea Level (MSL).
UNITS: Hectopascals
SCALING FACTOR: 10
MISSING VALUE: -9999
Field 8: Pos 32-37, Length 6: Wind Direction
The angle, measured in a clockwise direction, between true north and the direction from which the wind is blowing.
UNITS: Angular Degrees
SCALING FACTOR: 1
MISSING VALUE: -9999
*NOTE: Wind direction for calm winds is coded as 0.
Field 9: Pos 38-43, Length 6: Wind Speed Rate
The rate of horizontal travel of air past a fixed point.
UNITS: meters per second
SCALING FACTOR
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









