







目录
3.尝试复现CneterNet--INSTALL.md安装:
1.关键部分Heatmap了解
- 可以看懂的资料:
1.通俗地讲明白了heatmap的计算方法:http://bindog.github.io/blog/2018/02/10/model-explanation/
2.收集了关于卷积神经网络可视化以及热力图的资料:https://blog.csdn.net/baidu_40840693/article/details/85055520
3.这里有提到关键点检测的知识,可以很好地理解conternet论文中两种关键点生成的方式:https://blog.csdn.net/qq_21033779/article/details/84840307
- 我看到的资料中会把heatmap称为热图或是热力图
- 提炼资料1的基本概念--一种CAM结构的热力图计算方式:
| 原有的网络:最后一层卷积层+全连接层+softmax CAM的网络:最后一层卷积层+GAP+softmax 【经过GAP之后与输出层的连接关系(暂不考虑softmax层),实质上也是就是个全连接层,只不过没有了偏置项】 经过GAP以后得到-->最后一个卷积层每个特征图的均值 将这些均值加权和后传给softmax(权重
计算热力图:对每一类别,将最后一层的特征图分别乘以对应的权重就能得到相应的热力图
|

一种Grad-CAM结构的热力图计算方式:【改进GAM,不用改变模型结构】
| 生成热力图的关键: Grad-CAM与GAM不同用梯度的全局平均来计算权重。
Z为特征图的像素个数,
|
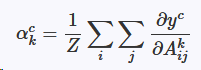

2.Centernet论文细节:
【因为我是目标检测方向,所以专注在了检测部分】
参考博客:
1.https://blog.csdn.net/c20081052/article/details/89358658
2.https://www.jianshu.com/p/0ef56b59b9ac
1.特点:
- Anchor free,可以完成多种视觉任务的网络:目标检测问题变成了一个标准的关键点估计问题,将图像传入全卷积网络,得到一个热力图,热力图峰值点即中心点,目标的宽高信息由每个峰值点周围的图像特征回归得到,并回归到其他目标属性,例如尺寸,3D位置,方向,甚至姿态。
- 端到端,能够很好地平衡效率和精度。没有NMS等后处理
2.Anchor存在的问题:
- anchor数量巨大,会导致样本不均衡,anchor人工自主设计,anchor与gt不对齐不利于分类,且会引入更多的超参数
3.原理:
简单地,通过主网络得到图片的特征图,再通过高斯核函数将关键点分布到特征图上;根据特征图上的值帅选出100个大于或者等于周围8个相邻值的点作为初步预测的中心关键点,然后对每个关键点都进行C个类别的置信度计算,以及关键点偏移的预测值和bbox的长宽;最后根据置信度选择最终的预测结果。


1.预备工作:
首先输入图像为,目标输出则是生成关键点的热力图
,R为变换尺度,C为关键点类型数目(输出特征通道数,类别数)。【这里只关注目标检测部分嗷】论文中的C值是80,目标检测的类别数;R=4;且
=1时表示有目标关键点,
=0时表示为背景。
为生成热力图使用的基本框架有三种:stacked hourglass network,ResNet,deep layer aggregation (DLA)
【训练关键点预测网络:参照了Conernet】
2.找到关键点:
Ground Truth每个类别c的关键点p,首先要计算一个a low-resolution equivalent的值,再通过高斯核计算的到在热力图上的关键点为:
[如果同一类别的两个高斯分布重合了,我们使用逐个像素点取最大值的方法来处理。]
训练的目标函数是一个像素级逻辑回归的focal loss:【我之前看过这个论文!不用重新看了!开心】
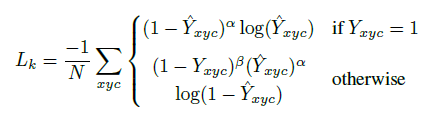
式中: 分别为focal loss 的超参数,分别设置为2和4;
N 是图像中的关键点个数,使用其进行归一化相当于将所有正例 focal loss 规范化为1;
otherwise 情况其实表示为负样本
为预测值,通过预测与真实值之间的loss进行训练【这里是分类】
关于loss的解释:


此外,文中对每个关键点都额外的预测了offset-,使用的是L1 Loss:【这里是对关键点偏移量的预测】
【表示的是标注信息从输入图像映射到输出特征图时由于取整操作带来的坐标误差,所有类别 c 共享同个偏移预测】
3.找到关键点对应的中心点:
首先令为目标k对应类别C,即
的坐标 ,有中心点
【这里都是真实值】
使用找到的关键点预测中心点【这里是预测值】,此外每个目标K都对目标大小
【这里也是真实值】都进行回归。
预测中心点的loss:
就有总loss:
其中:=0.1,
=1;分别预测了
,
,
;
推理出BBOX:
【这里,整个模型除了识别属性以外,只对四个值进行回归(x,y,w,h):中心点(x,y),以及bbox的(w,h)】
1.通过主网络得到图片的特征图,再通过高斯核函数将关键点分布到特征图上;根据特征图上的值帅选出100个大于或者等于周围8个相邻值的点作为初步预测的中心关键点;
2.通过网络预测出中心关键点的偏移量【因为提取特征尺度缩放后会有偏差】
3.再通过网络预测出bbox的大小
【这一步,应该是已知真实(通过之前定义的公式可以求出来),再根据网络预测的值
(这里一开始应给有初始化,具体初始化的值是多少还要看代码),最后通过
得到最终的回归值】
4.最终有预测bbox坐标值:
3.尝试复现CneterNet--INSTALL.md安装:
[崩溃之后再书写...我刚写的全没了...遇到的问题..我凭着印象写写吧]
[我之前都是用的caffe,这次算是摸索摸索吧]
1.用anaconda3创建一个干净的环境,安装pytorch:
conda create --name CenterNet python=3.6
'激活它'
conda activate CenterNet2. 安装pytorch:
A.按照官方的安装代码,我是无法安装成功的
1)‘pytorch-0.4.1-py36_py35_py27__9.0.176_7.1.2_2.tar.bz2’无法下载下来
2)没法一次性安装pytorch=0.4.1和torchvision
按照如下步骤:
1.在https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/中下载
pytorch-0.4.1-py36_py35_py27__9.0.176_7.1.2_2.tar.bz2
2.conda install pytorch=0.4.1 -c pytorch
3.conda install =torchvisionB.And disable cudnn batch normalization
>>python3.6
>>import torch
>>print(torch.backends.cudnn.version())
>>7102
&HOME>>sed -i "7102s/torch\.backends\.cudnn\.enabled/False/g" /home/ubuntu247/anaconda3/envs/CenterNet/lib/python3.6/site-packages/torch/nn/functional.py
3.安装COCOAPI
# COCOAPI=/path/to/clone/cocoapi
git clone https://github.com/cocodataset/cocoapi.git $COCOAPI
cd $COCOAPI/PythonAPI
make
'注意一点如果你的python默认不是python3.6的话手动更改一下Makefile里Python的版本'
python3.6 setup.py install --user
'这里的python一样'4.Clone Centernet:
CenterNet_ROOT=/path/to/clone/CenterNet
git clone https://github.com/xingyizhou/CenterNet $CenterNet_ROOT5.Install the requirements
[因为我们服务器里python版本实在太多了,但又不能随便更改,怕影响别人的工作,所以如下]
pip install -r requirements.txt
改为:
python3.6 -m pip install -r requirements.txt6.Compile deformable convolutional (from DCNv2)
--DCNv2的编译:
cd $CenterNet_ROOT/src/lib/models/networks/DCNv2
./make.sh【问题:nvcc:找不到命令,以及sudo python3.6 找不到命令】
【nvcc的问题有人是与CUDA的版本不匹配,但我的不是】
都是因为没有跟系统环境连接,所以使用sudo的时候命令行找不到:
1.path=which nvcc
2.sudo ln -s /path /sbin/nvcc #path是上一步得到的位置
'python3.6是一样的'
3.sudo ln -s /path_python3.6 /usr/bin/python3.67.Compile NMS if your want to use multi-scale testing or test ExtremeNet:
cd $CenterNet_ROOT/src/lib/external
make
'一样啦,也要改改Makefile中的python版本'【本来还有编译成功的示例图,电脑崩溃就没有了..】
4.尝试复现CneterNet--跑跑demo.py:
1.下载model惹:ctdet_coco_dla_2x.pth
放一个百度云链接:https://pan.baidu.com/s/1yk6PEjZN_kf8qbGDWu57WQ 提取码:vsgg
2.运行demo.py
将pose_dla_dcn.py的488行改为:pretrained=False
不改的话在运行demo.py时会报错:
RuntimeError: invalid hash value (expected "ba72cf86", got "14cd8aa9060346eea8b3fb0525ff2e77ac90e9835ec83b9314845da20bd546ba")def get_pose_net(num_layers, heads, head_conv=256, down_ratio=4):
model = DLASeg('dla{}'.format(num_layers), heads,
pretrained=False,'原来是True'
down_ratio=down_ratio,
final_kernel=1,
last_level=5,
head_conv=head_conv)
return model然后运行demo.py:
python demo.py ctdet --demo /path/to/image/or/folder/or/video --load_model ../models/ctdet_coco_dla_2x.pth
==>
sudo python3.6 demo.py ctdet --demo ../images/33823288584_1d21cf0a26_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth结果:

【问题:遇到了AttributeError: 'NoneType' object has no attribute 'shape'】
解决:就是检测的图片路径没有设置好。
3.测试一下模型结果好不好:
【coco数据集好大啊,不想等重新下一个voc的模型测试一下看看= =】
sudo python3.6 test.py ctdet --exp_id dla --dataset pascal --load_model ../models/ctdet_pascal_dla_384.pth --flip_test结果,就是这样:

5.尝试复现CneterNet--训练一下VOC:
1.Data准备,就按照Data.md中的步骤就可以了【以VOC为例】
cd ~/CenterNet/src/tools
sudo ./get_pascal_voc.sh
'在tools文件夹中会产生一个voc文件夹,把它复制到Data中去'
${CenterNet_ROOT/src/tools}
|-- data
`-- |-- voc
`-- |-- annotations
| |-- pascal_trainval0712.json
| |-- pascal_test2017.json
|-- images
| |-- 000001.jpg
| ......
`-- VOCdevkit2.跟着GET_STARTED.md中的步骤走【以VOC为例】
【标准的example是如下】
cd src
# train
python main.py ctdet --exp_id pascal_dla_384 --dataset pascal --num_epochs 70 --lr_step 45,60
【但是我因为运行的时候出现CUDA out of memory了,所以听作者话将batch_size ,和GPU等参数重新设置,如下】
cd src
# train
sudo python3.6 main.py ctdet --exp_id pascal_dla_384 --dataset pascal --num_epochs 70 --lr_step 45,60 --batch_size 32 --master_batch 15 --lr 1.25e-4 --gpus 0,1
【没用过pytorch啊啊啊啊啊 ,不知道对不对...但是开始训练了,loss也在减小,应该对的吧】
Setting up data...
==> initializing pascal test2007 data.
loading annotations into memory...
Done (t=0.18s)
creating index...
index created!
Loaded val 4952 samples
==> initializing pascal trainval0712 data.
loading annotations into memory...
Done (t=0.54s)
creating index...
index created!
Loaded train 16551 samples
Starting training...
ctdet/pascal_dla_384/home/ubuntu247/anaconda3/envs/CenterNet/lib/python3.6/site-packages/torch/nn/functional.py:52: UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
warnings.warn(warning.format(ret))
/home/ubuntu247/anaconda3/envs/CenterNet/lib/python3.6/site-packages/torch/nn/parallel/_functions.py:58: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
ctdet/pascal_dla_384 | | train: [1][0/517]|Tot: 0:00:12 |ETA: 0:00:00 |loss 90.2083 |hm_loss 85.9
ctdet/pascal_dla_384 | | train: [1][1/517]|Tot: 0:00:13 |ETA: 1:47:31 |loss 85.0136 |hm_loss 81.0
ctdet/pascal_dla_384 | | train: [1][2/517]|Tot: 0:00:15 |ETA: 0:59:57 |loss 82.1809 |hm_loss 78.2
...
...
...
ctdet/pascal_dla_384 |############# | train: [1][223/517]|Tot: 0:05:38 |ETA: 0:07:19 |loss 13.4121 |hm_loss 10
ctdet/pascal_dla_384 |############# | train: [1][224/517]|Tot: 0:05:40 |ETA: 0:07:18 |loss 13.3805 |hm_loss 10
ctdet/pascal_dla_384 |############# | train: [1][225/517]|Tot: 0:05:41 |ETA: 0:07:16 |loss 13.3465 |hm_loss 10
ctdet/pascal_dla_384 |############## | train: [1][226/517]|Tot: 0:05:43 |ETA: 0:07:14 |loss 13.3150 |hm_loss 10
ctdet/pascal_dla_384 |############## | train: [1][227/517]|Tot: 0:05:44 |ETA: 0:07:13 |loss 13.2823 |hm_loss 10
ctdet/pascal_dla_384 |############## | train: [1][228/517]|Tot: 0:05:46 |ETA: 0:07:12 |loss 13.2531 |hm_loss 10那么等训练结束,找张图测一下吧
3.总体测试:【因为网络问题吧,预训练模型没法下载下来,训练的时候是随机初始化,所以精度没有作者提供的模型精度高】
sudo python3.6 test.py ctdet --exp_id dla --dataset pascal --load_model ../exp/ctdet/pascal_dla_384_new/model_best.pth --flip_test
单张图片检测:
这里把demo.py和opts.py复制一份,并改名为:demo_voc.py和opts_voc.py
将opts_voc.py中,338行附近代码进行如下更改:
1).opts_voc:
default_dataset_info = {
'ctdet': {'default_resolution': [512, 512], 'num_classes': 80,
'mean': [0.408, 0.447, 0.470], 'std': [0.289, 0.274, 0.278],
'dataset': 'coco'},
'改为'
default_dataset_info = {
'ctdet': {'default_resolution': [512, 512], 'num_classes': 20,
'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225],
'dataset': 'pascal'},
2).demo_voc.py
from opts import opts
'改为'
from opts_voc import optssudo python3.6 demo_voc.py ctdet --dataset pascal --demo ../images/33823288584_1d21cf0a26_k.jpg --load_model ../exp/ctdet/pascal_dla_384_new/model_best.pth --arch dla_34得到结果对比:【精度明显不高,主要目标还是检测出来了】
作者提供的模型:

自己训练的模型:
















 1635
1635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









