






计算机能理解它们所看到的吗?他们能区分狗和猫,男人和女人,汽车和自行车吗?
目标检测和识别是当今计算机视觉研究的主要领域之一。研究人员正在寻找新的方法使计算机理解它们所看到的东西。新的最先进的模型正在逐步完善,这些模型大幅超过了以前的模型。但是,计算机实际上还远远没有看到它们所看到的东西。
在这篇文章中,我将详细阐述 YOLO [ You Only Look Once ] —— 一项2016年的研究工作,创造了目标检测实时新高。本文简要描述并实现了 YOLO 模型,帮助您进入计算机视觉和计算机视觉目标检测领域。
YOLO 简介
YOLO 将目标检测重构为一个单一的回归问题,直接从图像像素到 bounding box 坐标和类别概率。YOLO 使用单一卷积层同时预测多个 bounding box 及其类别概率。因此,YOLO 的一个主要优点就是我们可以用它来实现以帧为单位的速度检测。即使在这样的速度下,YOLO 仍然能够达到其他实时系统的平均精度(mAP)的两倍以上!
平均平均精度是每个类的平均精度的平均值。换句话说,平均精度是所有类的平均精度。
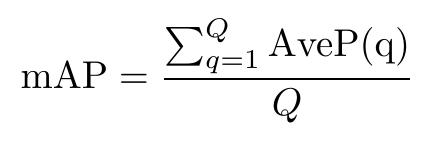
平均精度方程
检测
YOLO 是一个统一的目标检测过程 —— 统一?YOLO 将几个涉及目标检测的任务统一到一个神经网络中。网络在进行 bounding box 预测时会考虑到整个图像。因此,它能够在同一时间预测所有 bounding box 及其类别。
首先,图像被分割成一个 S x S 的网格。如果网格的中心位于网格单元格中,则网格单元格应该能够检测到对象。那么,我们所说的检测是什么意思呢?更准确地说,网格单元预测 B 个 bounding box,并为每个 box 预测其对应的分数,这个分数告诉我们模型对该 box 中包含物体有多高的置信度,以及这个 box 在覆盖物体方面有多精确。因此,这个方框给出了5个预测ー x,y,w,h 和置信度评分。因此,每个网格给了我们 B 个预测。
除了 bounding box 上的预测外,网格单元还给出了 C 个条件类的概率。这些基本上给出了类的概率,假设网格单元包含一个对象。换句话说,假设一个对象存在,条件类概率给出了这个对象可能属于哪个类的概率。每个网格单元只能预测一组类别概率 —— 与 bounding box 的数目无关。
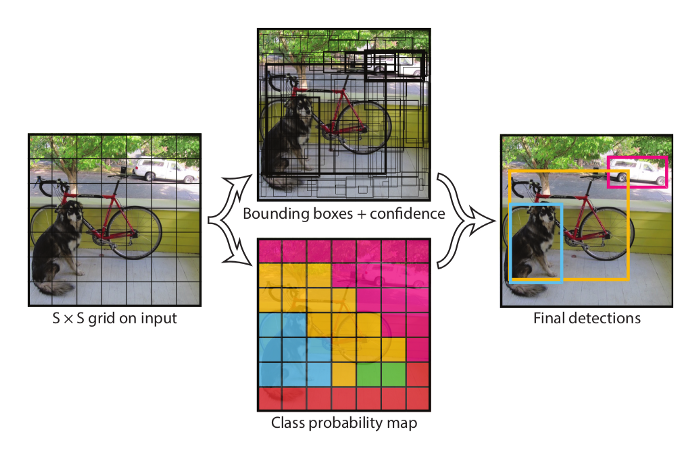
概述该模型的作用
网络
该模型的灵感来自于图像分类的 GoogleNet 模型。它有24个卷积层和2个全连接的层。与 GoogLeNet 使用的初始模块不同,它使用1 × 1缩减层和3 × 3卷积层。
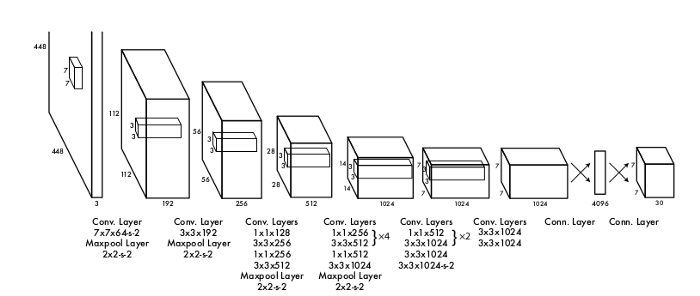
模型架构概述
损失和激活函数
最后一层使用线性激活函数,而其他所有层使用 Leaky-ReLU 激活函数。Leaky-ReLU 激活可以表示为:
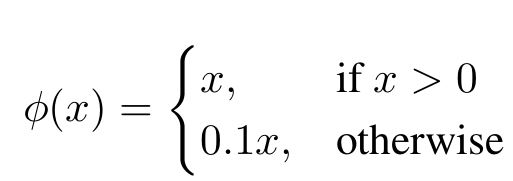
损失函数是简单和平方误差,表示为:
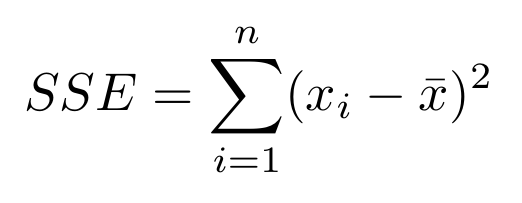
平方和误差
然而,如果我们这样定义损失函数,就会把分类误差和局部化误差混为一谈,从模型的角度来看,两者都非常重要。
为了防止这种情况发生,bounding box 坐标预测的损失会增加,不包含对象的 box 的预测的损失会减少。利用两个参数 λcoord 和 λnoobj 来实现这一结果:
λcoord 设为5,λnoobj 设为0.5(关于这两个超参数在损失函数方程中的详细说明)
SSE 还引入了大小 bounding box 加权误差相等的问题。为了使这个问题形象化,请看下面的图片:

狗和碗的图片(仅供说明)ーー谷歌图片
在这里我们可以看到,狗和碗已经被标注为两个对象。狗的框的尺寸比较大,碗的框的尺寸比较小。现在,如果狗和碗的边界框减少了同样的方形像素,那么碗的标注会更糟糕。为什么?因为 bounding box 的精度在移位和大小方面应该与该 bounding box 的大小相比,而不是图像的大小。
现在,来到我们的损失函数,我们可以看到,损失函数没有给任何具体的 bounding box 的大小。它没有考虑到这一点。为了克服这一障碍,网络不预测 bounding box 的高度和宽度,而是预测 bounding box 的平方根。这有助于将差异保持在最低限度。
综合考虑这些因素,可以将多部分损失函数写成:
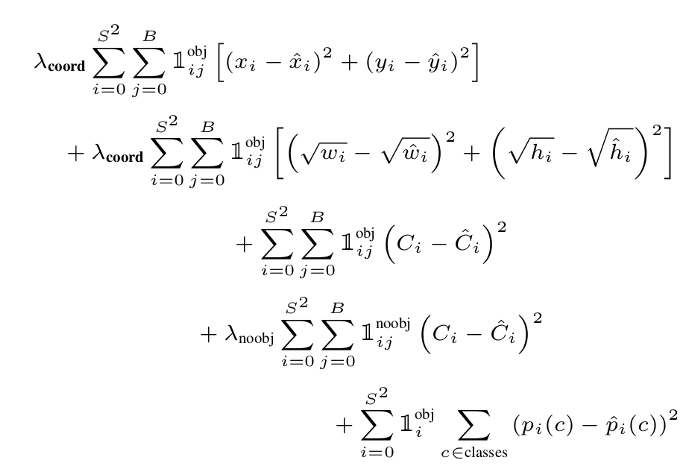
网络的总损失函数
现在我们已经完成了 YOLO/目标检测模型的基础,让我们深入到代码中去吧!
构建模型
YOLO 网络简单易于构建。问题在于 bounding box。绘制边界框和保存图像、标注置信度得分和类别以及配置整个训练代码将使本文不必要地冗余。因此,我将实现该模型。
import torch
from torch import nn
#o = [i + 2*p - k - (k-1)*(d-1)]/s + 1--formula to calculate padding
class Net(nn.Module):
#YOLO model
'''
Input size of the model is
448x448x3
In tensor notation, expressed as [batchsize,3,448,448]
output--
[batchsize,30,7,7]
'''
def __init__(self):
super(Net,self).__init__()
self.t1=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=(7,7),stride=2,padding=(2,2)),
nn.MaxPool2d(kernel_size=(2,2),stride=2),
)
self.t2=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=192,kernel_size=(3,3),padding=(1,1)),
nn.MaxPool2d(kernel_size=(2,2),stride=2),
)
self.t3=nn.Sequential(
nn.Conv2d(in_channels=192,out_channels=128,kernel_size=(1,1)),
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=(1,1)),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=(3,3),padding=(1,1)),
nn.MaxPool2d(kernel_size=(2,2),stride=2),
)
self.t4=nn.Sequential(
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=(1,1)),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=(1,1)),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=(1,1)),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=512,out_channels=256,kernel_size=(1,1)),
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=(1,1)),
nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=(3,3),stride=2)
)
self.t5=nn.Sequential(
nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=(1,1)),
nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=1024,out_channels=512,kernel_size=(1,1)),
nn.Conv2d(in_channels=512,out_channels=1024,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=(3,3),stride=2,padding=(1,1))
)
self.t6=nn.Sequential(
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=(3,3),padding=(1,1)),
nn.Conv2d(in_channels=1024,out_channels=1024,kernel_size=(3,3),padding=(1,1))
)
def forward(self,x):
x=self.t1(x)
x=self.t2(x)
x=self.t3(x)
x=self.t4(x)
x=self.t5(x)
x=self.t6(x)
x=torch.flatten(x,1)
x=nn.Linear(x.size()[1],4096)(x)
x=nn.Linear(4096,7*7*30)(x)
x=x.view(-1,30,7,7)
return x #output of model
YOLO 网络模块
· END ·
HAPPY LIFE
















 752
752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









