






引言
在这篇文章中,我们将了解自动编码器的工作原理以及为什么使用它们来对医学图像进行去噪。
正确理解图像信息在医学等领域至关重要。去噪可以专注于清理旧的扫描图像或有助于癌症生物学中的特征选择工作。噪音的存在可能混淆疾病的识别和分析,可能导致不必要的死亡。因此,医学图像去噪是一项必不可少的前处理技术。
自动编码器技术已被证明对图像去噪非常有用。
自动编码器由两个连接的人工神经网络组成: 编码器模型和解码器模型。自动编码器的目标是找到一种将输入图像编码成压缩形式(也称为潜在空间)的方法,使得解码后的图像版本尽可能接近输入图像。
自动编码器是如何工作的
下面的网络提供了原始图像 x,以及它们的噪声版本 x ~ 。网络试图重建它的输出 x’尽可能接近原始图像 x,通过这样做,它学会了如何对图像进行去噪。
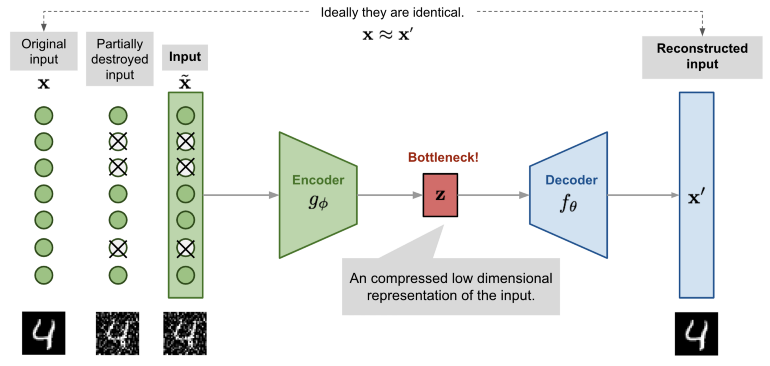
如图所示,编码器模型将输入转换为小的密集表示。解码器模型可以看作是能够生成特定特征的生成模型。
编码器和解码器网络通常作为一个整体进行训练。损失函数惩罚网络以创建与原始输入 x 不同的输出 x'。
通过这样做,编码器学会在潜在空间中保存尽可能多的相关信息,尽可能的去除不相关部分(例如噪声)。解码器则学习获取潜在空间的信息并将其重构为无错的输入。
如何实现自动编码器
让我们实现一个自动编码器来去除手写数字的噪音。输入是一个28x28的灰度图像,构建一个784个元素的矢量。
编码器网络是具有 64 个神经元的单一密集层。因此,潜在空间将具有 64 维。ReLu激活函数附加到层中的每个神经元,并确定是否应该被激活。激活函数还有助于将每个神经元的输出归一化到 1 到 0 之间。
解码器网络是具有 784 个神经元的单个密集层,对应于 28x28 灰度输出图像。sigmoid 激活函数用于比较编码器输入与解码器输出。
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
# input layer
input_img = Input(shape=(784,))
# autoencoder
encoding_dim = 32
encoded = Dense(encoding_dim, activation='relu')(input_img)
encoded_input = Input(shape=(encoding_dim,))
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
decoder_layer = autoencoder.layers[-1]
decoder = Model(encoded_input, decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
我们将使用MNIST数据集来进行训练和测试,首先我们使用如下对本对其进行噪声加持以及一些预处理。
import matplotlib.pyplot as plt
import random
%matplotlib inline
# get MNIST images, clean and with noise
def get_mnist(noise_factor=0.5):
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
return x_train, x_test, x_train_noisy, x_test_noisy, y_train, y_test
x_train, x_test, x_train_noisy, x_test_noisy, y_train, y_test = get_mnist()
# plot n random digits
# use labels to specify which digits to plot
def plot_mnist(x, y, n=10, randomly=False, labels=[]):
plt.figure(figsize=(20, 2))
if len(labels)>0:
x = x[np.isin(y, labels)]
for i in range(1,n,1):
ax = plt.subplot(1, n, i)
if randomly:
j = random.randint(0,x.shape[0])
else:
j = i
plt.imshow(x[j].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
plot_mnist(x_test_noisy, y_test, randomly=True)

虽然我们肉眼仍可以识别出来数字,但已经非常不清晰了。因此,我们希望使用自动编码器来进行图像去噪。我们通过在使用噪声数字作为输入并使用原始去噪数字作为目标的同时拟合自动编码器超过 100 个 epochs 来做到这一点。
因此,自动编码器将最小化噪声图像和干净图像之间的差异。通过这样做,它将学习如何从任何看不见的手写数字中去除噪音 (这些数字是由类似的噪音产生的) 。
# flatten the 28x28 images into vectors of size 784.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
x_train_noisy = x_train_noisy.reshape((len(x_train_noisy), np.prod(x_train_noisy.shape[1:])))
x_test_noisy = x_test_noisy.reshape((len(x_test_noisy), np.prod(x_test_noisy.shape[1:])))
#training
history = autoencoder.fit(x_train_noisy, x_train,
epochs=100,
batch_size=128,
shuffle=True,
validation_data=(x_test_noisy, x_test))
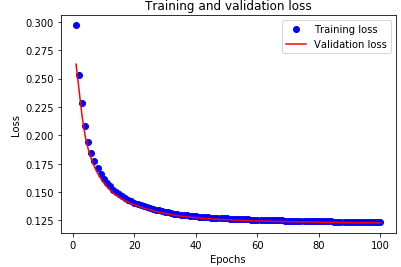
# plot training performance
def plot_training_loss(history):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plot_training_loss(history)
如何用自动编码器降噪
现在我们可以用经过训练的自动编码器来对图像进行去噪了。
# plot de-noised images
def plot_mnist_predict(x_test, x_test_noisy, autoencoder, y_test, labels=[]):
if len(labels)>0:
x_test = x_test[np.isin(y_test, labels)]
x_test_noisy = x_test_noisy[np.isin(y_test, labels)]
decoded_imgs = autoencoder.predict(x_test)
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return decoded_imgs, x_test
decoded_imgs_test, x_test_new = plot_mnist_predict(x_test, x_test_noisy, autoencoder, y_test)

总的来说,噪音消除得非常好。输入图像上人工引入的白点已从清理图像中消失。
但去噪对信息质量也有不利影响,重建的数字有点模糊。解码器增加了一些原始图像中没有的特征,例如下面的第8和第9位数字几乎无法识别。
总结
在本文中,我描述了一种图像去噪技术,并附有关于如何使用 Python 构建自动编码器的实用指南。放射科医生通常使用自动编码器对 MRI、US、X 射线或皮肤病变图像进行去噪。这些自动编码器在大型数据集上进行了训练,例如印第安纳大学的胸部 X 射线数据库,其中包含 7470 幅胸部 X 射线图像。去噪自编码器可以用卷积层来增强,以产生更有效的结果。
· END ·
HAPPY LIFE
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









