







1\最准确的策略涉及使用 TCB 和 TCW 组件的 LTTC 拟合图像。众所周知,TCB 和 TCW 都是区分林地和非林地覆盖的合适指标(Frazier 等人,2015 年)。茂密的森林群落和较小程度的灌木地的广泛特征是较高的 TCW(由于下层的阴影而增加了保持水分的能力)和较低的 TCB 值(由于表面质地较粗糙,朗伯阴影降低了反照率)。与开放式看台相比(Healey 等人,2005 年)。包括 TCG 在内的模型的性能通常很差,但 TCG 被认为是森林群落之间结构差异(草、灌木或树木)的弱驱动因素(弗雷泽等人,2015 年;Pickell 等人,2016 年)。在某个生物量密度或叶面积的阈值之上,绿色相关指数无法捕捉植被群落之间的显着差异(Pickell 等人,2016 年;Tanase 等人,2011 年)。通过 TCA 结合 TCG 和 TCB 的模型也没有提供更好的结果。TCA 是像素中植被比例的间接度量;TCA 越高,植被覆盖度越高(Gómez 等人,2012 年)。由于它主要是指植被覆盖,因此将草地与其他植被覆盖区分开来的判别力较低。
1、红光波段7*7窗口的建模精度最高,主要是由于较大的运算窗口致使像素间的差异性被放大,从而导致建模精度较高。
充分利用了不同数据源的优势,在不同空间尺度(区域)进行森林参数反演。
考虑到不同生态分区气候及植被的差异,综合考虑了不同生态分区以及不同森林类型的星载激光雷达数据进行随机森林模型参数优化以及模型训练。
不同生态分区的覆盖面积不同,包含的数据量差异较大,导致有些区域的遥感影像特征不能准确反映生态分区内的植被生长状况。不同生态区的RF模型更能够代表对应生态区的植被生长状况,从而使得模型精度有了一定程度的提高
1、尽管大量图像特征与森林属性具有相当好的相关性,但图像特征之间的高度相关性使得它们在估计中的使用变得复杂。添加一些具有高互相关性的图像特征并不能改善估计的结果,因为附加的特征包含很少或没有进一步的信息。尽管在某些估计任务中使用大量光谱特征可能是有益的,但通常情况并非如此。如果每个特征的性能都不是先验的,那么它们就不能以最佳方式加权,并且估计误差实际上可能会随着使用的特征数量的增加而增加。使用可以为特征生成最佳权重和/或能够为实际分析选择性能最佳子集的技术,可以避免这个问题。我们选择了后一种替代方案并进行了分析,哪些特征对估计精度有很大贡献,以及稳健估计结果所需的适当特征数量是多少。
特征选择是**作为顺序前向选择进行的。**在该过程的第一阶段,选择了给出最低 RMSE 的特征。后来该过程被迭代,并且在每次迭代期间,具有已选择特征的最佳 RMSE 的特征被添加到所选特征集中。使用变量检查所选特征对估计精度的影响:DBH、高度、基底面积和体积。
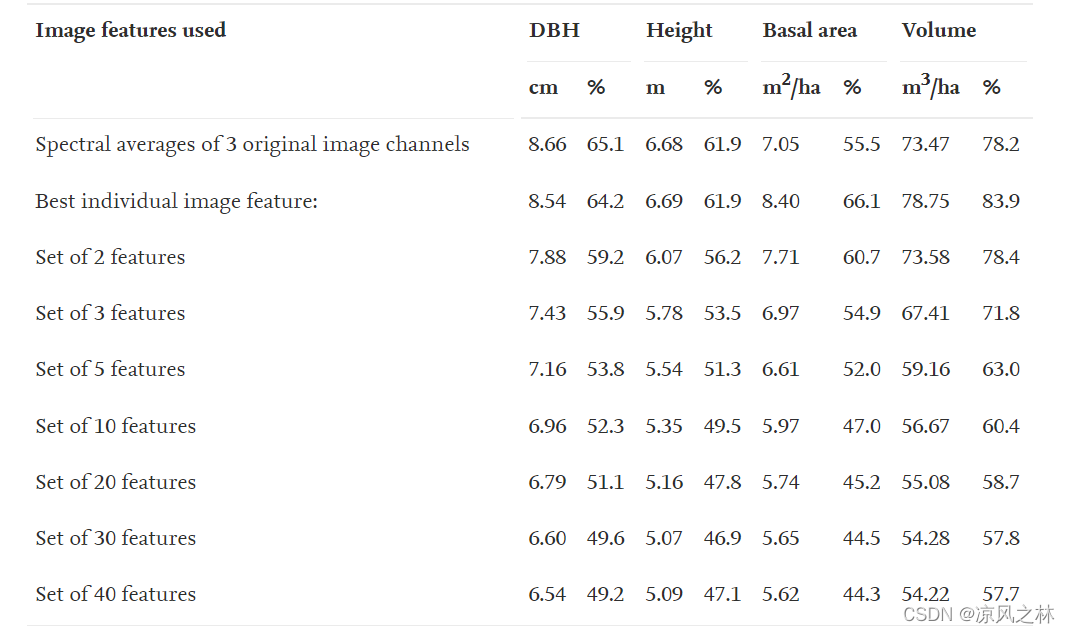
添加更多图像特征明显提高了估计的准确性,直到所选特征的数量达到大约 10 个,之后在估计过程中添加更多特征几乎没有提高估计精度。将图像特征的数量从 10 个增加到 20 个并没有带来显着的改进,之后几乎没有任何改进。通常,基于灰度共生矩阵的图像特征在所选特征中被广泛表示。由于这些通常彼此高度相关,当添加更多特征时,估计精度自然会很快达到饱和点。具有不同图像特征集的森林估计的 RMSE 值显示在表 5。
表 5。使用不同图像特征组合的 k-nn 方法估计的森林属性的均方根误差(RMSE) 和相对 RMSE (%)
2、光谱指数是经验性的,相对简单,并提供遥感辐射指数和 LAI 之间基于回归的关系。经验光谱指数的应用是一种可访问的研究技术,大量文献涵盖了一系列不同传感器的各种技术(Tucker 1977;Asrar 等人 1984 年;Running 等人 1986 年;Peterson 等人 1987 年;Curran 和 Williamson 1987;Baret 等人 1988;Spanner 等人 1990;Gong 等人 1992;Price 1993;Spanner 等人 1994;Wulder 等人 1996a)。在这项研究中,我们使用经验光谱指数来评估植被指数和纹理在 LAI 估计中的信息含量。
光谱指数是经验测量,通常通过回归分析,我们从中寻找遥感辐射或反射率与 LAI 之间的关系。植被指数,例如归一化差异植被指数 (NDVI),可被视为场景植被含量的替代指标,并试图将遥感数据与植被的物理测量值联系起来,例如 LAI ( Wulder et al. 1996a))。从植被指数估计 LAI 的一个困难是 LAI 和 NDVI 之间的渐近关系,这导致 LAI 值大于大约 3 时 NDVI 值的变化有限(Asrar 等人 1984;Running 等人 1986;Franklin 1986;Baret 等人al. 1988 年;斯潘纳等人。1990 年;巴雷特和盖约 1991 年;史密斯等人。1991;斯潘纳等人。1994 年)。植被指数值范围有限,因为是从只能查看林分水平表达的远程平台得出的。垂直结构与树高分布有关,水平分布与树木的林分密度和空间分布有关(St-Onge 和 Cavayas 1995)。随着林分的垂直结构变得更加复杂,LAI 值增加,植被重叠量也增加,导致难以从天底观测遥感平台测量的变化。(因此LAI可能与森林冠层高度密切相关,即森林高度越高,森林的垂直结构越复杂,植被叶片的重叠量也增加,导致LAI的变化),因此,具有不同植被组成和结构的林分可能由于相似的水平表达式而具有相似的植被指数值(Wulder 等人 1996a)。观察发现,低于 3 的 LAI 表明来自光谱响应的估计非常强(Gong et al. 1992);因此,在扩展从光谱响应中以较高值估计 LAI 的能力方面可以做出的任何改进都是有价值的。
还必须考虑支架水平表达的空间分辨率依赖性。随着图像空间分辨率的降低,像素间变化量也会减少,从而提供更少的结构信息。相反,图像范围随着空间分辨率的增加而减小,从而导致覆盖较小地面区域的详细信息。因此,在本研究中使用高空间分辨率机载传感器数据将导致与之前使用低分辨率数据(例如 Landsat TM ( Franklin 1986 ) 发现的关系不同))。将改变树冠关闭的效果;低密度的树冠将不再具有下层的特征,而是由实际感知下层的像素表示。正如低分辨率数据林分数字被下层或土壤改变一样,高分辨率林分数据的纹理也会改变。由于低分辨率图像中的像素值通过像素中各种对象的组合来缓和(Cohen 等人,1995 年),因此具有多个像素来表示对象的高分辨率图像具有更大范围的纹理方差受到较少抑制的信息(Strahler 等人 1986 年;Woodcock 和 Strahler 1987 年)。
森林条件的动态特性限制了从单一信息源(例如 NDVI)预测 LAI 的能力。由于 NDVI 来自图像光谱值,因此任何森林结构变异性都将与计算的 NDVI 值相关。例如,树冠闭合、阴影或林分密度的差异等因素可能导致林分结构明显不同,但仍可能由基于红色与红外光谱数据比率的相同 NDVI 值表示。内部林分条件,例如相互遮蔽,实际上会导致 NDVI 随着 LAI 的增加而下降。可以在对高空间分辨率图像计算的图像纹理测量中检测内部立式阴影条件。当光谱信息和 LAI 之间的关系强度减弱时,纹理可用于提供结构信息。在数字图像处理的背景下,纹理是图像色调的空间可变性,它描述了表面覆盖元素之间的关系。因此,纹理包含结构信息,因为纹理的变化与森林植被空间分布的变化有关。森林要素或森林结构的地上组织(因为纹理的变化与森林植被空间分布的变化有关。森林要素或森林结构的地上组织,森林要素或森林结构的地上组织(Spurr and Barnes 1980 ) 相应地以纹理表示。纹理测量是对图像数据的补充,并提供了一个可访问的、低成本的附加信息源。纹理还被证明能够将结构信息添加到光谱导出的植被指数中,并改进 LAI 的估计值(Wulder 等人 1996a),特别是对于大于 3 的 LAI 值(Wulder 等人 1996b)。
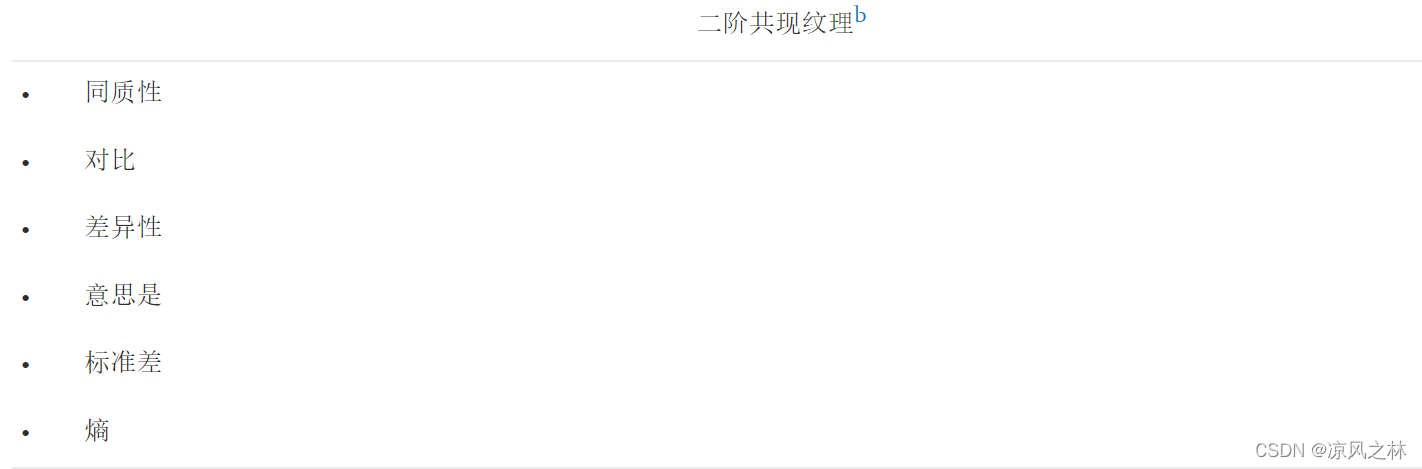
图像纹理可以通过各种表征相邻像素之间关系的统计数据来关联。出于本研究的目的,可以为每个像素计算的度量,其表征区域内或沿样带的光谱响应,被认为是纹理度量。一阶纹理源自用作低通或低频空间滤波器的自定义滤波器(Haralick 1986),它计算通过图像的固定移动窗口的中心单元的代表性统计值。固定窗口的中心像素被赋予一个新值来表示该像素的局部区域。涉及二阶统计计算的空间域中局部属性的统计分布由灰度共生矩阵和相关的统计数据集表示。灰度共生矩阵 (GLCM) 可以定义为相对频率矩阵,其中两个相邻像素出现在图像上,由用户定义的距离和角度隔开(Haralick et al. 1973)。纹理值是通过计算特定距离和角度的统计数据来确定的,这些统计数据基于这些值如何相互关联。例如,同质性、对比度和熵是与图像的特定纹理特征相关的度量。相异性、均值和标准差表征了图像中出现的灰度转换的复杂性和性质(Haralick 1979)。即使这些特征包含有关图像纹理特征的信息,通常也很难确定这些特征中的每一个代表了哪个特定的纹理特征。
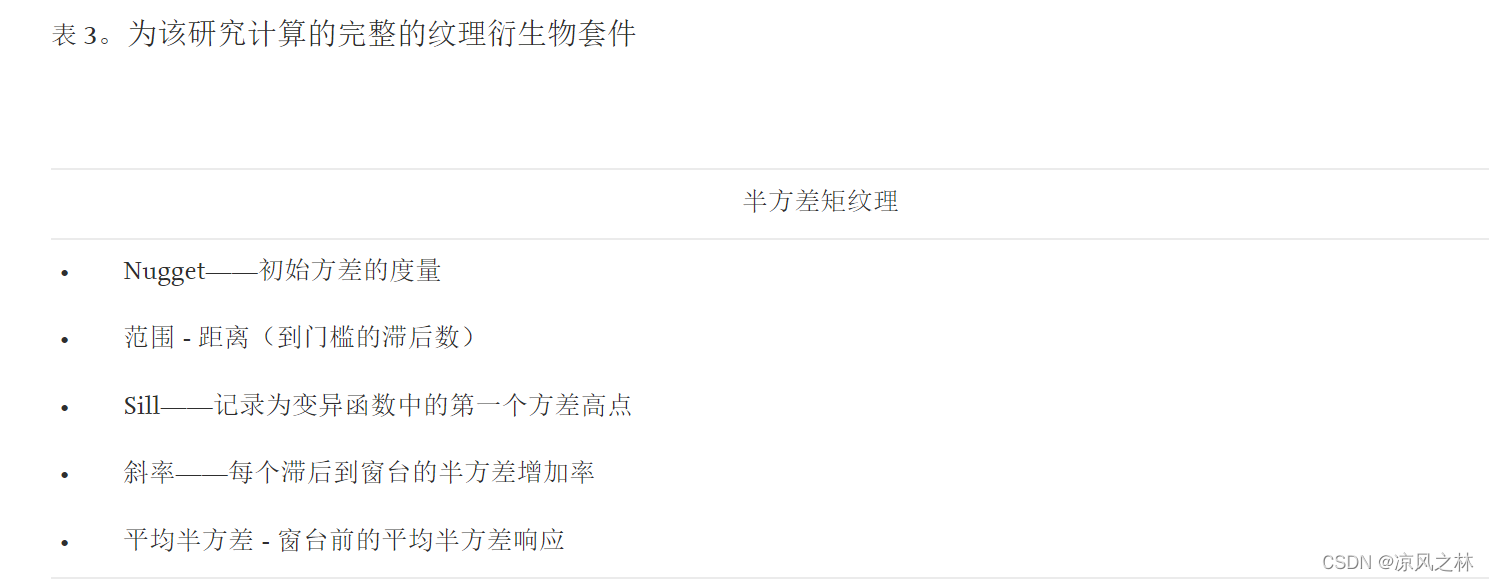
半方差矩纹理 (SMT)
变异函数描述了给定数据集变化的幅度、空间尺度和一般形式(Matheron 1963)。半变异函数是空间可变性的图形表示,并提供了一种测量连续变化现象的空间依赖性的方法。图像半方差已被证明可以表示图像结构信息。1995 年圣奥格和卡瓦亚斯 1997 年圣奥格和卡瓦亚斯已经利用方向变异函数中固有的信息作为估计参数的方法,例如密度、树冠直径、树冠闭合和林分高度,这些参数都与森林结构和 LAI 有关。
这里提出并证明了方向变差函数可用于生成离散值以表示图像空间可变性。半方差矩纹理 (SMT) 值是从半方差响应曲线中提取的,该曲线是沿 0° 角的 35 像素样带为每个图像像素计算的。计算半方差响应曲线的这些矩以创建与在变异函数上发现的重要信息部分相关的图像。基于场景元素的组织,以数字表示的实际图像特征产生半方差矩值。通过变差函数的计算提取的五个不同的SMT值可以关联不同的场景特征。计算的空间指标,由于色调的空间变异性的表征,作为图像纹理的替代测量值的是块金、窗台、范围、斜率和平均半方差。块金表示初始方差,基台表示最大半方差,范围与到达基台所需的滞后数有关,平均半方差表示块金和基台之间方差的平均幅度,变异函数的斜率表示块金和基台之间的方差变化率,由基台除以范围计算得出。这些值与典型的半方差响应形式有关,例如经典、周期性、非空间、周期性经典、多频和水平形式。由于 SMT 值是根据沿像素值的横断面计算的变异函数计算的,因此对于大多数纹理测量而言,没有关于窗口大小的潜在主观决定。
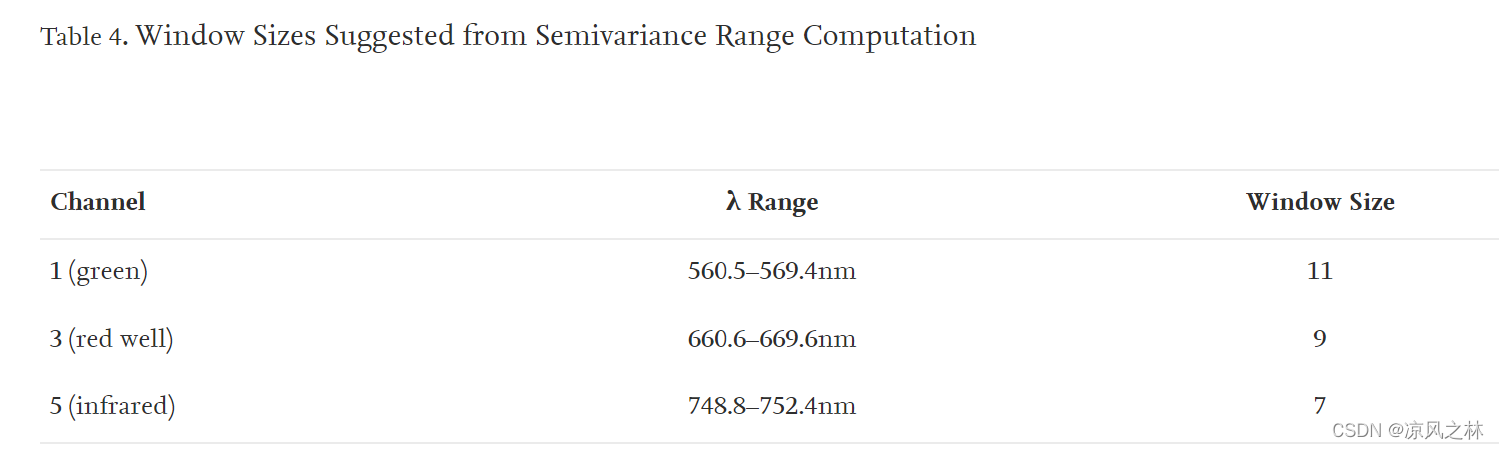
计算了红色和红外通道的纹理导数(表 3)。在处理遥感图像以评估纹理时,需要解决各种因素,例如要采用的算法、将评估哪些通道以及用于分析的适当量化级别。在二阶纹理测量的情况下,例如灰度共生矩阵 (GLCM),还需要解决用于比较值的角度、方向和步长(Peddle 和 Franklin 1991)。由于包含的方差量,为分析选择的窗口大小会影响结果纹理。计算数字图像半方差以预测用于处理一阶和二阶纹理导数的最佳拟合窗口大小(Franklin et al. 1996)。与红外通道相比,可见通道决定了更大的窗口,这可能与可见通道相比红外通道的范围更小和方差减小有关(表 4)。
在计算出的 48 个潜在纹理变量中,通过 16 个纹理导数(表 3 )的三个光谱通道(绿色、红色和红外)计算,分析中显示了 12 个。由于信息与其他变量的多重共线性或互补性,纹理变量被从分析中删除。由于性能比红色和红外通道弱,绿色纹理导数被从分析中删除。

在第一组中,根据构成一个对象的所有像素的值计算每个 VI 的平均值和 SD 值,显示与植被状况、作物结构、残留物含量、土壤背景等相关的信息。SD 值还可以表示对象内像素值的局部可变性程度。在第二组中,基于 GLCM 的纹理特征是通过确定具有强度(所考虑的波段的灰度级)值i的像素与具有值j的像素在特定空间关系中出现的频率来计算的(定义, 2007 年)。在该组中,特征同质性、对比度、相异性、熵、角二阶矩、矩阵均值、矩阵 SD 和相关性进行了评估。纹理提供了有关对象属性的补充信息,这可能有助于区分异质农田(Pacifici 等,2009),尽管它们具有计算成本高的缺点。第三组是由基于子对象分析的其他类型纹理特征形成的,在这种情况下,我们定义了一个新特征来测量具有特定 VI 阈值下的像素值的子对象的相对面积。无论 VI 及其物理上可解释的阈值是否正确选择,此新功能都可能提供比 GLCM 参数更易于理解的纹理测量。在该组中,我们在对缩小的区域进行初步研究后选择了 10 个 VI,以减少后续分析中的计算时间。其他基于几何属性的对象特征,如形状、周长、形状指数或密度,没有被考虑,因为它们在植被识别中没有一致的贡献(Ke et al., 2010,Laliberte 等人,2007 年)。
NDVI 值低于 0.25 与缺乏绿色植被的田地有关
光谱特征形成了决策树框架,对模型贡献了大约 90%。还需要一些纹理特征来区分具有相似光谱响应的作物田地,主要是永久性作物(果园、葡萄园、苜蓿和草甸)。
此外,我们还询问了图像纹理与基于激光雷达的冠层高度变化的比较,以及传感器分辨率如何影响图像纹理的解释能力。
30 和 10 m 分辨率纹理指标都与基于激光雷达的冠层高度变化密切相关(|r| = 0.64 和 0.80,分别)。纹理与基于田间的指标适度相关,包括植被高度和树干直径的变异性,以及树叶高度多样性(范围|r| = 0.31-0.52)。卫星图像纹理表征了结构和组成植被异质性的多个特征,其表现优于基于激光雷达的冠层高度变异性和基于野外的植被测量。我们的研究是第一项将图像纹理与植被异质性的特定组成部分以及跨多个生态区域和空间分辨率的鸟类丰富度直接联系起来的研究,从而揭示了图像纹理与生物多样性之间强相关性背后的栖息地特征。
植被结构是指植物的三维结构,如株高、密度和垂直层的分布,而植被组成则描述了植物物种或主要生命形式的特性和多样性(Noss,1990)。植被的结构、其物理复杂性和排列方式是物种多样性的重要驱动因素。植被异质性难以量化,在广泛的领域对其进行测量是一项挑战,需要在不同方法之间进行权衡。基于现场的方法直接量化植物结构和组成的异质性,但在时间和空间上的覆盖范围有限(Rocchini 等人,2010 年)。激光雷达成像是估计植被结构的高分辨率替代方案,但获取成本高,空间和时间覆盖范围有限(Simonson 等人,2014 年),通常不包括较低的植被层,并且提供的成分信息很少。基于卫星的遥感数据通常仅测量结构和成分异质性的代理,但提供大面积的连续测量(Rocchini 等,2016)并且可以量化和绘制对生物多样性很重要的植被特征(Pettorelli 等人,2016 年;Wang 和 Gamon,2019 年)。因此,这些不同类型的植被数据具有不同的优点和缺点,并且在组合使用时最强大和信息最丰富(Rhodes 等人,2015 年;Rocchini 等人,2016 年)。
图像纹理量化图像像素值的光谱和空间变化,从而传达有关图像特征的光谱和空间异质性的信息(Haralick 等人,1973 年)。基于生产力测量的纹理指标,包括归一化差异和增强植被指数(NDVI、EVI),提供了有关植被结构和组成的空间模式的重要信息(St-Louis 等人,2009 年;Campos 等人,2018 年))。事实上,不同分辨率的卫星图像的纹理分析已被用于有效地表征一系列栖息地类型的结构和组成植被异质性模式,例如针叶林的演替阶段(30 m;Jakubauskas,1997),林分结构指标在针叶林(1-3 m;Kayitakire 等人,2006 年;Ozdemir 和 Karnieli,2011 年)中,草原-稀树草原-林地马赛克中的叶子高度多样性(30 m;Wood 等人,2012 年),以及植物的异质性干燥林地(30 m;Campos et al., 2018)和草地(15-20 m;Briggs and Nellis, 1991;Guo et al., 2004 )的物种组成和结构).
虽然图像纹理与植被异质性的特定特征有关(例如,Ozdemir 和 Karnieli,2011 年;Wood 等人,2012 年),或者对于鸟类丰富度的模式(见上文),先前的研究没有将纹理与多个栖息地类型和生态区域的植被特征和鸟类丰富度数据直接联系起来。此外,需要确定最能表征与生物多样性相关的植被异质性模式的图像纹理的空间分辨率(Bar-Massada 等人,2012 年)。
我们从每幅图像的近红外、红色和蓝色波段计算 EVI,并选择 EVI 而不是 NDVI,因为它不太可能在高生物量下饱和并且对大气条件和土壤亮度不太敏感(Huete 等,2002)。并从 3 月至 8 月之间的所有可用图像中计算每个像素的 EVI 中值,作为生长季节植被绿度的衡量标准(Creech 等人,2016)。因为负值在我们的中值 EVI 组合中很少见,并且通常表示缺乏植被(例如,岩石、裸露的地面),我们将负值设置为零并将 EVI 值线性重新调整为无符号 8 位整数
在图像纹理分析中,纹理值是根据给定分析单元内所有像素的光谱值(或“灰度级”)计算的(Hall-Beyer,2017 年)。一阶纹理度量是该处理范围内像素灰度的统计汇总(例如,均值、方差),而二阶纹理度量来自灰度共现矩阵(Haralick 等人,1973) . 共现矩阵包含相邻像素灰度级在分析单元内共现的归一化频率,从而反映了相邻像素之间的空间模式和关系(Hall-Beyer,2017)。我们使用glcmTexture计算了一阶标准差和 13 个二阶纹理度量GEE 中的函数(Haralick 等人,1973 年,Conners 等人,1984 年;计算的 14 种纹理列表见表 1)。
为了研究图像纹理可以很好地捕捉植被异质性的哪些特征,**我们首先使用 Spearman 相关系数评估了 30 和 10 m 纹理指标、激光雷达冠层高度变异性和基于场的指标之间的关系。**然后,在对预测变量进行中心化和标准化后,我们在鸟类丰富度的单变量模型中测试了每组环境变量。我们参数化线性回归模型,将环境预测因子与所有物种以及森林和草原专家的丰富度联系起来,因为我们的数据是正态分布的(结果未显示)。唯一的例外是灌木丛专业丰富度,它更符合泊松分布,但我们发现该鸟组的泊松广义线性模型输出中排名靠前的预测变量与线性模型的预测变量一致(表 S3)。因此,为了允许跨鸟类组进行比较,我们对所有评估的鸟类组应用线性回归。在我们对栖息地专家的分析中,我们将分析限制在以首选栖息地类型(即森林、草地、灌木丛)为主的采样地块上,以关注对每个栖息地组很重要的植被指标,并根据百分比确定土地覆盖优势NLCD 课程的封面。
最后,我们拟合了鸟类丰富度的多变量模型,其中包括在单变量模型中评估的每一类变量中具有最高解释力的六个预测变量(见结果,第 3.3 节))。我们对多元模型的目标不是开发具有最高可能预测能力的模型,而是将纹理度量的相对性能与一组代表性的、更常用的植被异质性度量进行比较。我们生成了具有六个预测变量和一个截距的所有可能子集的线性模型,并分别拟合了具有 30 和 10 m 分辨率纹理度量的模型。这导致评估的每组鸟类共有 128 个模型:所有物种、森林专家、草地专家和灌木丛专家(总共 512 个模型)。我们根据贝叶斯信息准则 (BIC) 选择顶级模型,它惩罚过度参数化模型以避免过度拟合 ( Brewer et al., 2016 ),但有时会导致模型过度简化 (伯纳姆和安德森,2004 年)。我们在运行多变量模型之前检查了预测变量之间的相关性(图 S2、S3),并计算了排名靠前的模型中每个预测变量的方差膨胀因子(VIF)作为多重共线性的二次检查,使用 VIF > 4 的阈值来消除多重共线性引起的变量(Booth 等人,1994 年)。模型选择方法只能衡量模型的相对质量,因此我们还计算了调整后的决定系数(R 2 adj),以确定鸟类丰富度的方差有多少被顶级模型解释(Guthery et al., 2005))。我们通过比较标准化回归系数作为效应大小的度量来评估预测变量对鸟类丰富度的相对影响,并对排名靠前的模型进行分层分区分析,以计算每个预测变量对总解释方差的独立和联合贡献(Chevan 和 Sutherland , 1991 年)。每个预测变量的独立贡献表示由该预测变量唯一解释的方差,而由于多重共线性,联合贡献无法与其他预测变量区分开来(Mac Nally,2000)。
我们观察到许多纹理度量之间的强相关性,特别是在量化图像异质性相似元素的纹理组之间。例如,图像对比度(即对比度、相异性、同质性)和图像有序性(即均匀性、熵、差异熵)的纹理度量之间的 Spearman 相关系数范围为 | r | = 0.92–1.0(图 S4、S5)。一般来说,来自描述性统计组的纹理度量(即相关性,相关性的信息度量)与来自对比度和有序纹理组的度量的相关性较低。
我们发现纹理与植被结构复杂性的测量密切相关,但也提供了有关植物组成异质性的信息。我们的研究结果很重要,因为遥感数据云计算的进步增加了卫星图像的可访问性并减少了图像纹理计算的处理时间,使得在大陆尺度的生态应用中包含 10-30 m 分辨率的图像纹理成为可能。
在几种纹理算法中,选择了两类纹理测量,以测试它们使用 AVNIR-2 数据进行生物量估计的潜力(表 4) 因为这些是基本的、广泛使用的和简单的算法。第一个是灰度共生矩阵 (GLCM) ( Haralick et al., 1973 ) 以及一些基于灰度差矢量 (GLDV) 的纹理测量。第二个是Unser (1986)提出的和差直方图,作为通常使用的共现矩阵的替代方案。识别合适的纹理还涉及移动窗口大小的选择(Chen et al., 2004 , Lu, 2005 )。小窗口尺寸夸大了窗口内的差异,但保留了高空间分辨率,而大窗口可能由于纹理变化的过度平滑而无法有效地提取纹理信息。所用数据的分辨率很高(10 m),类似于 树冠的 8-10 m 平均大小。**由于森林树冠是封闭的,这意味着树冠和阴影的部分可能在某些像素中合并(因此平均),但在其他像素中保持离散。由于森林的反复出现的斑块大小主要由地形决定,大约为 100-200 m,我们选择中小型窗口大小(9 * 9 和更低)在这些斑块内进行操作。**为处理指定了四个检测方向(0 0、45 0、90 0和135 0)。


在多元回归建模中,当使用大量自变量时,可能会出现多重共线性和过度拟合等困难,因为这些变量可能彼此高度相关。为了避免过度拟合问题,以及确保找到最佳拟合模型,计算了三个常见的统计参数,即调整后的 r 2、RMSE 和 p 水平(用于模型)。另外七个统计参数,如 Beta 系数 (B)、Std。B 的误差、p 级、容差 (Tol = Tolerance = 1 − R x 2 )、方差膨胀因子 ( ) 和条件指数 () 计算以测试截距适应度和多重共线性效应。为了表示多重共线性问题,公差值小于 0.10 ( Belsley, 1990 ),VIF 值大于 10 ( Belsley, 1990 , Douglas et al., 2006 , Hyde et al., 2007 , Kutner et al., 2005 ) , 并且条件指数大于 30 ( Belsley, 1990 , Douglas et al., 2006 ) 被用作决定因素。
发现田间生物量与 AVNIR-2 数据的光谱特征之间的关系对于所有光谱波段都很差,尽管使用波段 4(近红外)观察到更强的相关性(调整 r 2 = 0.48 和 RMSE = 71 t/ha ) 和波段 2(绿色)(调整后的 r 2 = 0.13 和 RMSE = 93 t/ha)。这一仅中等的结果与许多其他研究一致( Foody 等人,2001 年, Salvador 和 Pons,1998 年, Steininger,2000 年, Thenkabail 等人,2004 年)。
总体而言,简单带比的性能优于任何单个光谱带,使用比率 3/4 和 1/4 获得的最高调整 r 2为 0.58(RMSE = 63 t/ha)。测试的 10 个植被指数的结果与简单波段比率的结果相似,基于坡度的指数结果最好,这是红色和 NIR 波段的基本不同组合。RVI 代表了现场数据的总体最高可变性(调整后的 r² = 0.58),但其他如NDVI排在第 5 位(调整后的 r² = 0.57 和 RMSE = 64 t/ha) 给出了类似的性能。这种对单波段的改进归因于绿色植被的光谱贡献增强,同时最小化了土壤背景、太阳角度、传感器视角、衰老植被和大气的贡献(Huete 等人,1985 年,Tucker,1979 年)
然而,尽管使用简单波段比和植被指数获得的模型的 58% 变异性(调整后的 r 2 = 0.58 和 RMSE = 63 t/ha)不如Zheng 等人获得的 r² = 0.82 高。(2004 年)在结构简单的温带森林中,它大大高于以前在热带森林中的结果(Foody 等人,2001 年,Lu,2005 年,Rahman 等人,2005 年,Steininger,2000 年)。例如, Foody 等人使用分辨率为 30 m 的Landsat 。(2001) 对于生物量高达 400 吨/公顷的热带森林,使用 6 个常规植被指数的 230 个排列发现了不显着的关系,Rahman 等人。(2005)的 r 2为 0.47。
纹理测量显示使用 ANVIR-2 数据估计生物量有显着改善。波段 4 和 3 的纹理参数分别获得最佳(调整后的 r 2 = 0.72 和 RMSE = 51 t/ha)(表 5中的模型 4 )和最差的性能(调整后的 r 2 = 0.31 和 RMSE = 83 t/ha) (表5中的模型3 )。带 4 的结果比没有纹理的原始带好得多(调整后的 r 2 = 0.48 和 RMSE = 71 t/ha)(图 3a)。
在多元回归模型(表 5中的模型 5和图 3a)中一起使用所有波段的纹理参数实现了进一步的改进。获得了大约 76% 的田间生物量变异性(调整后的 r 2 = 0.76 和 RMSE = 46 t/ha)。此外,重要的是要注意模型和所有变量都是显着的,并且没有观察到多重共线性效应。一般来说,窗口大小 7 × 7 和 9 × 9 更成功,这可能是由于它们对每个像素内树冠和阴影比例的像素间差异更敏感(Fuchs et al., 2009 , Lu, 2005)),**因为这些差异会被更大的窗口平均化(**Franklin et al., 2000)。
Lu (2005) (r² = 0.49) 在热带森林和Fuchs 等人也注意到使用光学数据的纹理参数改进生物量估计。(2009) (r 2 = 0.63) 在温带森林中,因为纹理可以代表林分结构的差异,因为它对冠层阴影的空间方面很敏感。尽管我们使用所有波段的纹理参数获得了一个更好的模型,与之前在热带和温带森林的研究相比,性能有了很大提高(同上),但该模型仍然只能解释 76% 的田间生物量变化。此外,46 t/ha 的 RMSE 仍然很大,因为一些高生物量地块距离拟合线还很远(图 4一)。因此,由于尚未获得用于生物量估计的稳健模型,研究人员决定进一步探索使用纹理参数的简单比率,以便结合纹理处理和波段比率。
一般来说,生物量估计是使用各个波段的纹理参数的比率来改进的(表 6)。最高调整 r 2为 0.88(RMSE = 32 t/ha)是从所有组合的纹理比率中获得的(表 6中的模型 7和图3b)。与使用原始光谱带(调整后的 r 2 = 0.48 和 RMSE = 71 吨/公顷)、简单比率(调整后的 r 2 = 0.58 和 RMSE = 63 吨/公顷)获得的最佳结果相比,这是生物量估算的显着改进,选定的植被指数(调整 r 2 = 0.58 和 RMSE = 63 t/ha)和纹理参数模型(调整后的 r 2 = 0.76 和 RMSE = 46 t/ha)。模型和所有变量均显着,多重共线性效应不明显。模型预测和观察到的生物量之间的关系也显示出与回归线的良好拟合(图 4 b),除了一个远离回归线的高生物量地块,其 RMSE 为 32 吨/公顷。虽然这个 RMSE 似乎很大,但考虑到该研究区域的高生物量范围(从 52 吨/公顷到 530 吨/公顷),这个误差相对较小。
在用于研究 ANVIR-2 数据对生物量估计的潜力的四种不同数据处理技术中,从单波段光谱反射率(来自 NIR 的 0.48)、简单波段比(来自红色/NIR 的 0.58 )获得的最佳结果(调整后的 r 2 )或蓝色/NIR)和植被指数(来自 RVI 的 0.58)不是很有希望,最佳拟合模型仅代表生物量变异性的 58%(调整后的 r 2 = 0.58 和 RMSE = 63 t/ha)。使用单波段的纹理参数观察到显着改善(调整后的 r 2 = 0.72 和 RMSE = 51 t/ha) 和所有波段的纹理参数一起(调整后的 r 2 = 0.76 和 RMSE = 46 t /ha),当简单比率为模型中使用了纹理参数。我们将这种高性能归功于所应用的处理技术和所用数据的高分辨率。
使用光谱反射波段获得的中等结果可能是由于该研究区域的田间生物量水平非常高,尽管来自单个叶层的海绵状叶肉的近红外反射率最初随着叶盖的增加而增加,因为额外的叶层是添加到树冠上,这些增加不会持续(Jensen,2000)。同时,随着树冠的成熟,形成更多层并增加复杂性,阴影充当入射能量的光谱陷阱,并减少返回传感器的辐射量(Moran 等人,1994 年)。
在这项研究中,我们测试了简单光谱带比和一些常用植被指数的六种组合,以研究使用较少植被指数的可能性,因为有许多可用的植被指数,但没有关于它们在不同情况下的潜力的指南。结果表明,无论是简单的光谱带比(如 red/NIR),还是复杂的植被指数(如NDVI或 MSAVI 或 RVI)都比单一的光谱带表现更好,但简单带比和复杂植被指数之间的性能差异是不发音。
主要迹象是,当树冠饱满且森林连续时,基于坡度的植被指数(如 NDVI)和基于距离的植被指数(如 PVI 或 MSAVI)都不会比简单的波段比更有用:这一发现支持其他研究人员在热带森林中工作(Foody 等人,2001 年,Lu,2005 年)。其原因已被广泛讨论(Foody et al., 2001 , Le Toan et al., 1992 , Moran et al., 1994 , Sader et al., 1989 , Thenkabail et al., 2000),我们总结了4.5节的要点. 在模型中同时使用所有光谱带和所有植被指数可以提高生物量估计的性能,但是,两种模型都违反了不相关自变量的假设并导致多重共线性效应(CI大于30)。
使用模型中所有光谱带的纹理参数一起改进了生物量估计,几乎 76% 的田间生物量变异性(调整后的 r 2 = 0.76 和 RMSE = 46 t/ha)。这种使用纹理的显着改进并非完全出乎意料,因为许多研究人员 ( Fuchs et al., 2009 , Lu, 2005 ) 也观察到使用光学数据进行纹理测量的结果更好,但考虑到该研究区域的生物量水平非常高,这一结果似乎很有希望。
我们使用简单的纹理参数比率实现了更高的模型性能(调整后的 r 2 = 0.88 和 RMSE = 32 t/ha),这在之前的生物量估计中没有报道过。我们知道,纹理测量有可能通过简化冠层结构(Fuchs 等人,2009 年,Lu,2005 年)来改进使用光学图像的生物量估计,并且与单波段相比,波段比具有改进生物量估计的能力,通过最小化来自太阳角度、传感器视角、大气条件和冠层几何形状的贡献(Boegh 等人,2002 年,Curran,1983 年,Elvidge 和 Chen,1995 年,富兰克林,2001 年,Huete 等人,1985 年,Schowengerdt,1983 年,塔克,1979 年)。纹理参数的比率结合了两种技术(纹理测量和比率)来改进生物量估计,我们将观察到的非常显着的改进归功于两种众所周知的处理技术的组合,即纹理测量和图像比率。与以前用于生物量研究的传感器相比,这项研究获得的良好结果还归功于 AVNIR-2 的高分辨率,因为纹理更能够通过精细的空间分辨率图像定义森林结构(Boyd 和 Danson,2005 年,富兰克林等人,2000 年,海伊等人,1996 年,图米宁和佩卡里宁,2005 年)。
纹理度量提供了图像视觉特征的定量描述,例如平滑度、粗糙度、对称性、规则性等。可以使用多种纹理度量,从简单的统计数据,例如标准偏差 ( Sun and Qin, 1993 ),到傅里叶变换、分形、从灰度共现矩阵 (GLCM) 和地质统计函数派生的统计数据(Abarca-Hernández 和 Chica-Olmo,1999 年,Carr,1996 年,Lark,1996 年,Miranda 等人,1992 年,Miranda 等人等,1998)。在以前的方法中,地统计方法有一个优势,在某些情况下,覆盖类型之间的季节性状态差异对于类别区分很重要。具体来说,变差函数不仅可以针对单个图像波段(单变量单季节纹理)计算,还可以针对一组波段来描述图像不同波段之间的协方差(多变量单季节纹理)和图像之间的协方差。代表不同季节的时间序列的相同波段(多变量多季节纹理)。
本研究的目的是研究将各种单季节(例如近红外波段的变异函数)和多季节纹理测量(例如春季和夏季红外波段之间的交叉变异函数)与光谱数据相结合用于地中海土地分类的效用按像素覆盖。将这些变换应用于原始卫星传感器波段可能会增加数据的维数,这可能会由于休斯效应(Bellman,2003 )对分类器的准确性产生不利影响)。数据空间维度的这个问题可以从两个角度来解决:通过选择能够处理大量变量的稳健分类器,或者通过减少输入变量的数量,只选择信息量最大的分类器。集成学习算法已成为传统参数或机器学习算法(例如决策树、神经网络)的潜在更准确和稳健的替代方案(Chan 和 Paelinckx,2008 年,Dietterich,2000 年,Pal 和 Mather,2003 年))。这些分类器使用基本分类器组合来自训练数据的随机样本的重复多个分类。在分类器集成中,我们应用了相对新颖的随机森林分类器,因为:a)它可以有效地处理大型数据库,b)它可以运行数千个输入变量,c)**它将每个输入变量量化为一个重要性度量,**d)它对异常值和噪声,以及 e) 它在计算上比其他集成方法(例如,Boosting)**更快(**Breiman,2001,Cutler 等人,2007 年,Hastie 等人,2009 年)。
特征选择
在遥感分类中包含纹理变量可能意味着正在使用的数据集的维数会大幅增加(数百个变量),因为这些变量是通过对不同尺度(窗口大小)的图像波段应用多个函数或测量来获得的. 如此大量的数据可能超出可用软件处理它的能力。一方面,更多信息可能对分类过程有用;另一方面,输入特征数量的增加可能会引入与计算时间增加和“维度灾难”相关的额外复杂性(Bellman,2003)。数据集中的这种高维度可能会压倒与包含其他特征相关的分类准确性的预期增长。
特征选择 (FS) 是一种选择相关特征子集以构建稳健学习模型的方法(Blum 和 Langley,1997 年,Guyon 和 Elisseeff,2003 年,Saeys 等人,2007 年)。使用纹理来增强类之间可分离性的遥感研究使用不同的方法从给定卫星传感器的光谱带中计算纹理变量。因此,一些纹理变量可能高度相关或冗余( Pacifici et al., 2009)。因此**,使用大量纹理特征进行分类的逻辑目标应该是选择最相关的纹理特征。**在这种情况下,FS 通过减轻维度灾难的影响、增强泛化能力、加速学习过程和增加模型的可解释性来帮助提高分类模型的准确性。
已经为 FS 提出了许多不同的理念。FS 的一种常用方法是使用第一主成分代替原始特征(Benediktsson 和 Sveinsson,1997,Berberoglu 等,2007,Chica-Olmo 等,2004b,Zhang 等,2009 )。最近的方法是包装器,包括使用非参数算法,如分类树、神经网络和支持向量机(Bazi 和 Melgani,2006 年,De Stefano 等人,2007 年,Del Frate 等人,2005 年,Pal 和 Foody , 2010 ,于等人, 2002)。其中,我们将考虑随机森林分类器的应用,这是一种基于树集合的方法(第 4.2 节)
Breiman 在 2001 年提出了一种新的、有前途的分类器,称为随机森林 (RFs)。RF 可以处理数千个输入变量而无需删除变量,并估计变量在分类中的重要性。
随机森林是分类树的集合,其中每棵树都对输入数据的最频繁类别的分配进行一次投票(Breiman, 2001 , Guo et al., 2011 , Rodriguez-Galiano et al., 2012b)。RF在每个节点的划分中使用输入特征或预测变量的随机子集,而不是使用最佳变量,这样可以减少泛化误差。此外,为了增加树的多样性,RF 使用 bagging 或 bootstrap 聚合来使树从不同的训练数据子集中生长。Bagging 是一种用于训练数据创建的技术,它通过随机重采样原始数据集进行替换(即,不删除从输入样本中选择的数据以生成下一个子集)。使用 bagging 选择的每个子集使每个人都成长,其中包含一定比例的训练数据集。训练子集中不存在的样本作为另一个子集的一部分,称为“袋外”(OOB)。请注意,通过引导过程,从未选择的元素中为集成的每棵树形成不同的 OOB 子集。这些没有考虑用于树的训练的OOB元素可以通过树进行分类以评估性能。错误分类与OOB元素总数之间的比例有助于对可用于FS的泛化误差进行无偏估计(第 4.2.1 节)。
RF 使用基尼指数作为最佳分割选择的衡量标准,它衡量给定元素相对于其余类别的杂质(Breiman 等人,1984 年)。因此,通过使用给定的特征组合,决策树可以增长到其最大深度(没有修剪)。
为了考虑研究区域土地覆盖类别的不同空间变异模式,使用经验标准选择窗口大小。由于研究区域非常多样化并且类别呈现不同的空间模式,我们试图找到与不同尺度相关的几种窗口大小的表示。窗口应该足够大以确保获得稳健的纹理估计器。经过多次试验,计算了三种不同窗口尺寸的纹理测量值:5 × 5 (150 × 150 m)、15 × 15 (450 × 450 m) 和 31 × 31 (930 × 930 米)。最小的窗口大小提供了对具有高局部方差的最异质环境的更具代表性的描述,这些环境由小块组成,并且发生不同光谱响应的空间交替(例如,城市环境和裸露的土壤)。相反,较大的窗口尺寸可以更准确地表示大面积空间变异的通常同质模式,主要由密集的植被(如针叶树和热带作物)占据。窗口大小的选择是一个实际问题,它取决于景观的特征和图像的空间分辨率。因此,它对每个分类场景都是特定的,必须使用经验标准来解决。当图像的数字值的空间分布在主要方向(N-S、E-W、NE 和 NW)上显示各向异性时,变异函数计算的方向是另一个必须考虑的主题。为了解决选择适当方向的问题,在四个主要方向(0、45、90 和 135)上计算了 GLCM,并对四个角度进行平均以获得旋转不变性。















 2147
2147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











